《ENSEMBLE ADVERSARIAL TRAINING: ATTACKS AND DEFENSES》
论文学习报告
组员:裴建新 赖妍菱 周子玉
2020-04-12
1 引言
机器学习(ML)模型往往容易受到敌对示例的攻击,恶意干扰输入,旨在在测试时误导模型。对抗性训练(Szegedy et al.,2013)通过使用对抗性的例子增加训练数据,增强了鲁棒性。Madry等人(2017)研究表明,对抗性训练的模型可以对白盒攻击(即攻击)具有鲁棒性。如果训练过程中出现的扰动使模型的损失达到最大。然而,之前将这种方法扩展到图像级任务的尝试(Deng et al,2009)已被证明是不成功的(Kurakin et al,2009)。
因此,我们很自然地会思考,是否有可能大规模地实现对黑盒攻击的鲁棒性。为了达到这个目标,Kurakin等人(2017b)反向地训练了一个Inception v3模型(Szegedy et al.,2016b),在ImageNet上使用基于模型损失线性化的“单步”攻击(Goodfellow et all 2014b)。他们训练的模型对单步扰动是健壮的,但对代价更高的“多步”攻击仍然是脆弱的。然而。Kurakin等人(2017b)发现这些攻击无法在模型之间可靠地传输。由此得出结论,该模型的鲁棒性应扩展到黑盒攻击。令人惊讶的是,我们证明了事实并非如此。
作者的实验证明,用单步方法的对抗性训练允许一个退化的全局最小值,其中模型的损失不能被一个线性函数可靠地近似。特别地,作者发现该模型的决策面在数据点附近表现出明显的曲率,从而降低了基于单一梯度计算的攻击。
首先,作者通过对抗性训练,发现单步方法仍然容易受到简单攻击。对于黑盒攻击,作者发现,在一个不防御的模型上制造的扰动常常会转移到一个经过反向训练的模型上。作者还介绍了一个简单而强大的单步攻击,它应用了一个小的随机扰动——在线性化模型的损失之前,避开数据点附近的非平滑区域。虽然作者的攻击看起来比Goodfellow等人(2014b)的快速梯度符号方法弱,但在相同的扰动范数下,无论是否接受过对抗训练,我们的攻击都明显优于它。
其次,作者提出了集合对抗训练,这是一种包含从其他预训练模型中转移过来的单位输入的训练方法。作者的方法将对抗性检验从训练模型的参数中解耦出来,增加了训练过程中出现的扰动的多样性。作者在ImageNet上训练了Inception v3和Inception ResNet v2模型,通过使用单步和多步攻击(Goodfellow et al., 2014b;Carlini & Wagner, 2017a;Kurakinet al., 2017a;(Madry et al.,2017)。作者的方法可以全局地降低对抗性例子空间的维数(Tramer等,2017)。作者的Inception ResNet v2模型赢得了NIPS 2017年第一轮对抗攻击防御竞赛(Kurakinet al., 2017c)。
2 相关工作
在深层神经网络中,各种针对对抗性例子的防御技术已经取得了成功(gu & rigazio, 2014; luo et al.,2015; Papernot et al., 2016c; Nayebi & Ganguli, 2017;Cisseet al., 2017)但仍然有许多脆弱的自适应攻击者(Carlini & Wagner, 2017a)。对抗性训练(Szegedy et al., 2013年; Goodfellow et al., 2014b; Kurakin et al. 2017b)似乎最有希望学习稳健模型。
Szegedy et al(2013)发现,对抗性样例在模型之间转移,从而使得对已部署模型的黑盒攻击成为可能。Papernot等(2017)通过利用目标模型的预测来提取代理模型(Tramer等,2016),表明黑盒攻击可以在不访问训练数据的情况下成功。之前的一些工作已经表明,经过反向训练的模型可能仍然容易受到黑盒攻击:Goodfellow等人(2014b)发现,MNIST上的对抗性maxout网络在转移的示例上的错误略高于白盒示例。Papernot等(2017)进一步表明,训练小扰动的模型可以规避较大量级的y传递扰动。我们发现,对抗性训练会降低模型损失的线性近似的准确性,这是梯度掩蔽现象的一个实例(Papernot等,2016b)。
