1、模拟搭建3个节点的分布式运行环境
2、每个服务器搭建需要配置项
为每个服务器配置好相应的主机名、静态IP地址、修改网卡名等、
主机名修改:
/etc/hostname
luozheng.bigdata1
/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=luozheng.bigdata1
配置hosts,使3个服务器之间能够互联:/etc/hosts
192.168.211.129 luozheng.bigdata
192.168.211.131 luozheng.bigdata1
192.168.211.133 luozheng.bigdata2
修改网卡名:/etc/udev/rules.d/70-persistent-ipoib.rules
ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="32", ATTR{address}=="00:50:56:31:2B:D6", NAME="eth0"
配置静态IP地址:/etc/sysconfig/network-scripts/ifcfg-eth0
centos7在安装完后,原来网卡名不是叫eth0,而是叫ens33,这个怎么重命名百度下就可以。
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
##BOOTPROTO="dhcp"
BOOTPROTO="static" ###这个改成static
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="eth0"
UUID="75c3b0c8-4560-48f4-a161-7eca30e74e2a"
DEVICE="eth0"
ONBOOT="yes" ####
IPADDR="192.168.211.131"
GATEWAY="192.168.211.2"
NETMASK="255.255.255.0"
HWADDR="00:50:56:31:2B:D6"
配置完这些后,重启下机器就可以了。
3、服务在节点上分配:
| luozheng.bigdata | luozheng.bigdata1 | luozheng.bigdata2 |
|---|---|---|
| DataNode | DataNode | DataNode |
| NameNode | / | / |
| / | / | SecondaryNameNode |
| / | ResourceManager | / |
| NodeManager | NodeManager | NodeManager |
| JobHistoryServer | / | / |
4、hadoop配置文件修改
在配置之前,切记切记,hadoop相关软件、路径在每台服务器上是一致的!!!!!
在配置之前,切记切记,hadoop相关软件、路径在每台服务器上是一致的!!!!!
在配置之前,切记切记,hadoop相关软件、路径在每台服务器上是一致的!!!!!
节点luozheng.bigdata HDFS配置:
hadoop-env.sh,主要配置java环境变量和hadoop路径
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/home/luozheng/tools/jdk1.8.0_171
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
export HADOOP_HOME=/home/luozheng/tools/hadoop-3.0.1
# Location of Hadoop's configuration information. i.e., where this
# file is living. If this is not defined, Hadoop will attempt to
# locate it based upon its execution path.
#
# NOTE: It is recommend that this variable not be set here but in
# /etc/profile.d or equivalent. Some options (such as
# --config) may react strangely otherwise.
#
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
