(一)Spark——基础
目录
- 一、Spark 概述
- 1. 什么是Spark
- 2. Spark 特点
- 3. Spark 内置模块介绍
- 二、Spark 部署模式
- 1. 下载Spark
- 2. 集群角色
- 2.1 Master 和 Worker
- 2.1.1 Master
- 2.1.2 Worker
- 2.2 Driver 和 Executor
- 2.2.1 Driver(驱动器)
- 2.2.2 Executor(执行器)
- 3. Local模式
- 3.1 解压Spark 安装包
- 3.2 运行一下官方的jar包测试一下
- 3.3 使用Spark-shell
- 3.4 WordCount数据流程分析
- 4. Standalone 模式
- 4.1 配置Standalone模式
- 4.2 Standalone 模式下配置 Spark 任务历史服务器
- 4.3 Standalone 模式配置HA
- 4.4 Standalone 运行模式简单讲解
- 5. Yarn 模式
- 5.1 Yarn 模式在Cluster模式下提交流程
- 5.2 Yarn 模式配置
- 5.3 配置yarn 的UI直接点击History跳转到spark的历史服务器UI
一、Spark 概述
1. 什么是Spark
Spark是一个快速(基于内存),通用,可扩展的集群计算引擎。并且Spark目前已经成为 Apache 最活跃的开源项目, 有超过 1000 个活跃的贡献者.
http://spark.apache.org/
http://spark.apache.org/history.html
2. Spark 特点
-
快速
与 Hadoop 的 MapReduce 相比, Spark 基于内存的运算是 MapReduce 的 100 倍.基于硬盘的运算也要快 10 倍以上.
Spark 实现了高效的 DAG 执行引擎, 可以通过基于内存来高效处理数据流。

-
易用
Spark 支持 Scala, Java, Python, R 和 SQL 脚本, 并提供了超过 80 种高性能的算法, 非常容易创建并行 App
而且 Spark 支持交互式的 Python 和 Scala 的 shell, 这意味着可以非常方便地在这些 shell 中使用 Spark 集群来验证解决问题的方法, 而不是像以前一样 需要打包, 上传集群, 验证等. 这对于原型开发非常重要. -
通用
Spark 结合了SQL, Streaming和复杂分析.
Spark 提供了大量的类库, 包括 SQL 和 DataFrames, 机器学习(MLlib), 图计算(GraphicX), 实时流处理(Spark Streaming) .
可以把这些类库无缝的柔和在一个 App 中.
减少了开发和维护的人力成本以及部署平台的物力成本.

-
可融合性
Spark 可以非常方便的与其他开源产品进行融合.
比如, Spark 可以使用 Hadoop 的 YARN 和 Appache Mesos 作为它的资源管理和调度器, 并且可以处理所有 Hadoop 支持的数据, 包括 HDFS, HBase等.
3. Spark 内置模块介绍
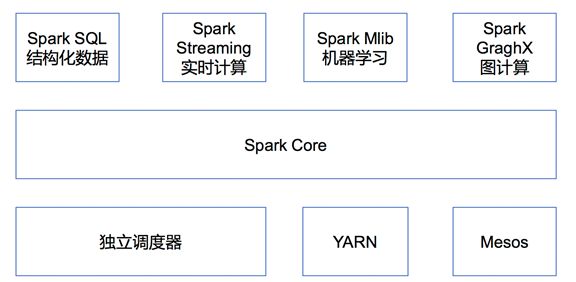
集群管理器(Cluster Manager)
Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(Cluster Manager)上运行,目前 Spark 支持 3 种集群管理器:
- Hadoop YARN(在国内使用最广泛)
- Apache Mesos(国内使用较少, 国外使用较多)
- Standalone(Spark 自带的资源调度器, 需要在集群中的每台节点上配置 Spark)
SparkCore
实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。SparkCore 中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL
是 Spark 用来操作结构化数据的程序包。通过SparkSql,我们可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming
是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib
提供常见的机器学习 (ML) 功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
Spark 得到了众多大数据公司的支持,这些公司包括 Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。
当前百度的 Spark 已应用于大搜索、直达号、百度大数据等业务;
阿里利用 GraphX 构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;
腾讯Spark集群达到 8000 台的规模,是当前已知的世界上最大的 Spark 集群。
二、Spark 部署模式
1. 下载Spark
- 官网地址 http://spark.apache.org/
- 文档查看地址 https://spark.apache.org/docs/2.1.1/
- 下载地址 https://archive.apache.org/dist/spark/
目前最新版本应该是2.4.4,不过这里还是选择2.1.1来搭建,2.x.x 的版本差别都不大。
2. 集群角色
2.1 Master 和 Worker
Master和Worker就是上面所说的spark自带资源调度器(standalone模式)的组件,yarn模式就没有Master和Worker了,就是ResourceManager和NodeManager了。
2.1.1 Master
Spark 特有资源调度系统的 Leader。掌管着整个集群的资源信息,类似于 Yarn 框架中的 ResourceManager,主要功能:
- 监听 Worker,看 Worker 是否正常工作;
