重大事故!IO问题引发线上20台机器同时崩溃
几年前的一个下午,公司里码农们正在安静地敲着代码,突然很多人的手机同时“哔哔”地响了起来。本来以为发工资了,都挺高兴!打开一看,原来是告警短信
故障回顾
告警提示“线程数过多,超出阈值”,“CPU空闲率太低”。打开监控系统一看,订单服务所有20个服务节点都不行了,服务没响应。
到听云(一个全链路性能监控工具)上看监控,每个springboot节点线程数全都达到了最大值。但是JVM堆内存和GC没有明显异常。CPU 空闲率基本都是0%,但是CPU使用率并不高,反而IO等待却非常高。下面是执行top命令查看CPU状况的截图:

从上图,我们可以看到:
CPU空闲率是0%(上图中红框id)
CPU使用率是22%(上图中红框 us 13% 加上 sy 9%,us可以理解成用户进程占用的CPU,sy可以理解成系统进程占用的CPU)
CPU 在等待磁盘IO操作上花费的时间占比是76.6% (上图中红框 wa)
到现在可以确定,问题肯定发生在IO等待上。利用监控系统和jstack命令,最终定位问题发生在文件写入上。大量的磁盘读写导致了系统线程资源耗尽。最终导致订单服务无法响应上游服务的请求。
IO,你不知道的那些事儿
既然IO对系统性能和稳定性影响这么大,我们就来深入探究一下。
所谓的I/O(Input/Output)操作实际上就是输入输出的数据传输行为。程序员最关注的主要是磁盘IO和网络IO,因为这两个IO操作和应用程序的关系最直接最紧密。
磁盘IO:磁盘的输入输出,比如磁盘和内存之间的数据传输。
网络IO:不同系统间跨网络的数据传输,比如两个系统间的远程接口调用。
下面这张图展示了应用程序中发生IO的具体场景:
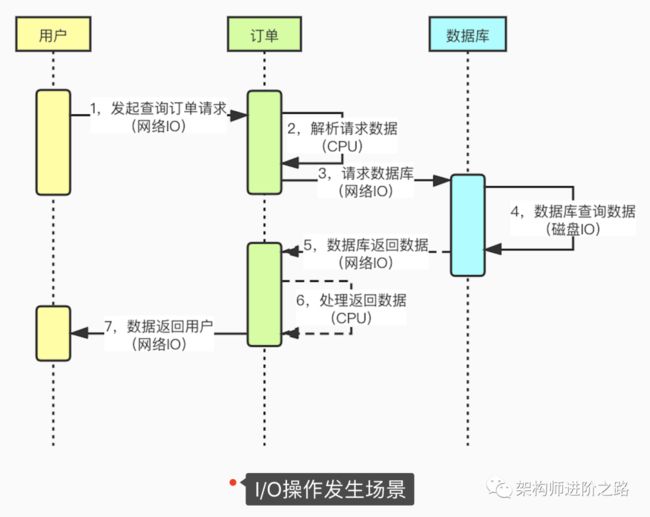
通过上图,我们可以了解到IO操作发生的具体场景。一个请求过程可能会发生很多次的IO操作:
1,页面请求到服务器会发生网络IO
2,服务之间远程调用会发生网络IO
3,应用程序访问数据库会发生网络IO
4,数据库查询或者写入数据会发生磁盘IO
IO和CPU的关系
不少攻城狮会这样理解,如果CPU空闲率是0%,就代表CPU已经在满负荷工作,没精力再处理其他任务了。真是这样的吗?
我们先看一下计算机是怎么管理磁盘IO操作的。计算机发展早期,磁盘和内存的数据传输是由CPU控制的,也就是说从磁盘读取数据到内存中,是需要CPU存储和转发的,期间CPU一直会被占用。我们知道磁盘的读写速度远远比不上CPU的运转速度。这样在传输数据时就会占用大量CPU资源,造成CPU资源严重浪费。
后来有人设计了一个IO控制器,专门控制磁盘IO。当发生磁盘和内存间的数据传输前,CPU会给IO控制器发送指令,让IO控制器负责数据传输操作,数据传输完IO控制器再通知CPU。因此,从磁盘读取数据到内存的过程就不再需要CPU参与了,CPU可以空出来处理其他事情,大大提高了CPU利用率。这个IO控制器就是“DMA”,即直接内存访问,Direct Memory Access。现在的计算机基本都采用这种DMA模式进行数据传输。
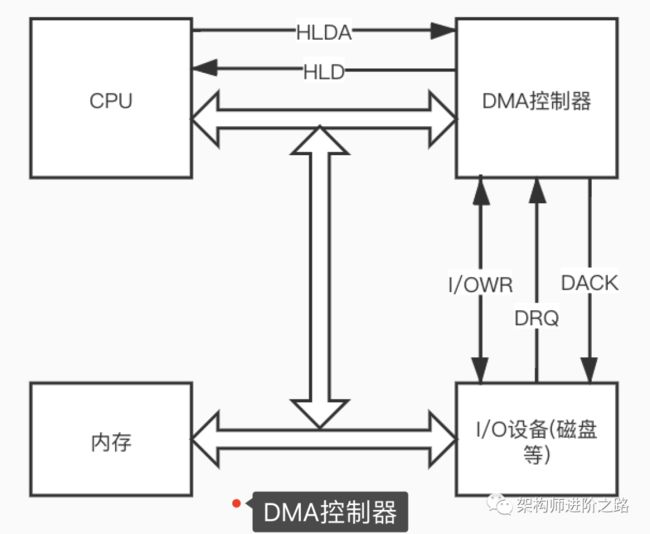
通过上面内容我们了解到,IO数据传输时,是不占用CPU的。当应用进程或线程发生IO等待时,CPU会及时释放相应的时间片资源并把时间片分配给其他进程或线程使用,从而使CPU资源得到充分利用。所以,假如CPU大部分消耗在IO等待(wa)上时,即便CPU空闲率(id)是0%,也并不意味着CPU资源完全耗尽了,如果有新的任务来了,CPU仍然有精力执行任务。如下图:
在DMA模式下执行IO操作是不占用CPU的,所以CPU IO等待(上图的wa)实际上属于CPU空闲率的一部分。所以我们执行top命令时,除了要关注CPU空闲率,CPU使用率(us,sy),还要关注IO Wait(wa)。注意,wa只代表磁盘IO Wait,不包括网络IO Wait。
Java中线程状态和IO的关系
当我们用jstack查看Java线程状态时,会看到各种线程状态。当发生IO等待时(比如远程调用时),线程是什么状态呢,Blocked还是Waiting?
答案是Runnable状态,是不是有些出乎意料!实际上,在操作系统层面Java的Runnable状态除了包括Running状态,还包括Ready(就绪状态,等待CPU调度)和IO Wait等状态。

如上图,Runnable状态的注解明确说明了,在JVM层面执行的线程,在操作系统层面可能在等待其他资源。如果等待的资源是CPU,在操作系统层面线程就是等待被CPU调度的Ready状态;如果等待的资源是磁盘网卡等IO资源,在操作系统层面线程就是等待IO操作完成的IO Wait状态。
有人可能会问,为什么Java线程没有专门的Running状态呢?
目前绝大部分主流操作系统都是以时间分片的方式对任务进行轮询调度,时间片通常很短,大概几十毫秒,也就是说一个线程每次在cpu上只能执行几十毫秒,然后就会被CPU调度出来变成Ready状态,等待再一次被CPU执行,线程在Ready和Running两个状态间快速切换。通常情况,JVM线程状态主要为了监控使用,是给人看的。当你看到线程状态是Running的一瞬间,线程状态早已经切换N次了。所以,再给线程专门加一个Running状态也就没什么意义了。
深入理解网络IO模型
5种Linux网络IO模型包括:同步阻塞IO、同步非阻塞IO、多路复用IO、信号驱动IO和异步IO。
写在前面
为了更好地理解网络IO模型,我们先了解几个基本概念。
Socket(套接字):Socket可以理解成,在两个应用程序进行网络通信时,分别在两个应用程序中的通信端点。通信时,一个应用程序将数据写入Socket,然后通过网卡把数据发送到另外一个应用程序的Socket中。我们平常所说的HTTP和TCP协议的远程通信,底层都是基于Socket实现的。5种网络IO模型也都要基于Socket实现网络通信。
阻塞与非阻塞:所谓阻塞,就是发出一个请求不能立刻返回响应,要等所有的逻辑全处理完才能返回响应。非阻塞反之,发出一个请求立刻返回应答,不用等处理完所有逻辑。
内核空间与用户空间:在Linux中,应用程序稳定性远远比不上操作系统程序,为了保证操作系统的稳定性,Linux区分了内核空间和用户空间。可以这样理解,内核空间运行操作系统程序和驱动程序,用户空间运行应用程序。Linux以这种方式隔离了操作系统程序和应用程序,避免了应用程序影响到操作系统自身的稳定性。这也是Linux系统超级稳定的主要原因。所有的系统资源操作都在内核空间进行,比如读写磁盘文件,内存分配和回收,网络接口调用等。所以在一次网络IO读取过程中,数据并不是直接从网卡读取到用户空间中的应用程序缓冲区,而是先从网卡拷贝到内核空间缓冲区,然后再从内核拷贝到用户空间中的应用程序缓冲区。对于网络IO写入过程,过程则相反,先将数据从用户空间中的应用程序缓冲区拷贝到内核缓冲区,再从内核缓冲区把数据通过网卡发送出去。
同步阻塞IO
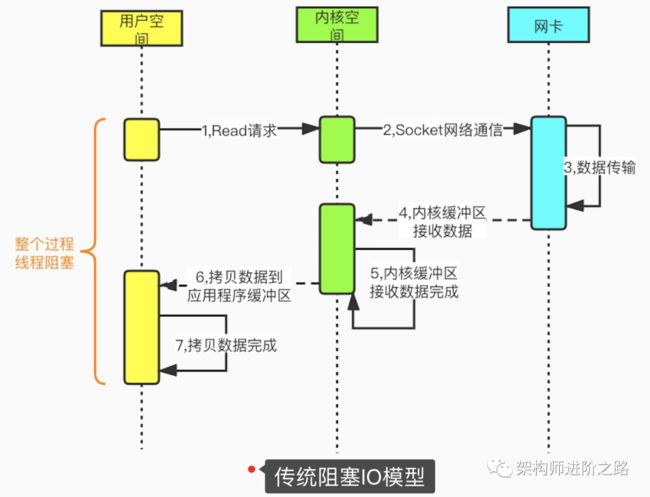
我们先看一下传统阻塞IO。在Linux中,默认情况下所有socket都是阻塞模式的。当用户线程调用系统函数read(),内核开始准备数据(从网络接收数据),内核准备数据完成后,数据从内核拷贝到用户空间的应用程序缓冲区,数据拷贝完成后,请求才返回。从发起read请求到最终完成内核到应用程序的拷贝,整个过程都是阻塞的。为了提高性能,可以为每个连接都分配一个线程。因此,在大量连接的场景下就需要大量的线程,会造成巨大的性能损耗,这也是传统阻塞IO的最大缺陷。
同步非阻塞IO
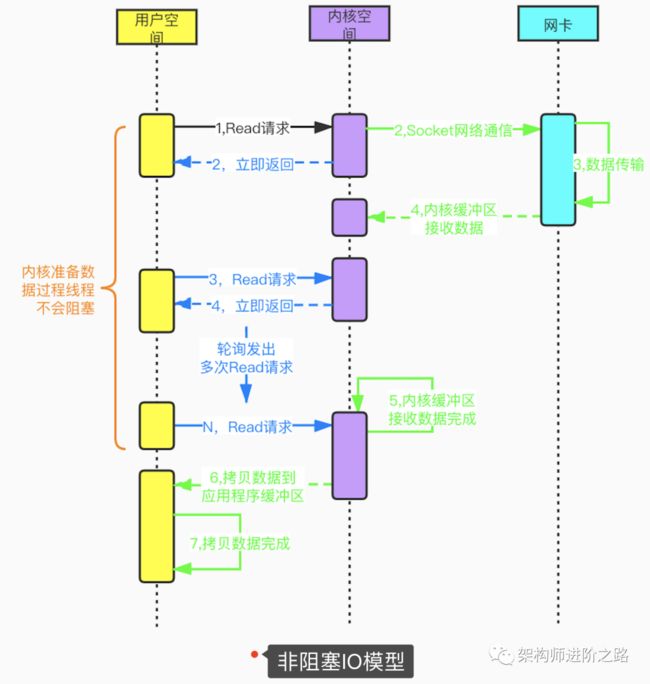
用户线程在发起Read请求后立即返回,不用等待内核准备数据的过程。如果Read请求没读取到数据,用户线程会不断轮询发起Read请求,直到数据到达(内核准备好数据)后才停止轮询。非阻塞IO模型虽然避免了由于线程阻塞问题带来的大量线程消耗,但是频繁的重复轮询大大增加了请求次数,对CPU消耗也比较明显。这种模型在实际应用中很少使用。
多路复用IO模型
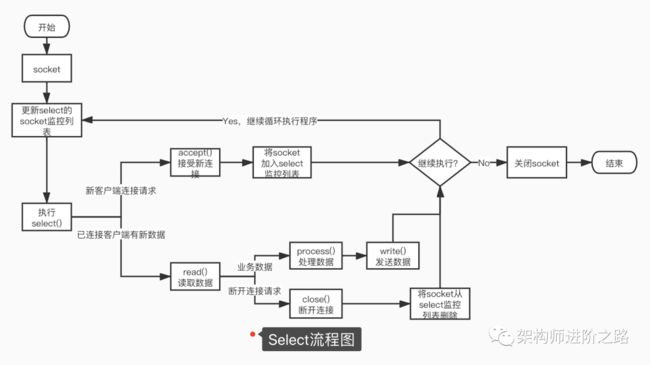
多路复用IO模型,建立在多路事件分离函数select,poll,epoll之上。在发起read请求前,先更新select的socket监控列表,然后等待select函数返回(此过程是阻塞的,所以说多路复用IO也是阻塞IO模型)。当某个socket有数据到达时,select函数返回。此时用户线程才正式发起read请求,读取并处理数据。这种模式用一个专门的监视线程去检查多个socket,如果某个socket有数据到达就交给工作线程处理。由于等待Socket数据到达过程非常耗时,所以这种方式解决了阻塞IO模型一个Socket连接就需要一个线程的问题,也不存在非阻塞IO模型忙轮询带来的CPU性能损耗的问题。多路复用IO模型的实际应用场景很多,比如大家耳熟能详的Java NIO,Redis以及Dubbo采用的通信框架Netty都采用了这种模型。
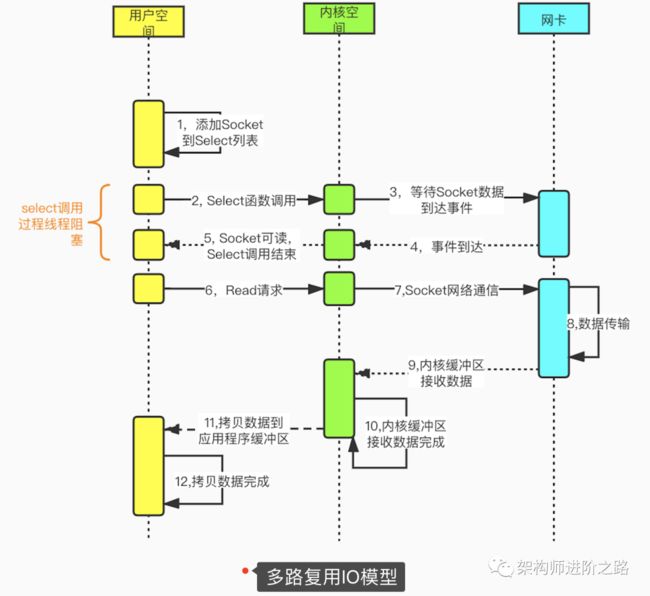
下图是基于select函数Socket编程的详细流程。
信号驱动IO模型
信号驱动IO模型,应用进程使用sigaction函数,内核会立即返回,也就是说内核准备数据的阶段应用进程是非阻塞的。内核准备好数据后向应用进程发送SIGIO信号,接到信号后数据被复制到应用程序进程。
采用这种方式,CPU的利用率很高。不过这种模式下,在大量IO操作的情况下可能造成信号队列溢出导致信号丢失,造成灾难性后果。
异步IO模型
异步IO模型的基本机制是,应用进程告诉内核启动某个操作,内核操作完成后再通知应用进程。在多路复用IO模型中,socket状态事件到达,得到通知后,应用进程才开始自行读取并处理数据。在异步IO模型中,应用进程得到通知时,内核已经读取完数据并把数据放到了应用进程的缓冲区中,此时应用进程
直接使用数据即可。
很明显,异步IO模型性能很高。不过到目前为止,异步IO和信号驱动IO模型应用并不多见,传统阻塞IO和多路复用IO模型还是目前应用的主流。Linux2.6版本后才引入异步IO模型,目前很多系统对异步IO模型支持尚不成熟。很多应用场景采用多路复用IO替代异步IO模型。
如何避免IO问题带来的系统故障
对于磁盘文件访问的操作,可以采用线程池方式,并设置线程上线,从而避免整个JVM线程池污染,进而导致线程和CPU资源耗尽。
对于网络间远程调用。为了避免服务间调用的全链路故障,要设置合理的TImeout值,高并发场景下可以采用熔断机制。在同一JVM内部采用线程隔离机制,把线程分为若干组,不同的线程组分别服务于不同的类和方法,避免因为一个小功能点的故障,导致JVM内部所有线程受到影响。
此外,完善的运维监控(磁盘IO,网络IO)和APM(全链路性能监控)也非常重要,能及时预警,防患于未然,在故障发生时也能帮助我们快速定位问题。
就分享到这。原创不易,如果感觉本文对您有帮助,有劳点一下“在看”!
作者简介:曾任职于阿里巴巴,每日优鲜等互联网公司,任技术总监,15年电商互联网经历。
更多干货请关注:架构师进阶之路
