TIDB Salparse源码解析
网上搜寻了很多关于TIDB Salparse资料,但是关于源码解析的几乎没有找到,所以想自己写点资料记录一下。
实例解析
随着版本的迭代,官网给出的【例子】已经不能用了,下面是对官网的例子做出的修改
package main
import (
"fmt"
"github.com/pingcap/parser"
"github.com/pingcap/parser/ast"
_ "github.com/pingcap/tidb/types/parser_driver"
)
type visitor struct{}
func (v *visitor) Enter(in ast.Node) (out ast.Node, skipChildren bool) {
fmt.Printf("%T\n", in)
return in, false
}
func (v *visitor) Leave(in ast.Node) (out ast.Node, ok bool) {
return in, true
}
func main() {
sql := "SELECT /*+ TIDB_SMJ(employees) */ emp_no, first_name, last_name " +
"FROM employees USE INDEX (last_name) " +
"where last_name='Aamodt' and gender='F' and birth_date > '1960-01-01'"
p := parser.New()
stmt, warns, err := p.Parse(sql, "", "")
if err != nil {
fmt.Println(warns, "\n")
fmt.Printf("parse error:\n%v\n%s", err, sql)
return
}
fmt.Println("the length of stmt is", len(stmt))
for _, stmNode := range stmt {
v := visitor{}
stmNode.Accept(&v)
}
}
下面来分析这段代码
-
在mian函数里首先定义了一个sql变量,注意这个sql里面写了一段注释,后面我们会发现TIDB的sqlparser会识别sql里面的注释。
-
调用parser的new方法,new方法里面很简单,先去判断一下有没有导入驱动,如果没有驱动会引发panic。正常会返回一个Parser的指针结构体。
-
调用上面的生成的Parser的指针结构体对象的Parse方法,我们看一下Parse方法的源码
// Parse parses a query string to raw ast.StmtNode. // If charset or collation is "", default charset and collation will be used. func (parser *Parser) Parse(sql, charset, collation string) (stmt []ast.StmtNode, warns []error, err error) { if charset == "" { charset = mysql.DefaultCharset // utf8mb4 } if collation == "" { collation = mysql.DefaultCollationName // utf8mb4_bin } parser.charset = charset parser.collation = collation parser.src = sql parser.result = parser.result[:0] var l yyLexer parser.lexer.reset(sql) l = &parser.lexer yyParse(l, parser) warns, errs := l.Errors() if len(warns) > 0 { warns = append([]error(nil), warns...) } else { warns = nil } if len(errs) != 0 { return nil, warns, errors.Trace(errs[0]) } for _, stmt := range parser.result { ast.SetFlag(stmt) } return parser.result, warns, nil }方法内部我们以空白行为分割分为5段,
1-2段先是指定字符集和排序规则,默认分别是utf8mb4、utf8mb4_bin,然后对Parser指针结构体的属性进行一些初始化
第3段是【goyacc】根据所提供的yacc文件【parser.y】生成的代码【parser.go】所提供的接口来对输入的字符串进行解析,最后生成解析树。我们只用知道它是怎么一回事,最终是干了啥就可以了。
第4段就是判断一个解析有没有错误
第5段为解析的结果依次设置一些标签,最后返回解析结果,这里我们先不去看如何设置标签的,因为越往里面看越深,会带起更多的未知。先埋一个坑。
-
判断有没有解析失败,一般非法的sql语句会引发解析失败。然后获取解析结果切片的长度,运行显示的结果是1,因为我们传入的sql是一条完整的语句。可以传入多条sql语句,中间以分号隔开,这样返回的解析结果的切片的长度等于sql语句的个数,有兴趣的可以去尝试一下,这里就不做演示了。
-
对返回的结果进行一个for range 遍历,在for循环内部,初始化一个visitor结构体对象,然后从for循环中取出的对象的Accept方法,将visitor结构体对象的地址传入。至于Accept方法里面具体干了什么,先看一下for range取到的值是什么,从Parse方法的返回值可以看到,正常运行的话会返回值类型为ast.StmtNode的切片。我们使用开发工具查看StmtNode的源码
// StmtNode represents statement node. // Name of implementations should have 'Stmt' suffix. type StmtNode interface { Node statement() }发现StmtNode是一个
interface,所以我们不知道具体实现了该接口类型的Accept方法具体干了什么。先埋一个坑,后面具体分体。
节点
从上面的结论中我们知道了经过Parse返回的结果为一个StmtNode的结构体,而StmtNode嵌套了一个Node结构体,查看Node的源码
// Node is the basic element of the AST.
// Interfaces embed Node should have 'Node' name suffix.
type Node interface {
// Restore returns the sql text from ast tree
Restore(ctx *format.RestoreCtx) error
// Accept accepts Visitor to visit itself.
// The returned node should replace original node.
// ok returns false to stop visiting.
//
// Implementation of this method should first call visitor.Enter,
// assign the returned node to its method receiver, if skipChildren returns true,
// children should be skipped. Otherwise, call its children in particular order that
// later elements depends on former elements. Finally, return visitor.Leave.
Accept(v Visitor) (node Node, ok bool)
// Text returns the original text of the element.
Text() string
// SetText sets original text to the Node.
SetText(text string)
}
可以看到首行注释:Node是语法抽象树的最基本的元素。AST是abstract syntax tree的缩写
在Node里面有一个Accept方法,在上面的介绍里我们看到了StmtNode调用了Accept方法,而StmtNode嵌套了Node接口,所以只要是StmtNode接口类型就可以直接调用Accept方法。
实际上在当前模块【ast】下,由Node接口衍生出许多接口,我大致整理了一下, 他们之间的嵌套关系为:
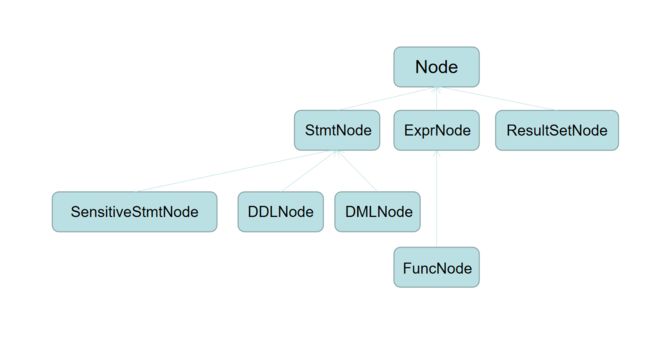
回到原来的实例程序,在实例的最后的for循环修改为
for _, stmNode := range stmt {
v := visitor{}
fmt.Printf("%T\n", stmNode)
stmNode.Accept(&v)
}
运行结果在控制台打印出*ast.SelectStmt, 【*ast.SelectStmt】
ast.SelectStmt结构体
// SelectStmt represents the select query node.
// See https://dev.mysql.com/doc/refman/5.7/en/select.html
type SelectStmt struct {
dmlNode
resultSetNode
// SelectStmtOpts wraps around select hints and switches.
*SelectStmtOpts
// Distinct represents whether the select has distinct option.
Distinct bool
// From is the from clause of the query.
From *TableRefsClause
// Where is the where clause in select statement.
Where ExprNode
// Fields is the select expression list.
Fields *FieldList
// GroupBy is the group by expression list.
GroupBy *GroupByClause
// Having is the having condition.
Having *HavingClause
// WindowSpecs is the window specification list.
WindowSpecs []WindowSpec
// OrderBy is the ordering expression list.
OrderBy *OrderByClause
// Limit is the limit clause.
Limit *Limit
// LockTp is the lock type
LockTp SelectLockType
// TableHints represents the table level Optimizer Hint for join type
TableHints []*TableOptimizerHint
// IsAfterUnionDistinct indicates whether it's a stmt after "union distinct".
IsAfterUnionDistinct bool
// IsInBraces indicates whether it's a stmt in brace.
IsInBraces bool
// QueryBlockOffset indicates the order of this SelectStmt if counted from left to right in the sql text.
QueryBlockOffset int
// SelectIntoOpt is the select-into option.
SelectIntoOpt *SelectIntoOption
}
这个结构体看上去很复杂,但我们看到了一些熟悉的字眼(mysql的关键字)
dmlNode: 内部使用的一个实现了DMLNode接口的结构体resultSetNode:*SelectStmtOpts:Distinct: 当sql语句中有distinct去重项时为trueFrom: 存储查询对象的相关参数信息Where:ExprNode接口的实现,存储一些查询时的条件的相关信息参数Fields:储存查询的字段的相关的信息参数GroupBy:储存group by查询时的相关信息Having: 储存having查询时的相关信息WindowSpecs:OrderBy:储存group by查询时的相关信息Limit: 储存limit查询时的相关信息LockTp:SelectLockType实现了fmt.Stringer的接口,当调用fmt.Println打印它的时候会返回对应的SelectLockType的类型的字符串, 因为是查类型,目前有for update、in share mode、for update nowait、unsupported select lock type、noneTableHints: 表示联接类型的表级优化器提示IsAfterUnionDistinct:IsInBraces:QueryBlockOffset:SelectIntoOpt:
Accept方法
// Accept implements Node Accept interface.
func (n *SelectStmt) Accept(v Visitor) (Node, bool) {
// 调用Vistor的Enter方法,返回一个节点类型和一个bool值
// 具体的业务可以在Enter方法里面实现
newNode, skipChildren := v.Enter(n)
// 如果业务选择跳过,那么会直接将调用当前Vistor的Leave方法
if skipChildren {
return v.Leave(newNode)
}
// 进行非安全类型断言,因为当前节点类型一定是`SelectStmt`,所以这种断言它不会出错,同时进行类型转换(主要目的)
n = newNode.(*SelectStmt)
// 下面这些if判断看上去很长,但其实都是在做一件事情
// 判断当前的子节点是否存在,如果不为空,那么存在该子节点就是一个Node接口的实现,调用该属性的Accept方法,然后将返回的节点的interface进行断言,同时将抽象的interface转换为具体的struct
// 最后调用Leave方法返回
if n.TableHints != nil && len(n.TableHints) != 0 {
newHints := make([]*TableOptimizerHint, len(n.TableHints))
for i, hint := range n.TableHints {
node, ok := hint.Accept(v)
if !ok {
return n, false
}
newHints[i] = node.(*TableOptimizerHint)
}
n.TableHints = newHints
}
if n.Fields != nil {
node, ok := n.Fields.Accept(v)
if !ok {
return n, false
}
n.Fields = node.(*FieldList)
}
if n.From != nil {
node, ok := n.From.Accept(v)
if !ok {
return n, false
}
n.From = node.(*TableRefsClause)
}
if n.Where != nil {
node, ok := n.Where.Accept(v)
if !ok {
return n, false
}
n.Where = node.(ExprNode)
}
if n.GroupBy != nil {
node, ok := n.GroupBy.Accept(v)
if !ok {
return n, false
}
n.GroupBy = node.(*GroupByClause)
}
if n.Having != nil {
node, ok := n.Having.Accept(v)
if !ok {
return n, false
}
n.Having = node.(*HavingClause)
}
for i, spec := range n.WindowSpecs {
node, ok := spec.Accept(v)
if !ok {
return n, false
}
n.WindowSpecs[i] = *node.(*WindowSpec)
}
if n.OrderBy != nil {
node, ok := n.OrderBy.Accept(v)
if !ok {
return n, false
}
n.OrderBy = node.(*OrderByClause)
}
if n.Limit != nil {
node, ok := n.Limit.Accept(v)
if !ok {
return n, false
}
n.Limit = node.(*Limit)
}
return v.Leave(n)
}
** 看注释 **
其实基本上所有的Node及其衍生的接口类型的Accept方法都是做这一件事情,保证所有的节点都可以来将Visitor接受,让Visitor对象可以遍历所有的节点,这样就可以在Visitor里面实现对Ast的完整处理
开始的那个例子,只有一个sql语句,根据之前的结论,它只会返回长度为1的切片,所以在for循环中Enter方法只会调用一次,Enter方法中的fmt.Printf也只会调用一次,但却打印出一串内容,就是这个道理。
【ats.SetFlag】
上面遗留了一坑,SetFlag具体做了什么?
func SetFlag(n Node) {
var setter flagSetter
n.Accept(&setter)
}
在SetFlag函数里面调用了Node的Accept方法。Accept上面分析过了,在里面会去调用传进来的Visitor接口类型的Enter和Leave方法
【ast.flagSetter】
type flagSetter struct {
}
func (f *flagSetter) Enter(in Node) (Node, bool) {
return in, false
}
func (f *flagSetter) Leave(in Node) (Node, bool) {
if x, ok := in.(ParamMarkerExpr); ok {
x.SetFlag(FlagHasParamMarker)
}
switch x := in.(type) {
case *AggregateFuncExpr:
f.aggregateFunc(x)
case *WindowFuncExpr:
f.windowFunc(x)
case *BetweenExpr:
x.SetFlag(x.Expr.GetFlag() | x.Left.GetFlag() | x.Right.GetFlag())
case *BinaryOperationExpr:
x.SetFlag(x.L.GetFlag() | x.R.GetFlag())
case *CaseExpr:
f.caseExpr(x)
case *ColumnNameExpr:
x.SetFlag(FlagHasReference)
case *CompareSubqueryExpr:
x.SetFlag(x.L.GetFlag() | x.R.GetFlag())
case *DefaultExpr:
x.SetFlag(FlagHasDefault)
case *ExistsSubqueryExpr:
x.SetFlag(x.Sel.GetFlag())
case *FuncCallExpr:
f.funcCall(x)
case *FuncCastExpr:
x.SetFlag(FlagHasFunc | x.Expr.GetFlag())
case *IsNullExpr:
x.SetFlag(x.Expr.GetFlag())
case *IsTruthExpr:
x.SetFlag(x.Expr.GetFlag())
case *ParenthesesExpr:
x.SetFlag(x.Expr.GetFlag())
case *PatternInExpr:
f.patternIn(x)
case *PatternLikeExpr:
f.patternLike(x)
case *PatternRegexpExpr:
f.patternRegexp(x)
case *PositionExpr:
x.SetFlag(FlagHasReference)
case *RowExpr:
f.row(x)
case *SubqueryExpr:
x.SetFlag(FlagHasSubquery)
case *UnaryOperationExpr:
x.SetFlag(x.V.GetFlag())
case *ValuesExpr:
x.SetFlag(FlagHasReference)
case *VariableExpr:
if x.Value == nil {
x.SetFlag(FlagHasVariable)
} else {
x.SetFlag(FlagHasVariable | x.Value.GetFlag())
}
}
return in, true
}
Enter方法什么都没做,关键是Leave,Leave里面使用了一个很长的switch case根据传进来的节点的不同类型来做出不同的处理。
示例解析就了解到这儿,虽然还是有很多未解决的问题,但大致了解了下TIDB sqlparse为我们提供的api的基本使用