flume日志收集系统常见配置
前面介绍了flume入门实例,介绍了配置netcat信源,以及memory信道,logger信宿,其实flume常见的信源信道信宿有很多,这里介绍flume常用信源的三种方式:netcat,avro,exec,信道的三种方式:memory,jdbc,file,信宿的两种方式FILE_ROLL,hdfs。理论上,这些组合在一起,可以构建十多种配置方式,这里我们就通过几个例子来展示这些配置,通过示例来了解他们的区别。
从信源类型来看,avro和netcat类似,都需要开启监听服务,而且模拟发送avro信息需要通过flume-ng命令,并且需要指定连接的主机和端口。exec这种信源,表示将一个命令执行的结果作为信源,交给flume来收集。
从信道类型来看,memory是最常用的方式,是将收集的数据缓存在内存中,但是他的可靠性不够,一旦出现故障,数据就难以恢复,而jdbc是将数据默认缓存在derby数据库中,file类型是将数据缓存在文件系统中,但是后两者的效率没有memory高。
从信宿类型来看,FILE_ROLL是将数据最终存储在文件系统中,但是大小会受到限制,因此一般是将数据存储在分布式系统如hadoop中,这里就是hdfs,指定了hdfs类型,就需要指定存储的路径。
在信源上,我们可以指定拦截器,让收集的数据更加的精确,更加的满足我们的系统分析需求。默认的拦截器有时间戳,正则等,同时也支持用户自定义拦截器,这就需要用户编码来定义拦截器,然后配置在信源中。
信源、信道、信宿这三个组件组成一个代理agent,他们在一个代理agent中,可以是多个信道,多个信宿的组合,在本文最后,我们会给出一个复杂的示例,展示两个信道memory对应两个信宿hdfs和FILE_ROLL的组合。下面我们给出几个实例,并运行。
1、将命令执行的结果保存到平面文件中的示例:
简单配置如下:
a2.sources=s2
a2.channels=c2
a2.sinks=k2
a2.sources.s2.type=exec
a2.sources.s2.command=cat /home/software/flume/flume-test
a2.sinks.k2.type=FILE_ROLL
a2.sinks.k2.sink.directory=/home/software/flume/files
a2.sinks.k2.sink.rollInterval=0
a2.channels.c2.type=file
a2.channels.c2.checkpointDir=/home/software/flume/fc/checkpoint
a2.channels.c2.dataDirs=/home/software/flume/fc/data
a2.sources.s2.channels=c2
a2.sinks.k2.channel=c2
启动flume,加载配置:
bin/flume-ng agent --conf conf --conf-file conf/exec.conf --name a2 -Dflume.root.logger=INFO,console
运行命令,打印日志,这个示例就结束了,运行的命令是查看/home/software/flume/flume-test这个文件的内容,并将内容写入files目录下。

这里只是为了了解exec这个类型的效果,在实际中,应该是执行一个命令,会循环的输出信息,比如执行一个定时任务,让结果保存在系统中。
2、将远程avro文件写入文件的示例:
配置如下:
a3.sources=s3
a3.channels=c3
a3.sinks=k3
a3.sources.s3.type=avro
a3.sources.s3.bind=0.0.0.0
a3.sources.s3.port=30000
a3.sources.s3.threads=5
a3.sinks.k3.type=FILE_ROLL
a3.sinks.k3.sink.directory=/home/software/flume/files
a3.sinks.k3.sink.rollInterval=0
a3.channels.c3.type=jdbc
a3.sources.s3.channels=c3
a3.sinks.k3.channel=c3
启动flume,加载配置:
bin/flume-ng agent --conf conf --conf-file conf/avro.conf --name a3 -Dflume.root.logger=INFO,console
启动成功,打印信息:
新开一个终端窗口,输入如下命令:
bin/flume-ng avro-client -H localhost -p 30000 -F message
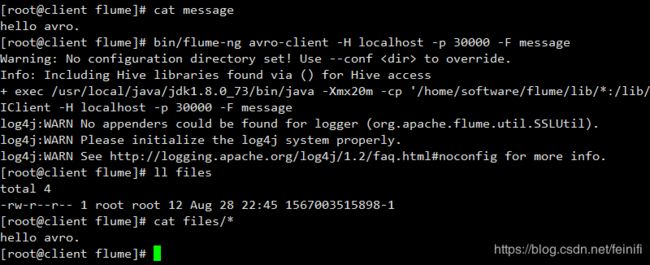
从运行结果看,我们将message文件的内容通过avro客户端传输给了flume信源,最终成功写入了files文件夹下。这里,我们使用的信道是jdbc,默认使用的是derby数据库做缓存,我们可以看启动日志信道的相关信息:
2019-08-28 22:45:14,161 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:151)] Creating channels
2019-08-28 22:45:14,190 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c3 type jdbc
2019-08-28 22:45:14,213 (conf-file-poller-0) [WARN - org.apache.flume.channel.jdbc.impl.JdbcChannelProviderImpl.initializeDataSource(JdbcChannelProviderImpl.java:393)] No connection URL specified. Using embedded derby database instance.
2019-08-28 22:45:14,214 (conf-file-poller-0) [WARN - org.apache.flume.channel.jdbc.impl.JdbcChannelProviderImpl.initializeDataSource(JdbcChannelProviderImpl.java:428)] Overriding values for - driver: org.apache.derby.jdbc.EmbeddedDriver, user: saconnectUrl: jdbc:derby:/root/.flume/jdbc-channel/db;create=true, jdbc properties file: null, dbtype: DERBY
2019-08-28 22:45:15,777 (conf-file-poller-0) [WARN - org.apache.flume.channel.jdbc.impl.JdbcChannelProviderImpl.initializeChannelState(JdbcChannelProviderImpl.java:155)] JDBC channel will operate without a capacity limit.
2019-08-28 22:45:15,778 (conf-file-poller-0) [INFO - org.apache.flume.channel.jdbc.JdbcChannel.configure(JdbcChannel.java:91)] JDBC Channel initialized: c33、将网络数据写入hdfs中的示例:
