OpenCV Python在计算机视觉中的应用

OpenCV Python教程
在这篇文章中,我们将使用Python中的OpenCv来涵盖计算机视觉的各个方面。OpenCV长期以来一直是软件开发的重要组成部分。
什么是计算机视觉?
我们考虑一个场景。
假设你和朋友们出去度假,你将一堆图片上传到了Facebook。但是,现在要花时间找到你朋友的脸,并在每张照片中标记出来。实际上,Facebook足够聪明,能够为你标记人物。
那么,你认为自动标记功能是如何工作的呢?简单来说,它就是通过计算机视觉工作的。
这里我们的想法是自动化人类视觉系统,让它可以独立的完成任务。因此,计算机应该能够识别诸如人脸或灯柱甚至是雕像之类的物体。
计算机如何读取图像?
观察下面的图像,我们可以比较容易的知道它是纽约天际线的形象。但是,计算机自己能发现嘛?答案是,不能!

计算机将任何图像读取为0-255范围之间的值。对于任何彩色图像,有3个主要的通道:红色(R)、绿色(G)和蓝色(B)。它的工作原理非常简单。为每种原色形成矩阵,然后,这些矩阵组合以便提供各个R、G和B颜色的像素值。矩阵的每个元素提供与像素的亮度、强度有关的数据。
观察下图:
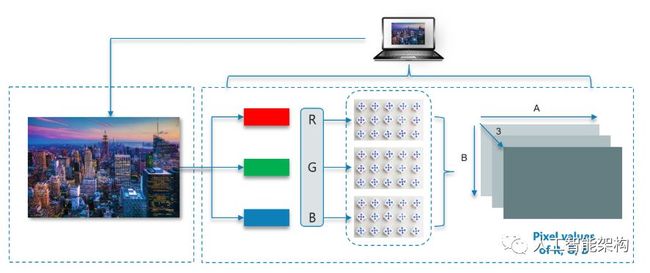
如图所示,这里的图像尺寸可以计算为B*A*3。注意:对于黑白图像,只有一个通道。
接下来我们看看OpenCV究竟是什么?
什么是OpenCV?
OpenCV最初由Intel于1999年开发的,但后来得到了Willow Garage的支持。它支持各种编程语言,如C++、Python、Java等。支持多种平台,包括Windows、Linux和MacOS。
OpenCV Python只不过是与Python一起使用的原始C++库的包装类。使用它,所有OpenCV数据结构都转换为NumPy数组或从NumPy数组转换。这样可以轻松的将其与使用NumPy的其他库集成。例如,SciPy和Matplotlib等库。
OpenCV的基本操作
先来了解各种概念,从加载图像到调整大小等。
使用OpenCV加载图像
1Import cv22# colored Image3Img = cv2.imread ("Penguins.jpg",1)4# Black and White (gray scale)5Img_1 = cv2.imread ("Penguins.jpg",0)
2# colored Image
3Img = cv2.imread ("Penguins.jpg",1)
4# Black and White (gray scale)
5Img_1 = cv2.imread ("Penguins.jpg",0)
如上面的代码所示,第一个要求是导入OpenCV模块。我们可以使用imread函数读取图像。参数中“1”表示它是彩色图像。如果参数为“0”,则表示导入的图像是黑白图像。这里图像的名称是“企鹅”。很容易,对吧?
图像形状/分辨率
可以利用形状功能打印出图像的形状,代码如下:
1Import cv22# Black and White (gray scale)3Img = cv2.imread ("Penguins.jpg",0)4Print(img.shape)
2# Black and White (gray scale)
3Img = cv2.imread ("Penguins.jpg",0)
4Print(img.shape)
根据图像的形状,也就是NumPy矩阵的形状,矩阵由768行和1024列组成。
显示图像:
使用OpenCV显示图像非常简单明了。
1import cv22# Black and White (gray scale)3Img = cv2.imread ("Penguins.jpg",0)4cv2.imshow("Penguins", img)5cv2.waitKey(0)6# cv2.waitKey(2000)7cv2.destroyAllWindows()import cv2
2# Black and White (gray scale)
3Img = cv2.imread ("Penguins.jpg",0)
4cv2.imshow("Penguins", img)
5cv2.waitKey(0)
6# cv2.waitKey(2000)
7cv2.destroyAllWindows()
如你所见,首先使用imread读入图像,但是,我们还需要一个窗口输出以显示图像。waitKey使窗口保持静态,直到用户按下某个键,传递的参数是以毫秒为单位的时间。最后,使用destroyAllWindows根据waitForKey参数关闭窗口。
调整图像大小
调整图像大小的操作也比较容易,代码如下:
1import cv22# Black and White (gray scale)3img = cv2.imread ("Penguins.jpg",0)4resized_image = cv2.resize(img, (650,500))5cv2.imshow("Penguins", resized_image)6cv2.waitKey(0)7cv2.destroyAllWindows()import cv2
2# Black and White (gray scale)
3img = cv2.imread ("Penguins.jpg",0)
4resized_image = cv2.resize(img, (650,500))
5cv2.imshow("Penguins", resized_image)
6cv2.waitKey(0)
7cv2.destroyAllWindows()
代码中调整大小的功能用于将图像大小调整为所需的形状,这里的参数是新调整大小的图像的形状。这就是我们期待输出的图像:

还有另一种方法可以将参数传递给resize函数,代码如下:
1Resized_image = cv2.resize(img, int(img.shape[1]/2), int(img.shape[0]/2)))1]/2), int(img.shape[0]/2)))
在这里,我们将新图像形状设置为原始图像的一半。
使用OpenCV进行人脸检测
对于初学者,可能认为这很难,我带你一起了解整个过程,你将会觉得它并没有那么难。Ready? GO!
第一步:需要一个图像,然后创建一个级联分类器,它能为我们提供面部特征;
第二步:使用OpenCV读取图像和功能文件,这里我们使用NumPy数组。需要搜索NumPy ndarray的行和列值,这是矩形坐标的数组;
第三步:使用矩形框显示图像;
以上就是图像检测的3个步骤。

首先,创建一个CascadeClassifier对象用来提取面部特征。如上所述,其中包含面部特征的XML文件的路径,它作为此处的参数。下一步是读取带有面部的图像,并使用COLOR_BGR2GREY将其转换为黑白图像。接着,使用detectMultiScale搜索图像的坐标。这是什么坐标呢?它是面部矩形的坐标。这里存在一个比例因子,它的值越小,准确度越高。最终,面部在窗口显示。
面部添加矩形框
我们直接看以下代码。

通过传递参数(如图像对象、框轮廓的RGB值和矩形的宽度)来定义使用cv2.rectangle创建矩形的方法。以下是完整的人脸检测代码:
1import cv2 2# Create a CascadeClassifier Object 3face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml") 4# Reading the image as it is 5img = cv2.imread("photo.jpg") 6# Reading the image as gray scale image 7gray_img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) 8# Search the co-ordintes of the image 9faces = face_cascade.detectMultiScale(gray_img, scaleFactor = 1.05,10 minNeighbors=5)11for x,y,w,h in faces:12 img = cv2.rectangle(img, (x,y), (x+w,y+h),(0,255,0),3)13resized = cv2.resize(img, (int(img.shape[1]/7),int(img.shape[0]/7)))14cv2.imshow("Gray", resized)15cv2.waitKey(0)16cv2.destroyAllWindows()import cv2
2# Create a CascadeClassifier Object
3face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
4# Reading the image as it is
5img = cv2.imread("photo.jpg")
6# Reading the image as gray scale image
7gray_img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
8# Search the co-ordintes of the image
9faces = face_cascade.detectMultiScale(gray_img, scaleFactor = 1.05,
10 minNeighbors=5)
11for x,y,w,h in faces:
12 img = cv2.rectangle(img, (x,y), (x+w,y+h),(0,255,0),3)
13resized = cv2.resize(img, (int(img.shape[1]/7),int(img.shape[0]/7)))
14cv2.imshow("Gray", resized)
15cv2.waitKey(0)
16cv2.destroyAllWindows()
使用OpenCV捕获视频
使用OpenCV捕获视频也是较为简单的工作,以下循环将使你更好的理解:

图像被逐个读取,因此由于帧的快速处理而产生视频,这使得各个图像移动,如下图:

首先,导入OpenCV库,接着使用VideoCapture方法,用于创建VideoCapture对象。该方法用于触发用户计算机上的摄像头,它的参数表示程序是否应使用内置摄像头或附加摄像头。“0”表示内置摄像头。最后,使用release方法在几毫秒内释放相机资源。
当你继续输入并执行上述代码时,会发现相机指示灯在一瞬间开启,稍后就关闭了,为什么会这样呢?是因为没有时间延迟来保持相机功能。

上述代码中第三行显示time.sleep(3),它的作用是使脚本停止3秒。所以,当执行代码时,网络摄像头将打开3秒。
添加窗口
添加一个窗口来显示视频输出非常的容易。它可以用于图像的相同方法进行比较。但是,代码有一些变化:

代码中,我们定义了一个NumPy数组,用于表示视频捕获的第一个图像,将它存储在帧矩阵里。还定义了一个bool数据类型,如果Python能够访问和读取VideoCapture对象,则返回True。以下是输出结果:
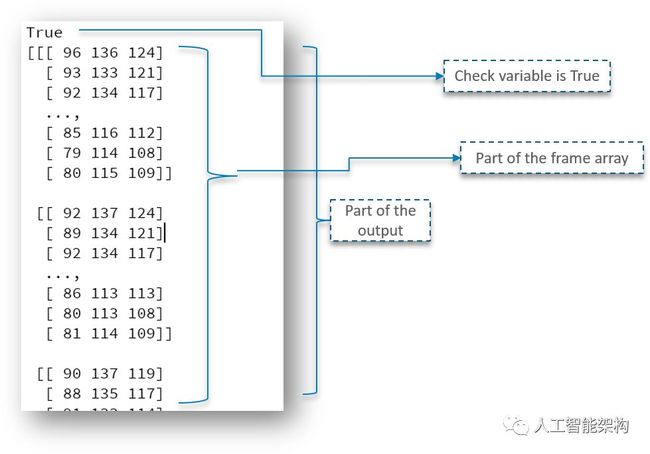
如你所见,我们将输出设为True,并打印了帧矩阵的一部分。但是我们需要读取视频的第一帧才能够开始。因此,我们需要首先创建一个框架对象来读取VideoCapture对象的图像。如上所示,imshow方法用于捕获视频的第一帧。
直接捕获视频
为了捕获视频,我们使用while循环。while的条件是:除非“check”为True,否则Python将显示帧。以下是代码片段:

我们使用cvtColor函数将每一帧转换为灰度图像,如前所述。waitKey(1)将确保在每毫秒间隙后生成新的一帧。while循环能够帮助迭代帧并最终显示视频。这里还有一个用户事件触发器,一旦用户按下“q”键,程序窗口就会关闭。
使用OpenCV的运动检测器
问题陈述
假设你正在接触一家研究人类行为的公司。你的任务是为他们提供可以检测前方运动的网络摄像头,然后,返回一个图形,这个图形应该包括人/物体在相机前面的时间。

所以,既然我们已经定义了问题,那么就需要构建一个解决方案,以结构化的方式解决问题。如下图:

最初,我们将图像保存在特定的帧里。下一步涉及将图像转换为高斯模糊图像,这样做是为了确保计算模糊图像和实际图像之间差异。
此时,图像仍然不是对象。我们定义一个阈值来去除瑕疵,例如图像中的阴影和其他噪声。对象的边框在后面定义,最后,我们计算对象出现的时间并退出框架。以下是代码片段:

遵循同样的原则,首先导入库并创建VideoCapture对象,以确保我们使用网络摄像头捕获视频。while循环遍历视频的各个帧。我们将彩色帧转换为灰度图像,在将灰度图转换为高斯模糊。详细代码,如下:

利用absdiff函数计算第一个出现的帧和所有其他帧之间的差异。threshold函数提供了一个阈值,使得它将差值转换为低于30的黑色。如果差异大于30,则会将这些像素转换为白色,THRESH_BINARY就是这个作用。之后我们用findContours函数来定义图像的轮廓区域,同时加入边界。该contourArea功能,如前所述,消除噪声和阴影。为了简单起见,它将只保留白色面积大于1000像素,正如我们定义的那样。接着,我们在工作框架中的对象周围创建一个矩形框。以下为代码片段:

如上所述,帧每毫秒更改一次,当用户输入“q”时,循环中断,窗口关闭。这个用例中还需要计算物体在相机前面的时间。
计算时间

使用DataFrame来存储对象检测和移动在帧中出现的时间值。我们来解释一下VideoCapture的功能,在这里我们有一个标志位(状态),记录开始时该状态为0,因为对象最初不可见。

当检测到对象时,我们将状态标志更改为1,如上图所示。

列出每个扫描帧的状态,然后在列表中记录日期和时间,以观察是否发生更改。

我们将时间值存储在DataFrame中,如上图所示。我们将通过将DataFrame写入CSV文件来结束,如图所示。
绘制运动检测图
用例的最后一步是显示结果。我们正在显示图形,表示在轴上的运动,参照以下代码:
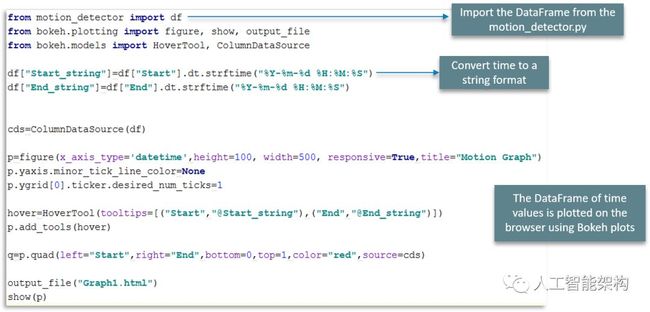
首先,导入数据帧从motion_detectory文件。接着,将时间转换为可持续的字符串格式,可以对其进行解析。最后,使用Bokeh图在浏览器上绘制时间值的DataFrame。
输出:

结论
希望这个OpenCV Python教程可以帮助你学习使用Python和OpenCV的基础知识。当你尝试开发需要图像识别和类似原理的应用程序时,使用它将非常方便。

长按二维码 ▲
订阅「架构师小秘圈」公众号
如有启发,帮我点个在看,谢谢↓