core-site.xml配置:namenode相关配置
fs.defaultFS
hdfs://luozheng.bigdata:9000
hadoop.tmp.dir
/home/luozheng/hadoop/tmp
fs.trash.interval
10080
io.file.buffer.size
4096
hdfs-site.xml:配置secondaryNameNode进程运行所在服务器
dfs.namenode.secondary.http-address
luozheng.bigdata2:9868
works:配置datanode节点服务器
luozheng.bigdata
luozheng.bigdata1
luozheng.bigdata2
配置yarn的resourcemanager
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
luozheng.bigdata1
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
配置mapreducer的historyserver:
mapreduce.jobhistory.address
luozheng.bigdata:10020
mapreduce.framework.name
yarn
mapreduce.framework.name
yarn
5、ssh免密登录配置
因为namenode配置在服务器luozheng.bigdata,所以先来建立luozheng.bigdata到其他两台服务器之间的免密登录。
1)在luozheng.bigdata上通过如下命令来生成秘钥:
ssh-keygen -t rsa
执行完之后在~/.ssh目录下面应该可以看到以id开头的两个文件,一个公钥,一个私钥:
-rw-------. 1 root root 1675 4月 21 14:56 id_rsa
-rw-r--r--. 1 root root 408 4月 21 14:56 id_rsa.pub
我们把公钥id_rsa.pub拷贝一份,修改权限:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
2)通过ssh-copy-id指令把秘钥拷贝到其他两台机器上:
ssh-copy-id luozheng.bigdata1
ssh-copy-id luozheng.bigdata2
在配置完这些之后,通过ssh指令登录到其他两台服务器就不要输入密码了。

用同样的方式来建立resourcemanager到另外两台服务器之间的连接。
补充:这里加一个配置,使得终端能够显示出完整的用户名和hostname,主要是修改/etc/bashrc文件:
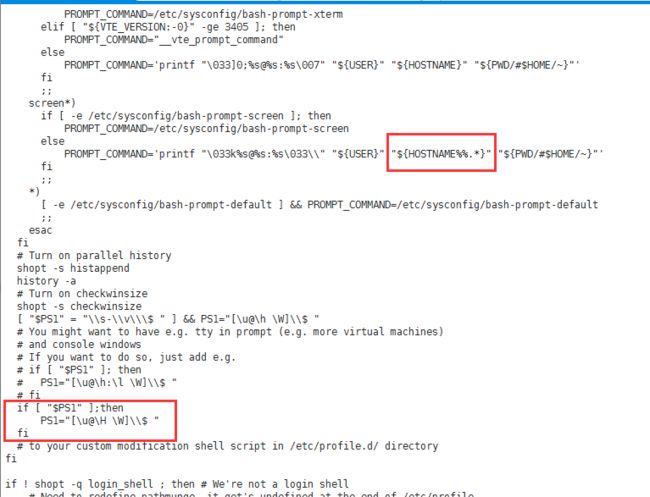
主要是加上下面这段:
if [ "$PS1" ];then
PS1="[\u@\H \W]\\$ "
fi
6、hadoop文件分发到其他服务器
对于luozheng.bigdata这台服务器,hadoop相关配置已经完毕,在分发到其他服务器之前,先删除hadoop-3.0.1/share/doc这个文件夹,减少分发时间
scp -r hadoop-3.0.1 [email protected]:~/tools/
scp -r hadoop-3.0.1 [email protected]:~/tools/
7、hadoop hdfs启动
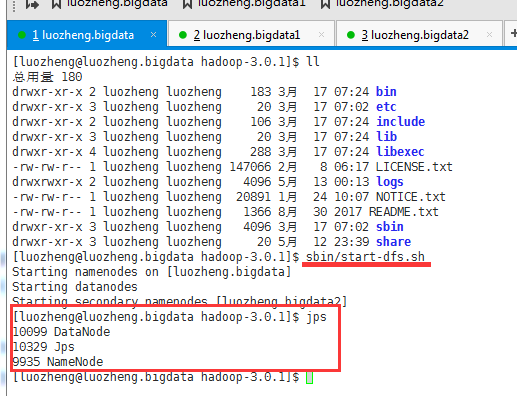
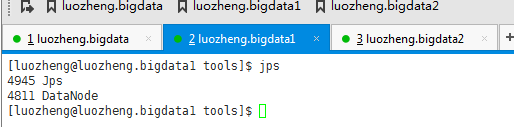
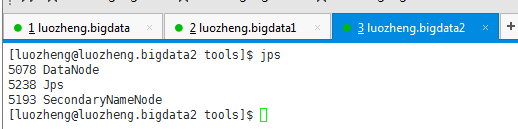
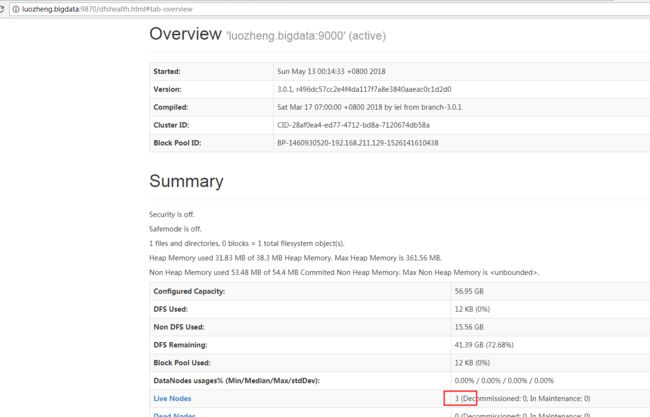
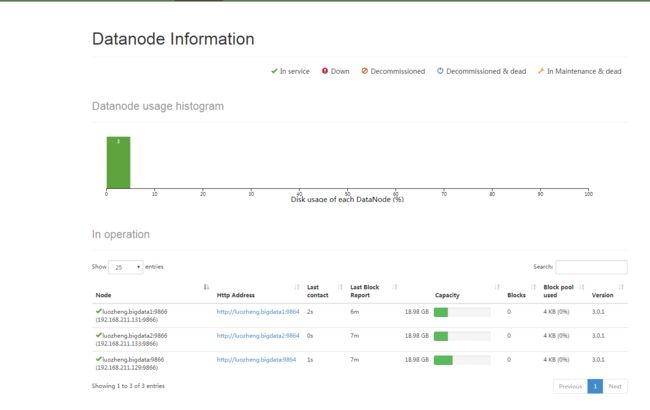
在http:// luozheng.bigdata:9870/中也能看到相关信息: