协作迭代实现单图像反光去除
本文章是在 AI研习社 听华中科技大学 李超的报告的一些笔记
论文:Single Image Reflection Removal through Cascaded Refinement,CVPR 2020
代码:正在开源
1. 研究动机
图像去反光就是下面的模型,I 是 T 和 R 的一个线性组合,但实际情况肯定比这个复杂。
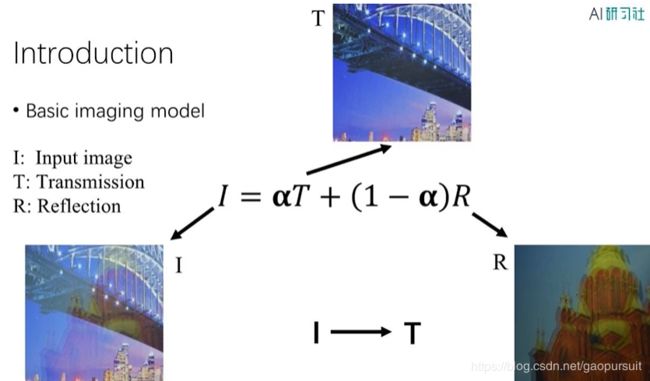
用深度学习解决图像去反光,主要存在下面两个问题:
- **问题一:**真实的训练数据难以获取:真实的有玻璃反光的图像 I 和无玻璃反光的图像 T 难获取。
- **问题二:**不同的成像条件:玻璃的厚度、天气条件、摄像头的光圈等,都可能会有影响。
对于问题一,按照下图方式,我们可以合成一些数据。比如对于那个塔的图像,做对称变换,然后模糊处理,做线性变换,可以得到 I

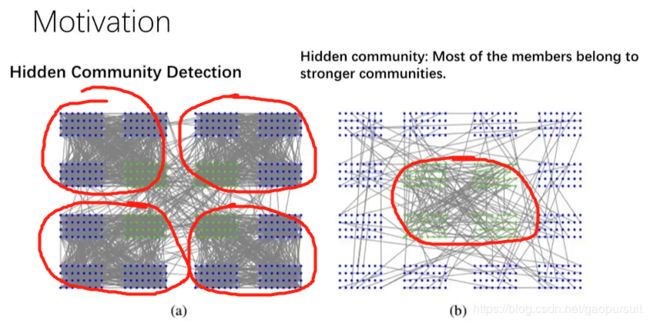
论文的动机来自于 hidden community detection,是其研究团队之前的一个工作。如下图左侧所示,四个社团之间联系很多,其中可能有些人有共同的爱好(踢足球),就隐性的构成一个社团。当你把主要社团内部的联系减弱,隐藏的社团就凸显出来了。如下图右侧所示,减弱主要社团成员间的联系,可以发现绿色部分也构成一个社团。
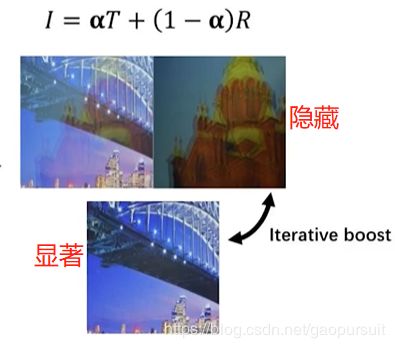
因此,再如下图所示,可以把真实图像 T 看作显著社团,反射图像 R 看作隐藏社团。先把 T 得到,然后削弱 T,得到 R。得到 R 以后呢,可以削弱 R ,得到 T,这样不停迭代,直到 T 和 R 都收敛。最后就可以得到比较好的结果。
2. 整体框架
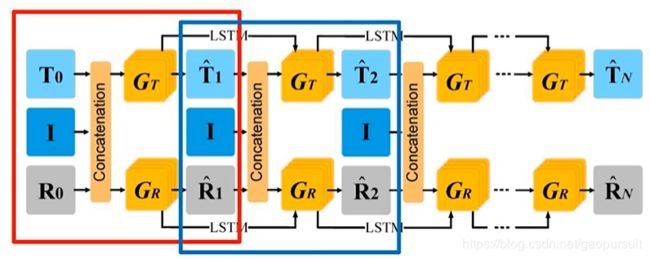
我们如何实现这个不停迭代的过程呢?论文的思路就是下面这个图,有两个 Conv-Deconv 的子网络(也可理解为生成器) G T G_T GT和 G R G_R GR,分别生成 T ^ \hat{T} T^ 和 R ^ \hat{R} R^ 。然后两者又合成,成生一个 I ^ \hat{I} I^,通过与输入的 I I I 进行对比(符号加了 hat 表示是生成的)。然后成生的 T ^ \hat{T} T^ 和 R ^ \hat{R} R^ 又再次输入网络,再次生成新的 T ^ \hat{T} T^ 和 R ^ \hat{R} R^,再次生成 I ^ \hat{I} I^,与真实的 I I I对比。不断重复这个过程,直到收敛。