3 前序知识
威胁模型
作者提供了3.1节中介绍的威胁模型的正式定义。在下面,作者明确地将模型所属的假设空间定义为H。训练集中的数据 ![]() 服从D分布。
服从D分布。
![]()
其中 ![]() 是一个随机化的训练过程,它接受模型体系结构H的描述,其中
是一个随机化的训练过程,它接受模型体系结构H的描述,其中 ![]() 是从D中采样的训练集,r是随机值。
是从D中采样的训练集,r是随机值。
给定一组来自D的测试输入 ![]() 和一个预算
和一个预算 ![]() ,一个对手A产生一个对抗样本
,一个对手A产生一个对抗样本 ![]() ,对所有的
,对所有的 ![]() ,有
,有 ![]() 。
。
用目标模型在 ![]() 上的错误率来评估攻击的成功率:
上的错误率来评估攻击的成功率:

作者假设A可以根据数据分布对输入进行采样。我们定义了三种对抗:
白盒攻击:对于一个给定的模型,白盒对抗可以访问整个训练过程中的所有数据,比如模型结构H、训练数据 ![]() ,随机数r以及h。对内部模型权值的白盒访问对应于一个非常强大的对抗性模型。
,随机数r以及h。对内部模型权值的白盒访问对应于一个非常强大的对抗性模型。
非交互式的黑盒攻击:对于一个给定的模型,非交互式的黑盒攻击可以访问目标模型的训练流程,以及模型结构。最重要的是,一个黑盒对手不了解随机性r用来训练目标,也没有目标的参数h。
基于可转移性的攻击(Szegedy et al.,2013)属于这类攻击。最重要的是,一个黑盒对手不了解随机性r用来训练目标,也没有目标的参数h。黑盒攻击在我们的论文其实略强于上面定义的,他们使用相同的训练数据X训练,以及相同的目标模型。对于集合对抗训练,目标训练程序也知道所有预训练模型的架构。在这项工作中,我们总是使用与目标模型不同的体系结构来训练局部模型的黑盒攻击。实际上,我们发现在这种情况下,对经过对抗性训练的模型的黑盒攻击更强。
作者论文的主要关注点是上面定义的非交互式黑箱攻击。,我们还形式化了一个更强的概念,即交互式黑箱对手,它附加地向目标模型发出预测查询(Papernot et al.,2017)。我们注意到,在将ML模型部署为大型系统(例如,自动驾驶汽车)的一部分的情况下,对手可能无法直接访问模型的查询接口。
交互式的黑盒攻击:对于一个给定的模型,非交互式的黑盒攻击可以访问目标模型的训练流程,以及模型结构。对手向目标模型发出(自适应)oracle查询,并且对于任意一个输入x,对手都可以获得其分类器的预测结果h(x)。
Papernot et al(2017)表明,这样的攻击是可能的,即使敌人只会获得少量的样本d。注意,如果目标模型的预测接口另外返回类分数h (x),交互式的黑盒对抗可以利用查询目标模型来估计模型的梯度(例如,使用有限差分)(chen et al ., 2017)。
3 对抗训练框架
作者区分了能够访问目标模型参数(例如,h)的白盒对抗和只具有关于模型内部工作的部分信息的黑盒对抗。提出了标准经验风险最小化的对抗性变体,目标是尽量减少对抗样本的风险:

Szegedy认为在这种情况下,对抗性训练是给定攻击用来近似求解内部最大化问题,而外部最小化问题对应于这些例子上的训练。可以注意到作者在实验中使用的对抗性训练的原始公式,既训练了“clean”的例子x,也训练了对抗样本 ![]() 。
。
3.1 对抗训练
作者使用了三种算法来生成具有有界 ![]() 范数的对抗样本。前两个是单步single-step(即,它们需要单个梯度计算);第三个是迭代iterative,它计算多个梯度更新。
范数的对抗样本。前两个是单步single-step(即,它们需要单个梯度计算);第三个是迭代iterative,它计算多个梯度更新。