- Master 对 Worker、Application 等的管理(接收 Worker 的注册并管理所有的Worker,接收 Client 提交的 Application,调度等待的 Application 并向Worker 提交)。
2.1.2 Worker
Spark 特有资源调度系统的 Slave,有多个。每个 Slave 掌管着所在节点的资源信息,类似于 Yarn 框架中的 NodeManager,主要功能:
- 通过 RegisterWorker 注册到 Master;
- 定时发送心跳给 Master;
- 根据 Master 发送的 Application 配置进程环境,并启动 ExecutorBackend(执行 Task 所需的临时进程)
2.2 Driver 和 Executor
2.2.1 Driver(驱动器)
Spark 的驱动器是执行开发程序中的 main 方法的线程。
它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行。如果你是用Spark Shell,那么当你启动Spark shell的时候,系统后台自启了一个Spark驱动器程序,就是在Spark shell中预加载的一个叫作 sc 的SparkContext对象。如果驱动器程序终止,那么Spark应用也就结束了。主要负责: 1. 将用户程序转化为作业(Job); 2. 在Executor之间调度任务(Task); 3. 跟踪Executor的执行情况; 4. 通过UI展示查询运行情况。
2.2.2 Executor(执行器)
Spark Executor是一个工作节点,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。主要负责:
1.负责运行组成 Spark 应用的任务,并将状态信息返回给驱动器程序;
2.通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor内的,因此任务可以在运行时充分利用缓存数据加速运算。
总结:Master 和 Worker 是 Spark 的守护进程,即 Spark 在特定模式下正常运行所必须的进程。Driver 和 Executor 是临时程序,当有具体任务提交到 Spark 集群才会开启的程序。
3. Local模式
Local模式就是指的只在一台计算机上运行Spark。但是它其实使用了多线程模拟了分布式,所以基本上local模式上运行没有问题的代码,一般到了其他模式也不会出现什么太大的问题。
通常用于测试的目的来使用 Local 模式,实际的生产环境中不会使用 Local 模式。
3.1 解压Spark 安装包
把安装包上传到/opt/software/下, 并解压到/opt/module/目录下
[fseast@hadoop102 software]$ tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
把解压出来的文件夹拷贝一份做Local模式的使用:
[fseast@hadoop102 module]$ cp -r spark-2.1.1-bin-hadoop2.7/ spark-local
Local模式的话就不需要做配置
3.2 运行一下官方的jar包测试一下
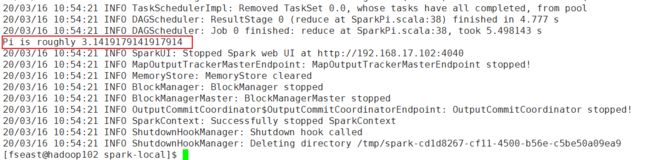
[fseast@hadoop102 spark-local]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ./examples/jars/spark-examples_2.11-2.1.1.jar 100
--class 就是指定跑的那个程序的全类名
--master 就是运行的是什么模式,local[2] 里面的2是用多少个核心去跑,也可以用*号,*的意思就是尽量多的核心。
然后接着jar包的位置,然后是程序的参数
当然这里只用到了部分参数,其余参数后面详细说。
运行出来的结果:
3.3 使用Spark-shell
Spark-shell 是 Spark 给我们提供的交互式命令窗口(类似于 Scala 的 REPL)
 spark还提供了一个UI界面,可以使用4040端口查看。
spark还提供了一个UI界面,可以使用4040端口查看。
- 可以在spark-shell里面写一个WordCount的程序,先创建一个文本文件输入一些单词:
[fseast@hadoop102 spark-local]$ mkdir input
[fseast@hadoop102 spark-local]$ cd input/
[fseast@hadoop102 input]$ vim 1.tx
hello fseast fseast
hello spark
input spark
[fseast@hadoop102 input]$ vim 2.txt
fseast spark
hello input
- 写个WordCount程序:
scala> val rdd1 =sc.textFile("./input").flatMap(_.split("\\W+")).map((_,1)).reduceByKey(_+_)
scala> rdd1.collect
collect collectAsMap collectAsync
scala> rdd1.collect
res0: Array[(String, Int)] = Array((fseast,3), (hello,3), (spark,3), (input,2))
scala>
去UI界面看一下:
发现多了一个job,其实job就跟行动算子(Action)有关,刚才的collect就是行动算子,后面会说,一个行动算子就是一个job。
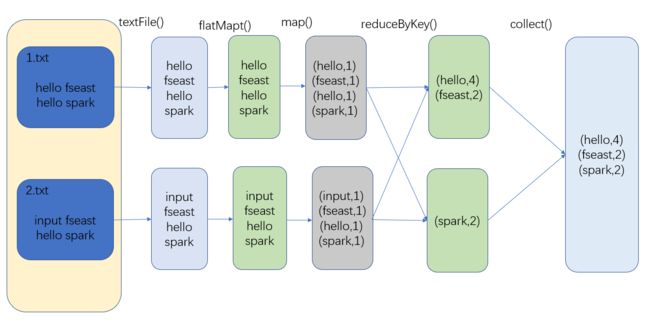
3.4 WordCount数据流程分析
- textFile(“input”):读取本地文件input文件夹数据;
- flatMap(_.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词;