作者也指出,论文里的框架图可能看起来不容易理解,下面这个图更加容易理解一些。这是上面图的展开图,各个迭代都展开了。随着输出越来越好,网络的输入也越来越好,这样就实现了 cascade refinement。
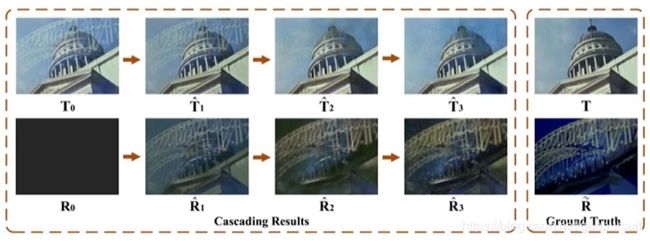
那么问题来了, T 0 T_0 T0 和 R 0 R_0 R0 实际操作的时候是如何初始化的呢?如下图所示, T 0 T_0 T0 其实就是 I I I。 R 0 R_0 R0 是一个全0的图,实际操作中作者发现,初始化为 0.1 效果更好些。输入到网络里面,不停迭代,可以发现结果越来越好。
3. 损失函数设计
3.1 设计的第一个损失函数:residual reconstruction loss
作者假定 T ^ \hat{T} T^, R ^ \hat{R} R^及生成的 I ^ \hat{I} I^之间有如下关系:
I ^ = α ⋅ T ^ + R ^ , \mathbf{\hat{I}}=\alpha \cdot \mathbf{\hat{T}} + \mathbf{\hat{R}}, I^=α⋅T^+R^,
因此, I ^ \hat{I} I^ 和原始的 I I I 应该非常相似,这样就有下面的损失函数:
L r e s i d u a l = ∑ I ∈ D ∑ t = 1 N L M S E ( I , I ^ t ) . \mathcal{L}_{residual}= \sum_{I\in \mathcal{D}}\sum\limits^{N}_{t = 1} \mathcal{L}_{MSE}(\mathbf{I}, \mathbf{\hat{I}}_t). Lresidual=I∈D∑t=1∑NLMSE(I,I^t).
3.2 设计的第二个损失函数:multi-scale perceptual loss
首先是 multi-scale loss,比如最后得到的是256x256的,那么我们取倒数第三层的输出是128x128,倒数第五层是 64x64 。这样我们就把真实图缩小,与它们比较。这个loss 是比较有效的,比较小的得到的是全局信息,比较大的得到的是细节信息。同时,作者没有直接把 feature map 进行比较,而是输入VGG网络进行处理。这种 perceptual loss 在多种低层视觉问题中表明效果更好。
具体来说,损失函数为:
L M P = ∑ T , T 3 , T 5 ∈ D ( L V G G ( T , T ^ ) + γ 3 L V G G ( T 3 , T ^ 3 ) + γ 5 L V G G ( T 5 , T ^ 5 ) ) \mathcal{L}_{MP} =\sum_{T, T^3, T^5\in \mathcal{D}} (\mathcal{L}_{VGG}(\mathbf{T}, \mathbf{\hat{T}}) +\gamma_3 \mathcal{L}_{VGG}(\mathbf{T^3},\mathbf{\hat{T}^3})+ \gamma_5 \mathcal{L}_{VGG}(\mathbf{T^5}, \mathbf{\hat{T}^5})) LMP=T,T3,T5∈D∑(LVGG(T,T^)+γ3LVGG(T3,T^3)+γ5LVGG(T5,T^5))
4. 实验设计
这部分作者提到了 controlled experiments,就是证明网络的各个部分都是有效的。作者首先把生成 R R R 的网络去掉了。如下图所示,可以看到,效果受到较大影响。去掉迭代,效果影也比较大。从而证明了网络的有效性。

对于提出的 loss 的有效性,作者也进行了探讨。如下图所示,各种 loss 情况下的效果实验比较。

5. 总结与展望
作者总结,这个方法可以用于两个信号分离,比如 underwater enhancement, raindrop removal, dehazing, flare removal 等,大家都可以进行尝试。
对于尚待解决的问题来说,主要有两个,第一个是训练数据问题,有两个CVPR 2019 的工作与训练数据有关,分别是:improving synthetic method 和 going beyond pairs。
第二个问题是,如何设置更加细节的评价标准,更好的为下游任务服务。根据目标检测等任务中的性能表现,来评估去反光的效果。