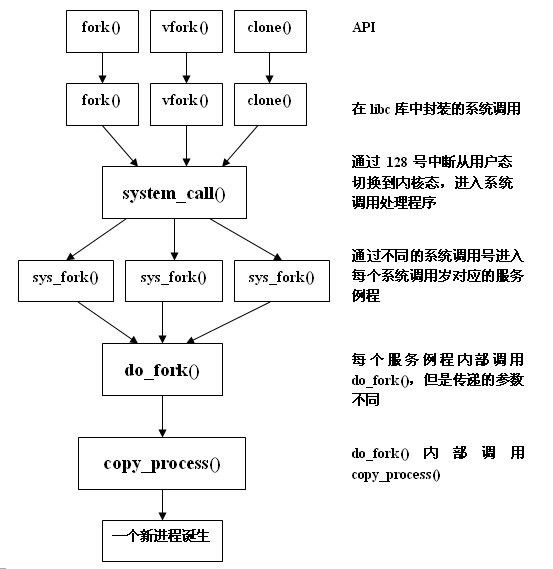
一、linux中一般系统调用的执行过程
系统调用是一种特殊的中断,x86 的系统调⽤实现经历了 int $0x80/iret 到 sysenter/sysexit 再到 syscall/sysret 的演变。
这里说的是3.0版本之前的linux内核的系统调用和退出过程。
方式一:通过int $0x80指令发出系统调用/通过iret汇编指令退出系统调用
1.指令流执行到系统调用函数时,系统调用函数通过int 0x80指令进入系统调用入口程序(system_call函数)
2.保护现场,system_call函数首先把系统调用号和这个异常处理程序可以用到的所有CPU寄存器保存到内核栈中
3.接下来system_call函数会检测thread_info结构中的相应字段,确定是否需要跟踪
4.然后system_call函数会对用户进程传递来的系统调用号进行有效性检查,无效会返回用户进程
5.若有效则调用eax保存的系统调用号对应的服务例程(如何根据系统调用号在系统调用表中找到对应函数入口的具体过程可参见上次作业)
6.当系统调用服务例程结束时,system_call函数从eax获得它的返回值,并把返回值存放在曾保存用户态eax寄存器值的那个栈单元的位置上
7.用户进程在eax中找到系统调用的返回码后,system_call函数关闭本地中断并检查thread_info中的flags字段
8.恢复现场,并执行iret汇编指令以重新执行用户态进程
方式二:通过sysenter指令发出系统调用/通过sysexit汇编指令退出系统调用
sysenter和syscall都借助CPU内部的MSR寄存器来查找系统调用处理入口,可以快速切换CPU的指令指针(eip/rip)到系统调用处理入口,但本质上还是中断处理的思路,压栈关键寄存器、保存现场、恢复现场,最后系统调用返回。x86-64引⼊了swapgs指令,类似快照的⽅式将保存现场和恢复现场时的CPU寄存器也通过CPU内部的存储器快速保存和恢复,近⼀步加快了系统调用。

二、以fork和execve系统调用为例分析中断上下文的切换
库函数fork是⽤户态创建⼀个⼦进程的系统调⽤API接⼝。fork在正常执⾏后,if条件判断中除了if (pid < 0)异常处理没被执⾏,else if (pid == 0)和else两段代码都被执⾏了,其中pid==0中为子进程的执行过程,else中为父进程的执行过程,具体代码如下所示:
#include#include int main () { pid_t fpid; //fpid表示fork函数返回的值 int count=0; fpid=fork(); if (fpid < 0) printf("error in fork!"); else if (fpid == 0) { printf("执行子进程,子进程的进程号为%d\n",getpid()); count++; } else { printf("执行父进程,父进程的进程号为%d\n",getpid()); count++; } printf("统计结果是: %d\n",count); return 0; }
代码编译运行结果如下所示:

在语句fpid=fork()之前,只有一个进程在执行这段代码,但在这条语句之后,就变成两个进程在执行了,但为什么两个进程的fpid不同呢,这与fork函数的特性有关。
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
fork系统调用过程
正常的⼀个系统调⽤都是陷⼊内核态,再返回到⽤户态,然后继续执⾏系统调⽤后的下⼀条指令。fork和其他系统调⽤不同之处是它在陷⼊内核态之后有两次返回,第⼀次返回到原来的⽗进程的位置继续向下执⾏,这和其他的系统调⽤是⼀样的。在⼦进程中fork也返回了⼀次,会返回到⼀个特 定的点——ret_from_fork,通过内核构造的堆栈环境,它可以正常系统调⽤返回到⽤户态。
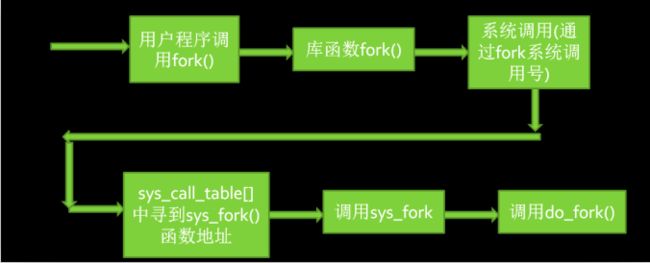
_do_fork系统调用流程概述
fork⼀个⼦进程的过程中,复制⽗进程的资源时采⽤了Copy On Write(写时复制)技术,不需要修改的进程资源⽗⼦进程是共享内存存储空间的。
_do_fork函数主要完成了调⽤copy_process()复制⽗进程、获得pid、调⽤wake_up_new_task将⼦进程加⼊就绪队列等待调度执⾏等等。

copy_process函数主要完成了调⽤dup_task_struct复制当前进程(⽗进程)描述符task_struct、信息检查、初始化、把进程状态设置为TASK_RUNNING(此时⼦进程置为就绪态)、采⽤写时复制技术逐⼀复制所有其他进程资源、调⽤copy_thread_tls初始化⼦进程内核栈、设置⼦进程pid等。其中最关键的就是dup_task_struct复制当前进程(⽗进程)描述符task_struct和copy_thread_tls初始化⼦进程。⼦进程创建好了进程描述符、内核堆栈等后,就可以通过wake_up_new_task(p)将⼦进程添加到就绪队列,使之有机会被调度执⾏,进程的创建⼯作就完成了,⼦进程就可以等待调度执⾏,⼦进程的执⾏从这⾥设定的ret_from_fork开始。
总结来说,进程的创建过程⼤致是⽗进程通过fork系统调⽤进⼊内核_do_fork函数,如下图所示复制进程描述符及相关进程资源(采⽤写时复制技术)、分配⼦进程的内核堆栈并对内核堆栈和thread等进程关键上下⽂进⾏初始化,最后将⼦进程放⼊就绪队列,fork系统调⽤返回;⽽⼦进程则在被调度执⾏时根据设置的内核堆栈和thread等进程关键上下⽂开始执⾏。

execve系统调用
execve() 系统调用的作用是运行另外一个指定的程序。它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃,它的堆、栈和所有的段数据都会被新进程相应的部分代替,然后会从新程序的初始化代码和 main 函数开始运行。同时,进程的 ID 将保持不变。execve() 系统调用通常与 fork() 系统调用配合使用。从一个进程中启动另一个程序时,通常是先 fork() 一个子进程,然后在子进程中使用 execve() 变身为运行指定程序的进程。 例如,当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork() 了自身进程,然后在子进程中使用 execve() 来运行指定的程序。
测试代码如下所示:
#include#include #include int main(int argc, char * argv[]){ int pid; pid = fork(); if (pid < 0){ fprintf(stderr, "Fork Failed!\n"); exit(-1); } else if (pid == 0){ execlp("/bin/ls", "ls", NULL); } else{ printf("Child Complete!\n"); exit(0); } }
上述代码实现了一个ls指令的功能,⾸先fork⼀个⼦进程,pid为0的分⽀是将来的⼦进程要执⾏的,在⼦进程⾥调⽤execlp来加载可执⾏程序ls,这⾥没有写环境变量。完整的Shell程序中会有环境变量,接收与否则取决于⼦进程的main函数。Shell程序⼤致就是这样⼯作的。
代码运行结果如下所示:

可见代码执行结果与在Shell中输入ls指令的结果相同。
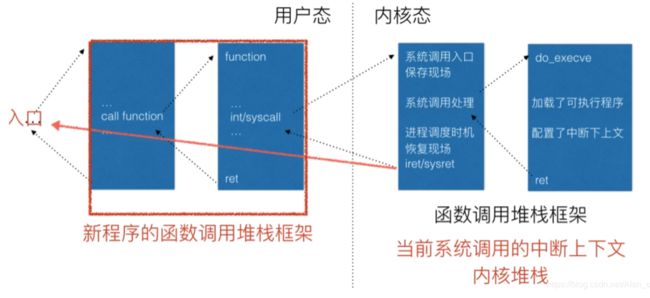
值得注意的是,在调⽤execve系统调⽤时,当前的执⾏环境是从⽗进程复制过来的,execve系统调⽤加载完新的可执⾏程序之后已经覆盖了原来⽗进程的上下⽂环境。execve系统调⽤在内核中帮我们重新布局了新的⽤户态执⾏环境。
execve与fork的区别与联系
内核装载可执⾏程序的过程,实际上是执⾏⼀个系统调⽤execve,和前⾯分析的fork及其他的系统调⽤的主要过程是⼀样的。但是execve这个系统调⽤的内核处理过程和fork⼀样也是⽐较特殊的。
当前的可执⾏程序在执⾏,执⾏到execve系统调⽤时陷⼊内核态,在内核⾥⾯⽤do_execve加载可执⾏⽂件,把当前进程的可执⾏程序给覆盖掉。当execve系统调⽤返回时,返回的已经不是原来的那个可执⾏程序了,⽽是新的可执⾏程序。execve返回的是新的可执⾏程序执⾏的起点,静态链接的可执⾏⽂件也就是main函数的⼤致位置,动态链接的可执⾏⽂件还需要ld链接好动态链接库再从main函数开始执⾏。
三、Linux系统的一般执行过程(含中断与进程切换)
以32位x86系统结构linux-3.18.6为例,以系统调⽤作为特殊的中断简要总结如下:
(1)正在运⾏的⽤户态进程X。
(2)发⽣中断(包括异常、系统调⽤等),CPU完成load cs:rip(entry of a specific ISR),即跳转到中断处理程序⼊⼝。
(3)中断上下⽂切换,具体包括如下⼏点:
- swapgs指令保存现场,可以理解CPU通过swapgs指令给当前CPU寄存器状态做了⼀个快照。
- rsp point to kernel stack,加载当前进程内核堆栈栈顶地址到RSP寄存器。快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现⽤户堆栈和内核堆栈的切换。
- save cs:rip/ss:rsp/rflags:将当前CPU关键上下⽂压⼊进程X的内核堆栈,快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现的。
此时完成了中断上下⽂切换,即从进程X的⽤户态到进程X的内核态。
(4)中断处理过程中或中断返回前调⽤了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下⽂切换等。
(5)switch_to调⽤了__switch_to_asm汇编代码做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程(本例假定为进程Y)的内核堆栈,并完成了进程上下⽂所需的指令指针寄存器状态切换。之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以从switch_to下⼀⾏代码继续执⾏)。
(6)中断上下⽂恢复,与(3)中断上下⽂切换相对应。注意这⾥是进程Y的中断处理过程中,⽽(3)中断上下⽂切换是在进程X的中断处理过程中,因为内核堆栈从进程X 切换到进程Y了。
(7)为了对应起⻅,中断上下⽂恢复的最后⼀步单独拿出来(6的最后⼀步即是7)iret - pop cs:rip/ss:rsp/rflags,从Y进程的内核堆栈中弹出(3)中对应的压栈内容。此时完 成了中断上下⽂的切换,即从进程Y的内核态返回到进程Y的⽤户态。注意快速系统调⽤返回sysret与iret的处理略有不同。
(8)继续运⾏⽤户态进程Y。