配置如下:
a4.sources=s4
a4.channels=c4
a4.sinks=k4
a4.sources.s4.type=netcat
a4.sources.s4.bind=0.0.0.0
a4.sources.s4.port=30000
a4.channels.c4.type=memory
a4.channels.c4.capacity=1000
a4.channels.c4.transactionCapacity=100
a4.sinks.k4.type=hdfs
a4.sinks.k4.hdfs.path=/user/flume
a4.sinks.k4.hdfs.filePrefix=log
a4.sinks.k4.hdfs.rollInterval=0
a4.sinks.k4.hdfs.fileType=DataStream
a4.sinks.k4.hdfs.rollCount=3
a4.sources.s4.channels=c4
a4.sinks.k4.channel=c4启动flume,加载配置:
bin/flume-ng agent --conf conf --conf-file conf/hdfs.conf --name a4 -Dflume.root.logger=INFO,console
启动成功之后,我们模拟发送http请求给127.0.0.1 30000,通过telnet登录远程连接,并输入内容,然后回车,我们这里模拟发送7次消息。
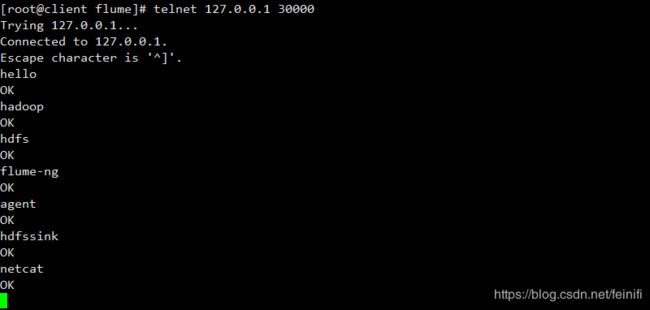
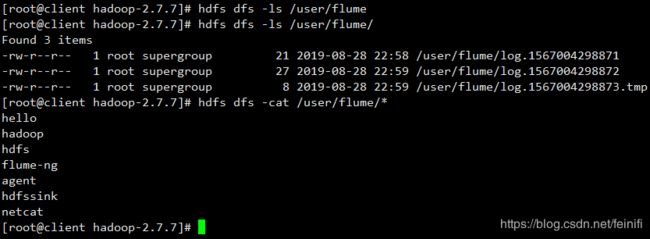
配置文件中,我们设置了hdfs文件回滚条数为3,即只能存储3个记录,这里模拟发送的7条消息,能够生成三个文件,其中,两个文件是写满的,因此是完整的文件,没有后缀tmp,最后一个文件没有写满,所以是一个临时文件。
我们看启动日志的打印信息,可以看到,随着输入,临时文件会变为完整文件。
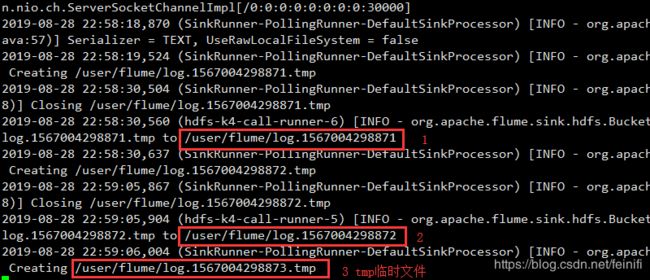
在hdfs上检验文件内容:
4、添加拦截器的示例:
这里我们以网络请求写入hdfs为例,增加时间戳拦截器
配置如下:
a4.sources=s4
a4.channels=c4
a4.sinks=k4
a4.sources.s4.type=netcat
a4.sources.s4.bind=0.0.0.0
a4.sources.s4.port=30000
a4.sources.s4.interceptors=ts
a4.sources.s4.interceptors.ts.type=org.apache.flume.interceptor.TimestampInterceptor$Builder
a4.channels.c4.type=memory
a4.channels.c4.capacity=1000
a4.channels.c4.transactionCapacity=100
a4.sinks.k4.type=hdfs
a4.sinks.k4.hdfs.path=/user/flume/ts-%Y-%m-%d
a4.sinks.k4.hdfs.filePrefix=log-
a4.sinks.k4.hdfs.rollInterval=0
a4.sinks.k4.hdfs.fileType=DataStream
a4.sinks.k4.hdfs.rollCount=3
a4.sources.s4.channels=c4
a4.sinks.k4.channel=c4
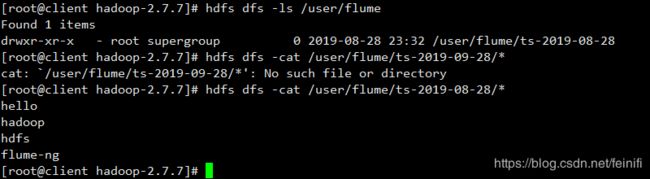