- map((_,1)):对每一个元素操作,将单词映射为元组;
- reduceByKey(_+_):按照key将值进行聚合,相加;(shuffle阶段)
- collect:将数据收集到Driver端展示。
4. Standalone 模式
Standalone:构建一个基于Mster+Slaves的资源调度集群,Spark任务提交给Master运行。是Spark自身的一个调度系统。
4.1 配置Standalone模式
- 把之前解压的spark复制一份:
[fseast@hadoop102 module]$ cp -r spark-2.1.1-bin-hadoop2.7/ spark-standalone
- 进入配置文件目录conf,配置 spark-env.sh 文件:
[fseast@hadoop102 spark-standalone]$ cd conf/
[fseast@hadoop102 conf]$ cp spark-env.sh.template spark-env.sh
[fseast@hadoop102 conf]$ vim spark-env.sh
在spark-env.sh文件中加上如下内容:
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077 # 默认端口就是7077, 可以省略不配
- 修改slaves配置文件,添加worker节点:
[fseast@hadoop102 conf]$ cp slaves.template slaves
[fseast@hadoop102 conf]$ vim slaves
把slaves文件中最后一行的 localhost删除然后添加你的worker节点主机名:
hadoop102
hadoop103
hadoop104
- 分发配置好的spark:
[fseast@hadoop102 module]$ xsync spark-standalone
集群分发脚本可以参考这里
- 启动集群:
必须要在master节点启动脚本:
[fseast@hadoop102 spark-standalone]$ sbin/start-all.sh
查看进程:
[fseast@hadoop102 spark-standalone]$ alljps
--------------hadoop102---------
6944 Jps
6837 Worker
6748 Master
--------------hadoop103---------
5776 Jps
5708 Worker
--------------hadoop104---------
6389 Worker
6458 Jps
master和worker就启起来了。
如果要停止集群:(也是要在master节点执行)
[fseast@hadoop102 spark-standalone]$ sbin/stop-all.sh
- 启动以后可以去UI查看:
http://hadoop102:8080
这个8080是spark资源管理器的Master的页面UI,就是要启动spark集群才会有这个UI。和4040不一样,4040是运用程序的UI,有应用程序(spark-submit)就会有4040对应的UI。4040页面是要启动Spark Context或者Spark Session才会有,例如启动一个spark-shell(spark-shell其实也是spark-submit)就会启动spark context和spark session。
既然有Master的页面UI,那么也有worker的UI:8081端口
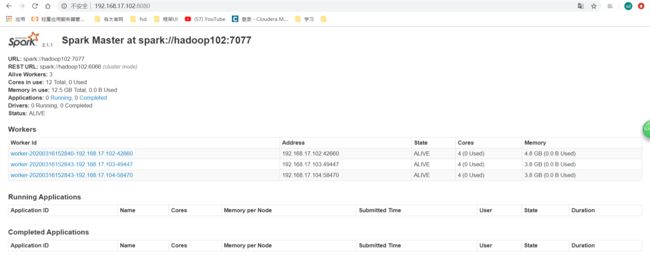
- 使用Standalone模式提交运行spark自带的运行计算PI的程序:
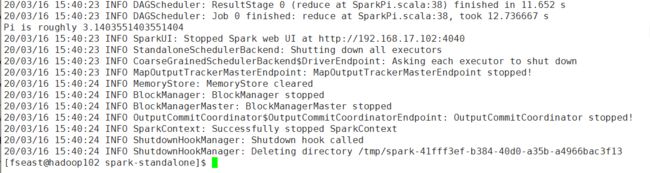
[fseast@hadoop102 spark-standalone]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 ./examples/jars/spark-examples_2.11-2.1.1.jar 10
此时的–master参数对应的值就变了。
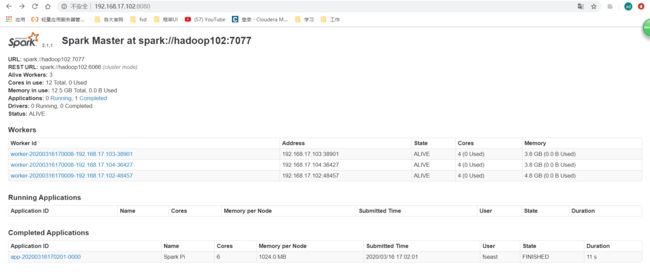
提交命令还可以有其他参数:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 6 \
--executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
–executor-memory 一个executor分配多少内存。
–total-executor-cores 所有executor总共分配多少个计算核心。
–executor-cores 一个executor分配多少个计算核心。所以这里能看出来这个脚本会启动三个executor(6/2=3)。
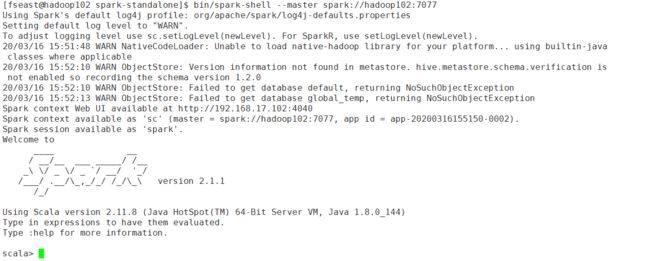
- 在standalone模式下启动一个spark-shell:
[fseast@hadoop102 spark-standalone]$ bin/spark-shell --master spark://hadoop102:7077
- Standalone模式下运行WordCount程序:
先把之前local运行时创建的input拷贝到standalone的目录下:
[fseast@hadoop102 spark-local]$ cp -r input/ ../spark-standalone/
运行:
scala> val rdd1 =sc.textFile("./input").flatMap(_.split("\\W+")).map((_,1)).reduceByKey(_+_).collect()
发现报错:
java.io.FileNotFoundException: File file:/opt/module/spark-standalone/input/1.txt does not exist
已经拷贝了为什么还会报没有这个文件的错呢?
因为现在是集群模式啊,有三个worker,你现在只有第一个worker上有这个文件,如果master把工作分给了第二第三个worker的时候,他们读这个路径是不是读不到文件,所以还要发input分发到其他两个worker中:
[fseast@hadoop102 spark-standalone]$ xsync input/
分发完了以后再运行就可以了:
scala> val rdd1 =sc.textFile("./input").flatMap(_.split("\\W+")).map((_,1)).reduceByKey(_+_).collect()
rdd1: Array[(String, Int)] = Array((fseast,3), (hello,3), (spark,3), (input,2))
scala>
再去应用程序UI4040端口再看一下:
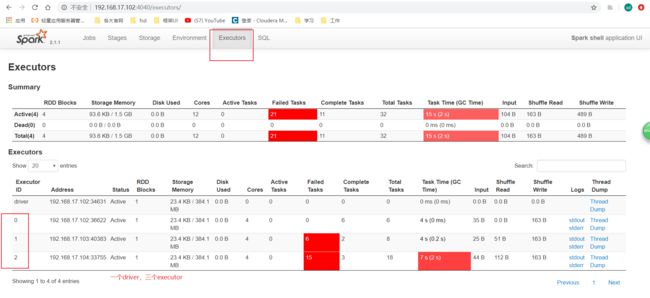
去集群Master的UI看看:
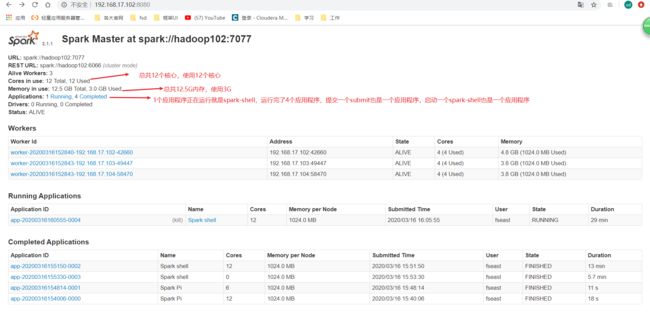 status: VLIVE就说明你的状态还活的。
status: VLIVE就说明你的状态还活的。
workers: 就是你的三个worker
running applications: 就是正在运行的应用程序。
completed applications: 就是已经完成的应用程序。
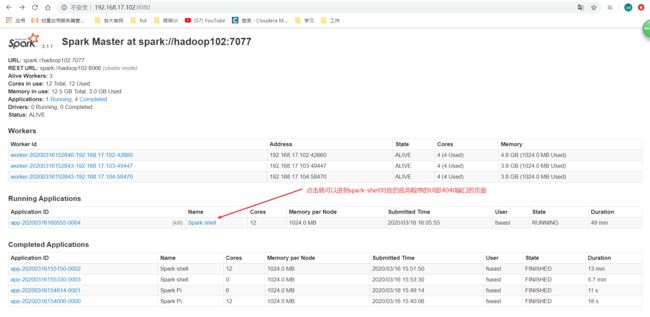 像spark-shell这种窗口式的客户端一直开着一个应用程序,可以去4040端口查看它的应用程序UI,但是像spark-submit提交一个应用程序,很快就跑完了,那跑完了就看不到刚才提交的应用的程序UI包括里面的信息DAG图什么的,这样就很不好,所以就需要配置历史服务器。
像spark-shell这种窗口式的客户端一直开着一个应用程序,可以去4040端口查看它的应用程序UI,但是像spark-submit提交一个应用程序,很快就跑完了,那跑完了就看不到刚才提交的应用的程序UI包括里面的信息DAG图什么的,这样就很不好,所以就需要配置历史服务器。
4.2 Standalone 模式下配置 Spark 任务历史服务器
在 Spark-shell 没有退出之前, 我们是可以看到正在执行的任务的日志情况:http://hadoop102:4040. 但是退出 Spark-shell 之后, 执行的所有任务记录全部丢失.
所以需要配置任务的历史服务器, 方便在任何需要的时候去查看日志
- 配置 spark-default.conf 文件,开启log
[fseast@hadoop102 conf]$ cp spark-defaults.conf.template spark-defaults.conf
[fseast@hadoop102 conf]$ vim spark-defaults.conf
在配置文件 spark-defaults.conf 添加如下内容:
spark.master spark://hadoop102:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:9000/spark-job-log
注意:
hdfs://hadoop102:9000/spark-job-log 目录必须提前存在, 名字随意
- 配置 spark-env.sh 文件,添加如下配置:
[fseast@hadoop102 conf]$ vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/spark-job-log"
第一个参数是端口,第二个是保存时间 30天,第三个是保存数据的路径,
分发文件:
[fseast@hadoop102 spark-standalone]$ xsync conf/
然后在hdfs上创建spark-job-log目录:
[fseast@hadoop102 conf]$ hadoop fs -mkdir /spark-job-log
- 重启spark集群:
[fseast@hadoop102 spark-standalone]$ sbin/stop-all.sh
[fseast@hadoop102 spark-standalone]$ sbin/start-all.sh
- 启动历史服务器:
[fseast@hadoop102 spark-standalone]$ sbin/start-history-server.sh
然后再提交一个程序看看:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 6 \
--executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
然后在网页打开:http://hadoop102:4040 还是打不开。
打开历史服务UI:http://hadoop102:18080
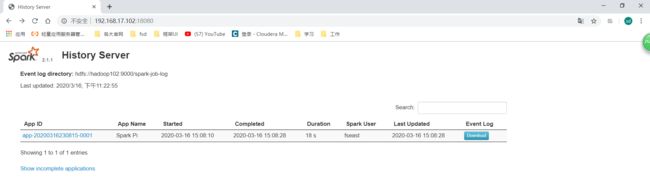 点击对应的程序ID进去以后就跟4040应用程序UI一样了。
点击对应的程序ID进去以后就跟4040应用程序UI一样了。
这里还有一个小疑问,为什么我们在应用程序UI都看不到driver的日志呢,只能看到worker端的日志,如下图:
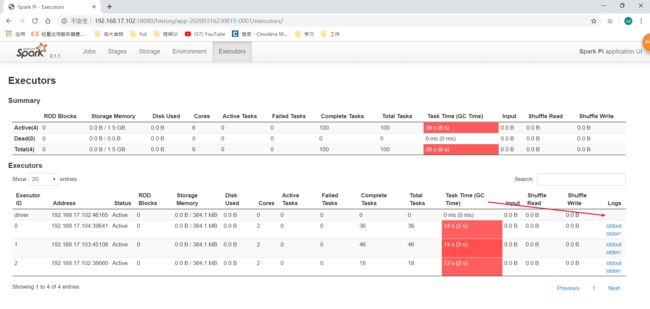
Client模式与Cluster模式的区别
这就跟我们提交程序的参数有关,还有一个 --deploy-mode参数,默认值是client,client就是你在哪个客户端提交程序(spark-submit),那driver就在哪里运行,所以我们提交应用程序时打印的一大堆日志就是driver的日志。既然这样其实也会有这样的情况:也就是假如我的集群是可以在外网连接的,那别的我不认识的人安装了spark的集群的随便一台节点,都可以提交任务到我这里来,只要–master 参数对应的是我的地址就行,如果他没有改–deploy-mode参数,那driver就会运行在他提交任务的那台节点上,然后我这里的节点就是executor端。
既然–deploy-mode默认值是client,那我们也可以设置为cluster,cluster的意思就是让driver运行在集群中,也就是由master来选一台worker端来运行driver。
那我们试一下:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 6 \
--executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
提交完以后发现和以前输出不一样了,没加这个参数的时候是一直输出,现在是这样,因为它作为一个客户端提交完以后之后的事情就不归它管了,没加这个参数的时候它自己就是driver,driver要等所有executor跑完才能停,要实时收集executor信息,所以一直输出日志。现在作为客户端只负责提交程序就可以了:
去历史服务器看:
http://hadoop102:18080
然后点击:
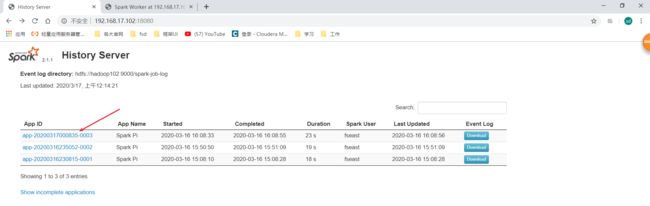
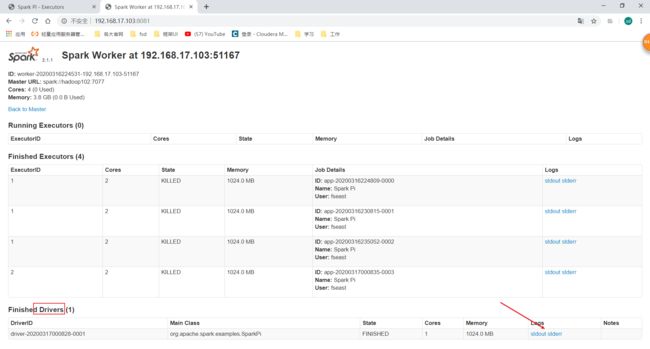
发现还是没有直接点进去的连接,不知道是不是spark UI的bug还是没有考虑这一点。但是我们想看driver日志可以这样,可以在这里看到driver运行在哪个worker端上,那我们直接去对应worker的UI界面:
http://192.168.17.103:8081/
这里就有对应的driver的日志了:
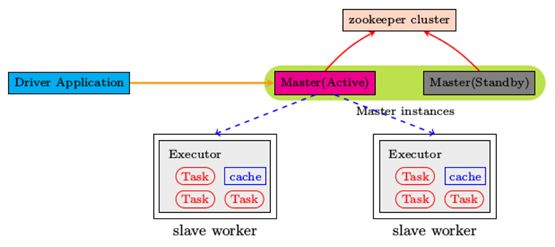
4.3 Standalone 模式配置HA
现在Master只有一个,所以也存在单点故障的问题。
可以启动多个master,先启动的除于Active状态,其他的都处于Standby状态。
- 修改配置文件 spark-env.sh :
[fseast@hadoop102 spark-standalone]$ vim conf/spark-env.sh
# 注释掉如下内容:
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
# 添加上如下内容:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop102:2181,hadoop103:2181,hadoop104:2181 -Dspark.deploy.zookeeper.dir=/spark01"
![]()
就是加了一个Zookeeper的地址,后面那个spark01是在Zookeeper上创建的Znode名称。
- 分发配置文件
[fseast@hadoop102 spark-standalone]$ xsync conf/
-
启动Zookeeper
-
重启spark
[fseast@hadoop102 spark-standalone]$ sbin/stop-all.sh
[fseast@hadoop102 spark-standalone]$ sbin/start-all.sh
查看进程:
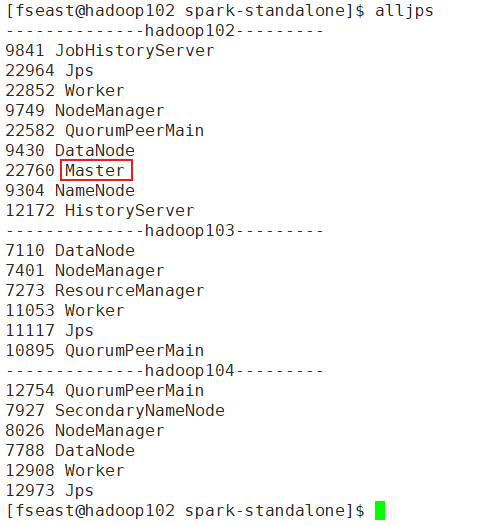
这里和hadoop的不一样,现在是只起了一个Master,其他的Master需要你自己手动启动,启动多少个都可以,不过现在活跃的只有当前的这个:
那我就在hadoop103再起一个Master:
[fseast@hadoop103 spark-standalone]$ sbin/start-master.sh
再次查看进程:
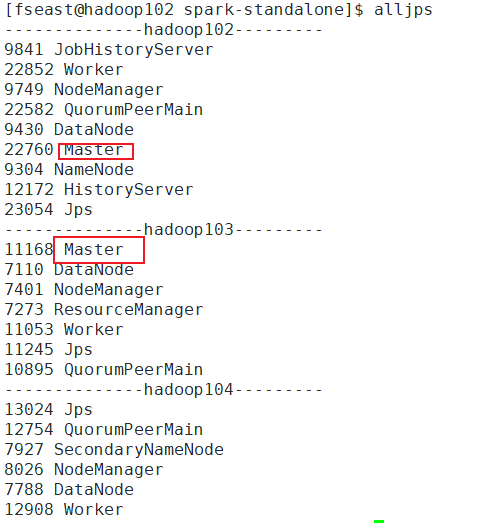
去Master端口验证:
http://192.168.17.102:8080/
http://192.168.17.103:8080/
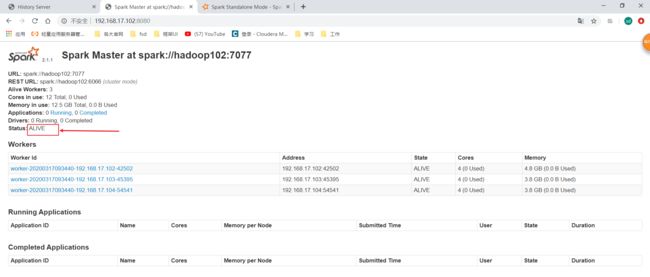
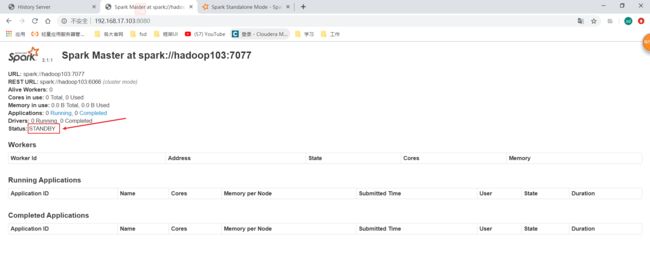
现在就可以看到两个Master了,如果你高兴现在你可以在hadoop104再开一个Master。不过只有一个是活着的(alive),另一个standby状态是获取不到Worker的信息的,Worker注册也不会向standby 的master注册。standby状态的只能等活着的挂了就可以变成活的了。
4.4 Standalone 运行模式简单讲解
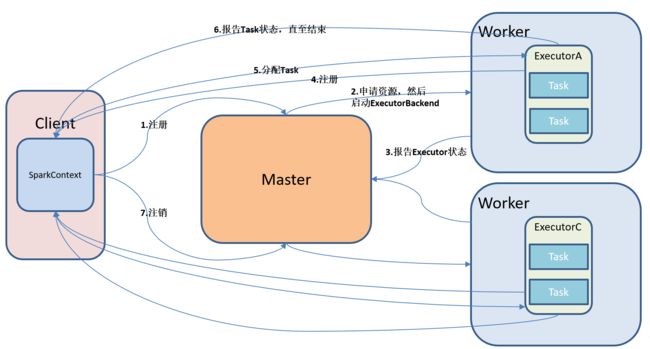
这里假设它是Client模式(也就是Driver就在这个Client上),在Client提交代码,然后代码里面会初始化一个SparkContext,SparkContext去向Master注册一个应用(Application),Master会根据它掌握的Worker的信息,给这些Worker申请资源,然后在这些Worker上启动ExecutorBackend进程(我们通常说的Executor就是这个),在这个进程里边会有Executor对象,然后Worker会向Master报告Executor的状态,然后Executor会向Driver做一个反向注册,这个注册的目的是Executor执行什么执行到哪里了等等这些信息要向Driver汇报,Driver会收集这些信息,然后在UI上可以展示出来。注册成功之后Driver开始给Executor分配任务(Task),分配任务的这部分其实称作任务调度。Executor执行任务的时候,最小的执行单元就是一个Task,一个Task其实就是一个分区,因为我们的数据很大,然后把数据切成很多切片,一个切片就是一个Spark的分区,一个分区会启动一个Task。
5. Yarn 模式
Spark 客户端可以直接连接 Yarn,不需要额外构建Spark集群。
有 yarn-client 和 yarn-cluster 两种模式,主要区别在于:Driver 程序的运行节点不同。
• yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
• yarn-cluster:Driver程序运行在由 RM(ResourceManager)启动的 AM(AplicationMaster)上, 适用于生产环境。
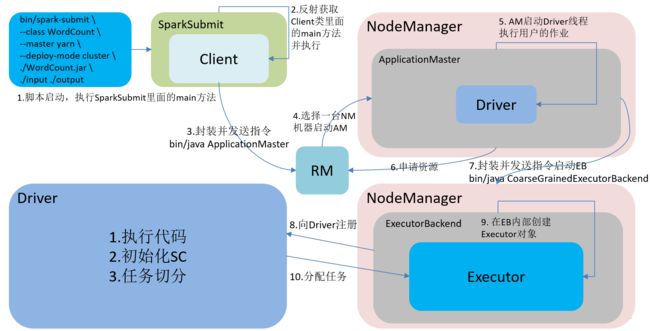
5.1 Yarn 模式在Cluster模式下提交流程
- 通过脚本启动,执行SparkSubmit 类里面的main方法 ;
- 在SparkSubmit 的main方法里面反射获取Client 类并执行里面的main方法;
- 在Client类的main方法发送启动 ApplicationMaster指令,让ResourceManager启动AM,就是交到Yarn的容器中启动;
- 然后ResourceManager会选择一台NodeManager来启动ApplicationMaster,
- 然后在ApplicationMaster进程中启动一个Driver线程,在runDriver里面最重要是反射出用户类的main方法,然后执行用户类,执行用户类主要就是执行代码、初始化SparkContext、任务切分。
- ApplicationMaster还会去启动一个ExecutorBackend进程,
- ExecutorBackend先去向Driver进行反向注册,注册的目的就是Executor执行的进度啊什么的要实时通知Driver,Driver则要收集Executor的这些执行信息;
- 注册完了之后再去创建Executor对象;
- 然后Driver就可以给Executor分配任务了。
5.2 Yarn 模式配置
- 复制spark,并命名为spark-yarn
[fseast@hadoop102 module]$ cp -r spark-2.1.1-bin-hadoop2.7/ spark-yarn
- 修改spark-evn.sh文件:
[fseast@hadoop102 module]$ cd spark-yarn
[fseast@hadoop102 spark-yarn]$ cd conf/
[fseast@hadoop102 conf]$ cp spark-env.sh.template spark-env.sh
[fseast@hadoop102 conf]$ vim spark-env.sh
添加如下内容:
第一行是历史服务的配置,和standalone模式的一样,
第二行就是告诉yarn配置文件的路径
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/spark-job-log"
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
- 配置 spark-default.conf 文件,开启log:
这里为了配置历史服务器的,和上面standalone模式的配置方式一样
[fseast@hadoop102 conf]$ cp spark-defaults.conf.template spark-defaults.conf
[fseast@hadoop102 conf]$ vim spark-defaults.conf
在配置文件 spark-defaults.conf 添加如下内容:
spark.master spark://hadoop102:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:9000/spark-job-log
- 启动hadoop,包括hdfs,yarn,hadoop历史服务器
- 启动spark的历史服务器
[fseast@hadoop102 spark-yarn]$ sbin/start-history-server.sh
不需要分发spark-yarn,因为你在hadoop102 的spark-yarn仅仅是一个客户端,是一个提交应用程序的客户端,真正运行在跑的是yarn,所以有一个客户端进行spark-submit就足够了,除非你还想要在hadoop103或者104也可以进行提交spark应用。否者只需要在一台机器安装一个客户端足够了。
这里还有一个面试题:
如果使用yarn模式运行spark,集群需要spark的环境吗?
集群不需要,只要你提交任务的那个客户端有spark的环境就可以了,客户端会通过jar包把需要的环境、代码什么的发到yarn集群上。
- 跑一下官方的程序:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
去yarn的UI看一下:
http://192.168.17.103:8088
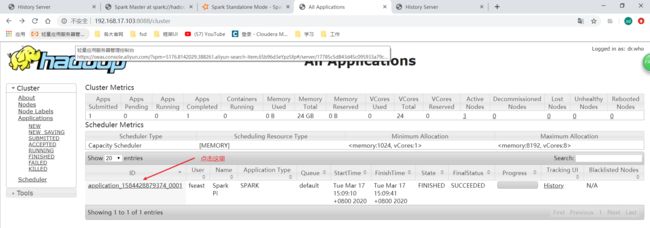
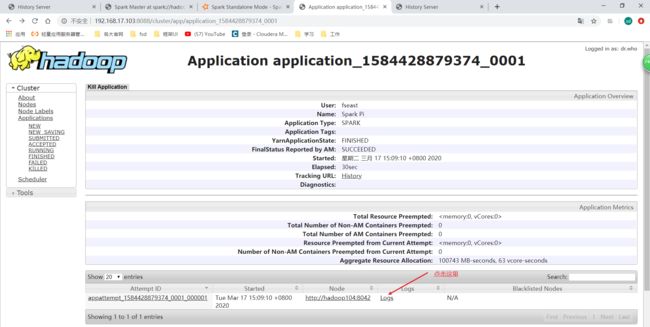
就可以跳转到对应的日志页面位置:
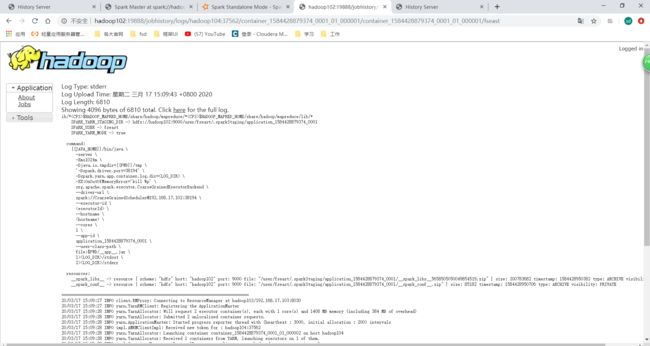
如果你的跳转不了的话,确保yarn的配置文件yarn-site.xml中添加如下配置:
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
如果你的配置文件都用这种主机名的方式,你还要在你浏览器所在的电脑配置hosts文件:
192.168.7.102 hadoop101
192.168.7.103 hadoop103
192.168.7.104 hadoop104
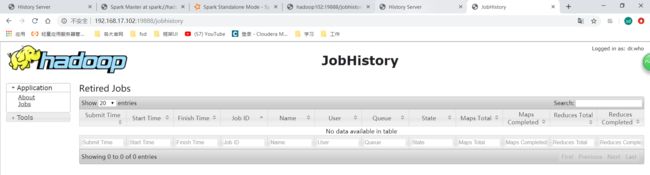
我们在hadoop的历史服务器看:
http://192.168.17.102:19888
这里是看不到spark跑的历史的
我们再去spark历史服务器UI看:
http://192.168.17.102:18080/
这里可以看到
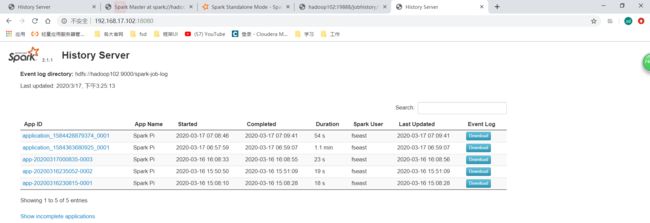
5.3 配置yarn 的UI直接点击History跳转到spark的历史服务器UI
但是我们每次都要打开spark历史服务器UI这里才能看到可能不太方便,我们希望在yarn的UI点击History可以跳转到spark的历史服务器18080去,现在发现点了不行。
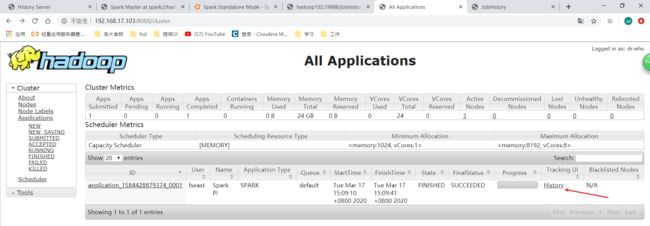
点击之后发现还是跳到这里:
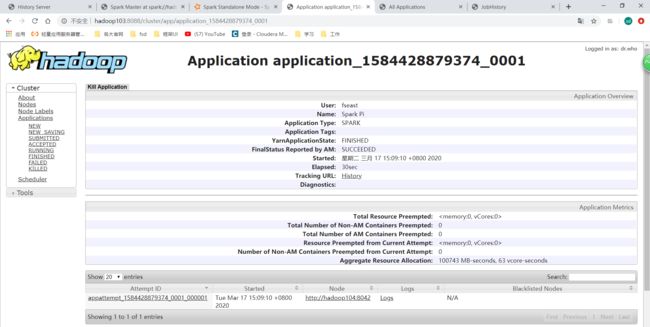
所以要做一个跳转关联,可以直接从yarn的History跳转到spark的历史服务器。需要做一些配置:
修改spark-default.conf配置文件添加如下配置达到上述目的:
[fseast@hadoop102 spark-yarn]$ vim conf/spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
配置完了以后我们再提交一个应用:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
跑完了之后我们去yarn的UI查看一下:
http://192.168.17.103:8088
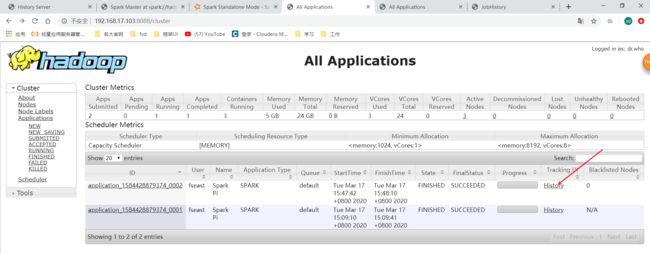 点击History,就可以直接跳转到spark的历史服务器UI了:
点击History,就可以直接跳转到spark的历史服务器UI了:
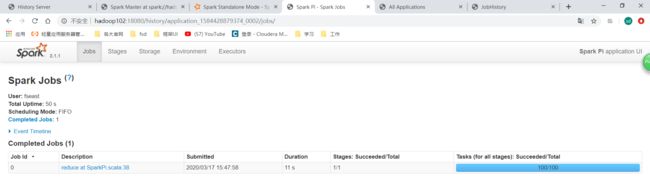
再通过cluster模式提交一个程序:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 6 \
--executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
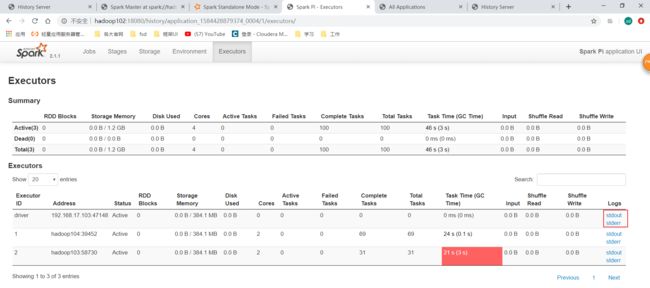
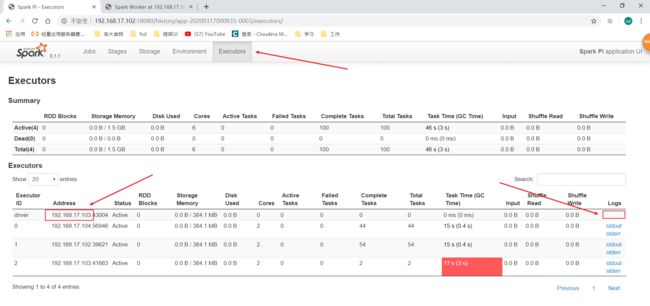
运行完之后还是在yarn的UI点击History到spark历史服务UI,然后看Executor这里:
发现driver这里也有日志了,前面的Standalone模式没有,所以可能是spark的Standalone模式的UI界面的一个bug吧。
设置了所有executor的core数量为6,每个executor的core为2,所以应该会有3个executor才对,这里看的时候只有2个Executor,在Standalone模式有时候也有这种情况,我觉得应该是跟集群资源以及运行情况有关。