Fast Gradient Sign Method (FGSM).这个方法线性化了内置的最大化问题:
![]()
Single-Step Least-Likely Class Method (Step-LL)。这个方法是FGSM的变种,针对最不可能的类别:
![]()
用识别概率最小的类别(目标类别)代替对抗扰动中的类别变量,再将原始图像减去该扰动,原始图像就变成了对抗样本,并能输出目标类别。虽然这个攻击只是间接地解决了内置的最大化问题,但被Kurakin证实了是在ImageNet上最有效的对抗性训练。
Iterative Attack (I-FGSM or Iter-LL)。这个方法迭代的使用FGSM或Step-LL k次,保持步长 ![]() ,并且迭代的每一步都是在以x为中心,
,并且迭代的每一步都是在以x为中心, ![]() 为半径的
为半径的 ![]() 球面上。它用投影梯度下降法(projected gradient descen)求解最大值问题。对于相同的
球面上。它用投影梯度下降法(projected gradient descen)求解最大值问题。对于相同的 ![]() ,迭代攻击比单步攻击导致更高的错误率,但传输率更低。
,迭代攻击比单步攻击导致更高的错误率,但传输率更低。
3.2 单步对抗训练的退化全局最小值
当使用单步攻击进行对抗训练时,作者通过用单步攻击的输出替换内置最大化问题的解来近似方程式。
![]()
对于具有高表达能力的模型族 ![]() ,这种可选的优化问题允许至少有两个本质上不同的全局最小值
,这种可选的优化问题允许至少有两个本质上不同的全局最小值 ![]() :
:
输入一个来自分布 ![]() 的值x,在
的值x,在 ![]() 范数内没有近似x的
范数内没有近似x的 ![]() 能引起模型的高损失,也就是说:
能引起模型的高损失,也就是说: ![]() ,换句话说,对所有
,换句话说,对所有 ![]() 的边界扰动,
的边界扰动, ![]() 是具有健壮性的。
是具有健壮性的。
最小值 ![]() 是一个模型,其中作为攻击基础的逼近方法很不适合模型的损失函数。
是一个模型,其中作为攻击基础的逼近方法很不适合模型的损失函数。 ![]() 因此,当被应用于
因此,当被应用于 ![]() 时,攻击会产生远非最优的样本
时,攻击会产生远非最优的样本 ![]() 。
。
注意,第二个“退化”最小值可能比单步攻击产生的样本过拟合的简单情况更微妙。实际上,作者在第4.1节中指出,应用于对抗训练的模型的单步攻击创建了对抗样本,即使对于不防御的模型,这些示例也很容易分类。因此,对抗训练并不仅仅是学习如何抵抗训练中所使用的特定攻击,它实际上会使攻击的整体表现变差。这一现象与反黑客的概念有关(Amodei),其中一个代理通过未能捕捉到设计师真实意图的意外行为,最大化其形式目标功能。
3.3 集成对抗训练
作者在前面提到的退化最小值是可以实现的,因为学习模型的参数同时影响(1)中最小化和最大化的质量。一种解决方案是使用更强的对抗样本生成过程,但代价很高(Madry)。另外,Baluja和Fischer建议在GAN框架中训练一个对抗生成器模型。此生成器的功率可能需要仔细地进行调优,以避免类似的退化极小值(生成器或分类器压倒另一个)。
作者提出了一种概念上更简单的方法,将对抗样本的生成与被训练的模型解耦,同时将其与黑盒对抗的健壮性明确联系起来。也就是集成对抗训练,通过使用在其他静态预训练模型上产生的对抗样本来扩充模型的训练数据。当对抗样本在模型之间传递时,外部模型上的扰动是(1)中最大化问题的很好的近似。此外,所学习的模型不能影响这些对抗样本的“强度”。因此,最小化训练损失可以增强对来自某些模型的黑盒攻击的鲁棒性。
作者将集成对抗训练与多源领域自适应联系起来。在领域自适应中,一个模型从一个或多个资源分布的 ![]() ,对来自不同目标分布
,对来自不同目标分布 ![]() 的样本x求值。
的样本x求值。
设 ![]() 为从D中采样