这里时间戳拦截器会将收集的数据保存在对应日期的文件夹下,配置在信源上,但是可以作用在信宿上。
我们还是启动flume,加载配置文件:
bin/flume-ng agent --conf conf --conf-file conf/hdfs-ts.conf --name a4 -Dflume.root.logger=INFO,console
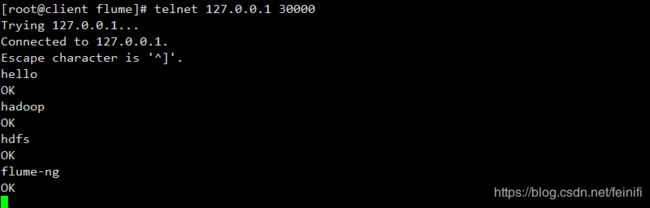
启动成功之后,我们通过telnet模拟发送4条消息:
消息发送成功,验证hdfs文件:
5、两个信道,两个信宿的示例:
信道均采用memory,信宿一个使用FILE_ROLL,一个是hdfs,相当于一个存在本地文件系统,一个存在hdfs上。
配置如下:
a5.sources=s5
a5.channels=mc1 mc2
a5.sinks=hdfssink filesink
a5.sources.s5.type=netcat
a5.sources.s5.bind=0.0.0.0
a5.sources.s5.port=30000
a5.sources.s5.interceptors=ts
a5.sources.s5.interceptors.ts.type=org.apache.flume.interceptor.TimestampInterceptor$Builder
a5.channels.mc1.type=memory
a5.channels.mc1.capacity=1000
a5.channels.mc1.transactionCapacity=100
a5.channels.mc2.type=memory
a5.channels.mc2.capacity=1000
a5.channels.mc2.transactionCapacity=100
a5.sinks.hdfssink.type=hdfs
a5.sinks.hdfssink.hdfs.path=/user/flume-%Y-%m-%d
a5.sinks.hdfssink.hdfs.filePrefix=log
a5.sinks.hdfssink.hdfs.rollInterval=0
a5.sinks.hdfssink.hdfs.rollCount=3
a5.sinks.hdfssink.hdfs.fileType=DataStream
a5.sinks.filesink.type=FILE_ROLL
a5.sinks.filesink.sink.directory=/home/software/flume/files
a5.sinks.filesink.sink.rollInterval=0
a5.sources.s5.channels=mc1 mc2
a5.sinks.hdfssink.channel=mc1
a5.sinks.filesink.channel=mc2
a5.sources.s5.selector.type=replicating这个配置示例,综合了使用FILE_ROLL,hdfs作为信宿,时间戳拦截器作为信源拦截器的例子。
还是启动flume,加载配置:
bin/flume-ng agent --conf conf --conf-file conf/replicating.conf --name a5 -Dflume.root.logger=INFO,console
启动成功,通过telnet模拟发送4条消息:
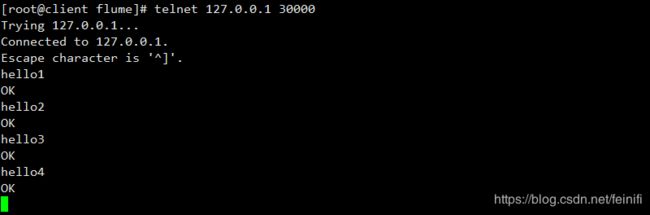
消息发送成功,验证hdfs文件:
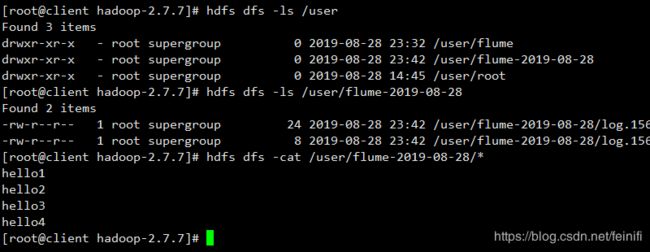
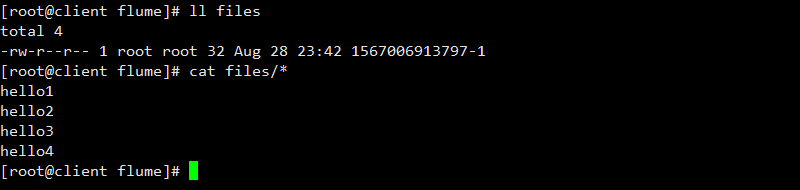
验证FILE_ROLL信宿的文件:
一般实际应用中,我们会收集kafka的消息,然后存入hdfs,配置思路还是一样。