为从D中采样 ![]() 得到的一个对抗性分布,对
得到的一个对抗性分布,对 ![]() 这样的模型计算一个对抗样本
这样的模型计算一个对抗样本 ![]() ,输出
,输出 ![]() 。在集成对抗训练中,D是源分布(干净数据)
。在集成对抗训练中,D是源分布(干净数据) ![]() 是包括当前训练模型和静态预训练模型的攻击。目标分布以不可见的黑盒对抗
是包括当前训练模型和静态预训练模型的攻击。目标分布以不可见的黑盒对抗 ![]() 的形式出现。域适应的标准泛化界限产生以下结果。
的形式出现。域适应的标准泛化界限产生以下结果。
定理1:让 ![]() 成为一个通过集成对抗训练和静态黑盒对抗
成为一个通过集成对抗训练和静态黑盒对抗 ![]() 来学习的模型。那么,如果
来学习的模型。那么,如果 ![]() 相对于黑盒对抗
相对于黑盒对抗 ![]() 是稳健的,那么,如果
是稳健的,那么,如果 ![]() 被训练时使用的黑盒对抗
被训练时使用的黑盒对抗 ![]() 显示出良好的状态,那么
显示出良好的状态,那么 ![]() 被未来的黑盒对手a显示出一定的攻击误差,如果
被未来的黑盒对手a显示出一定的攻击误差,如果 ![]() 平均来说并不比静态对抗
平均来说并不比静态对抗 ![]() “强得多”
“强得多”
图1:单步对抗训练中的梯度掩蔽。我们在 ![]() 上画出模型
上画出模型 ![]() 的损失,其中g是有符号的梯度,
的损失,其中g是有符号的梯度, ![]() 是正交的对抗性方向。图(b)是(a)在x附近的变焦。这种梯度很难近似全局的损失
是正交的对抗性方向。图(b)是(a)在x附近的变焦。这种梯度很难近似全局的损失
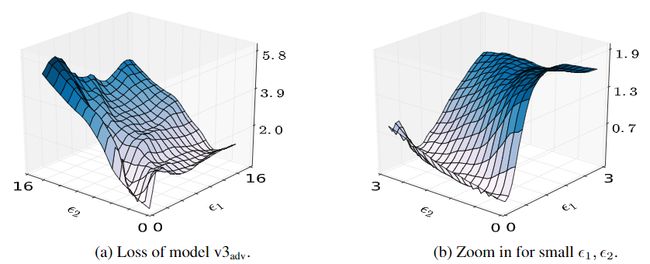
图1
4 实验
4.1 攻击对抗性训练网络
Kurakin等发现经过对抗训练的模型对于各种单步攻击都具有鲁棒性。他们的结论是,这种鲁棒性应该针对的是从其他模型转移过来的攻击。正如论文所展示的,对单步攻击的鲁棒性实际上是有误导性的,因为模型已经学会了去整合模型梯度中包含的信息。作者发现在白盒和黑盒设置里, ![]() 模型更容易受到单步攻击,
模型更容易受到单步攻击, ![]() 也是这样。
也是这样。
表1展示了模型之间传递的单步攻击的错误率。计算一个源模型上的扰动,并将其传递给所有其他目标模型,当源模型和目标模型相同时,攻击为白盒攻击。由表1可见,未经过对抗训练的模型在白盒单步攻击下的错误率均为最高。但是经过对抗训练的模型在黑盒单步攻击下的错误率是最高的,而不是白盒攻击,这说明对抗训练大大提高了对白盒单步攻击的鲁棒性。

表1
论文还提出了一种新的随机单步攻击。因为数据点附近可能发生梯度掩蔽。所以,作者建议以较小的随机步长进行单步攻击,以便在线性化模型损失之前逃避数据点的非平滑区域。针对参数 ![]() 和(其中
和(其中 ![]() ),这样的新攻击称为R + FGSM(或者R + Step-LL),定义如下:
),这样的新攻击称为R + FGSM(或者R + Step-LL),定义如下:
![]()
表2比较了Step-LL和R + Step-LL方法的错误率(其中 ![]() 和
和 ![]() )。R + Step-LL方法中额外的随机步骤会对所有模型产生更强的攻击,对于那些没有接受过对抗训练的模型也是一样。对于R + Step-LL攻击和两步Iter-LL攻击,后者计算了两个梯度步长。结果发现对于经过对抗训练的Inception v3模型,R + Step-LL攻击要强于两步式Iter-LL攻击。
)。R + Step-LL方法中额外的随机步骤会对所有模型产生更强的攻击,对于那些没有接受过对抗训练的模型也是一样。对于R + Step-LL攻击和两步Iter-LL攻击,后者计算了两个梯度步长。结果发现对于经过对抗训练的Inception v3模型,R + Step-LL攻击要强于两步式Iter-LL攻击。

表2
4.2集成对抗训练
为了评估对黑盒攻击的鲁棒性如何在模型之间进行泛化,论文将在三个不同的模型上进行实验,表3展示了在ImageNet上的黑盒实验,由Holdout Models产生对抗样本,再把对抗样本放入Pre-trained Models进行训练,最后得到Trained Model。

表3
表4展示了在ImageNet上进行集成对抗训练的错误率(%)。选取 ![]() ,其中干净数据的错误率是在整个测试集中计算的,通过干净数据、白盒Step-LL和一系列黑盒攻击(Step-LL,R + Step-LL , FGSM,I-FGSM,PGD)的错误率反映了实验结果。由表4可见,集成对抗训练能有效降低黑盒攻击的错误率,但是与标准对抗训练相比,使用集成对抗训练的模型在干净数据上的准确性稍差。除此之外,模型还更容易受到白盒Step-LL的影响,因为它们仅对这种扰动进行了部分训练。
,其中干净数据的错误率是在整个测试集中计算的,通过干净数据、白盒Step-LL和一系列黑盒攻击(Step-LL,R + Step-LL , FGSM,I-FGSM,PGD)的错误率反映了实验结果。由表4可见,集成对抗训练能有效降低黑盒攻击的错误率,但是与标准对抗训练相比,使用集成对抗训练的模型在干净数据上的准确性稍差。除此之外,模型还更容易受到白盒Step-LL的影响,因为它们仅对这种扰动进行了部分训练。
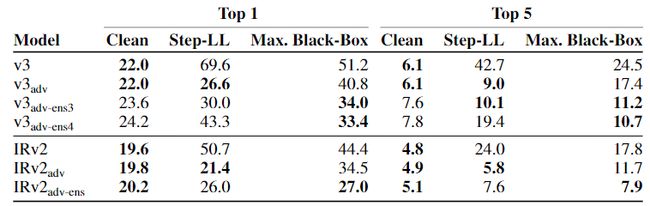
表4
5 结论与未来展望
在整篇文章中,作者通过对比已有的三种攻击方法,分析出单歩攻击和迭代攻击的缺点,由此提出了一种更简单有效的单步攻击方法。在线性化模型的损失之前,应用一个小的随机扰动,以此避开数据点附近的非平滑区域。作者还提出了集合对抗训练,这是一种包含从其他预训练模型中转移过来的单位输入的训练方法。作者的方法将对抗性检验从训练模型的参数中解耦出来,增加了训练过程中出现的扰动的多样性。
以前关于大规模对抗性训练的工作已经产生了令人鼓舞的结果,显示出对(单步)对抗性例子的强大鲁棒性。然而,这些结果具有误导性,因为对抗性训练的模型仍然容易受到简单的黑盒和白盒攻击。结果表明,对抗性训练可以通过将生成的对抗性实例与所训练的模型解耦而得到改善。通过对综合对抗训练的实验,证明了该方法的有效性。
作者没有考虑黑盒攻击通过其他方式攻击模型,而不是通过从局部模型转移实例。例如,生成技术可能为更强的攻击提供了途径。然而,肖等人最近的一项研究发现在MNIST和CIFAR10数据集上对抗性训练生成的模型对的攻击具有弹性,并且通常比对迭代攻击进行对抗性训练的模型具有更高的健壮性。
6 参考文献
[1] Peanut_范.迁移学习——Domain Adaptation[EB/OL].https://blog.csdn.net/u013841196/article/details/80956828,2018-07-08.
[2] AI之路.图像对抗算法-攻击篇(I-FGSM)[EB/OL].https://blog.csdn.net/u014380165/article/details/90724000?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4,2019-05-31.
[3] 机器之心.综述论文:对抗攻击的12种攻击方法和15种防御方法[EB/OL].https://www.jiqizhixin.com/articles/2018-03-05-4,2018-03-05.
[4] PaperWeekly.一文读懂文本处理中的对抗训练[EB/OL].https://blog.csdn.net/c9yv2cf9i06k2a9e/article/details/90986041,2019-06-05.
[5] cdpac.对抗样本与对抗训练[EB/OL].https://blog.csdn.net/cdpac/article/details/53170940?utm_source=itdadao&utm_medium=referral,2016-12-07.