DataX Transformer 源码分析及 UDF 扩展与使用
- DataX GitHub
- DataX Transformer
目录
- 1 前言
- 2 需求说明
- 3 解决方案分析
- 4 解密算法
- 5 Hive UDF
- 5.1 测试数据
- 5.2 新建 Maven 项目
- 5.3 POM
- 5.4 UDF
- 5.5 测试代码
- 5.6 编译打包
- 5.7 使用
- 6 DataX
- 6.1 DataX Transformer
- 6.2 Transformer配置样例
- 6.3 一份测试数据
- 6.4 方法1:开发自定义的解密 Transformer功能
- 6.5 方法2: 通过使用dx_groovy
- 7 小节
1 前言
DataX 是一个使用方便且灵活的离线数据同步工具or平台,它提供了多种异构数据源之间高效的数据同步功能。关于 DataX 的详细介绍和Quickstart 可以查看我的另一篇 blog DataX离线数据同步,本文重点介绍 DataX 的 Transformer,它的功能等效于 ETL(Extract、Transformer、Load) 中的 T 过程,但是会结合一个场景提过多种实现方式,并一步一步对 DataX Transformer进行更深入的探索和使用。
2 需求说明
在数据传输的过程中,一般情况下只需要一个 Reader 和 Writer 将数据离线同步到目标位置即可,之后再在目标位置在进行下一步更复杂的处理。但有时直接将获取到的源端数据同步到目标位置后,对之后的处理会造成很大的麻烦。场景一,比如数据源为 Oracle 或者 MySQL 等关系型数据库,导出到大数据平台后常常会因为特殊字符导致字段切分出现问题而产生脏数据,源端的数据不能更改的情况下,只能在 reader 中parameter.connection.querySql 中根据数据库支持的函数方法进行处理,这样也能解决,但是 Oracle 和 MySQL 支持的函数方法可能会不同,测试维护多份 json 文件也不是很优雅的选择。场景二,源端数据库因为安全原因会对某些字段的值进行脱敏或加密处理,如果需要对此数据进行 OLAP ,又会使用内部的解密工具包解密(使用给定权限的账号获取数据并解密)后再进行处理,往往会严重影响效率。
下面会以解密处理指定字段(也可以对指定字段进行其它的处理)、整个流程为 MySQL -> DataX -> Hive -> sql 脚本定时调度执行 为例给出一种通用的高效的优雅的解决方法。
3 解决方案分析
基于整个流程以及性能的考虑,总体上主要有两种方案,三种实现方式。
方案一就是在 DataX 离线数据同步过程中对某些字段进行解密处理,这样的好处就是传输到大数据平台上的 HDFS 的数据就是解密之后的,后续脚本的执行或者重跑,只要涉及加密字段的都可以不用再执行任何的解密操作,同时对后续的整个业务的影响也是最小的,基本不用改动脚本和代码。这种方案又有两种方式实现,第一种自定义扩展自己的 DataX Transformer UDF,第二种就是使用原有的 dx_groovy Transformer UDF 方法。
方案二就是定义实现一个 Hive UDF ,加载到 Hive 中,注册一个永久的 UDF 函数方法,对处理中涉及到加密的字段调用自定义注册的函数进行解密。使用这种方案,意味着 DataX 不做任何处理,HDFS 上的数据还是加密的数据,当需要查询敏感字段的数据时我们就必须要调用 UDF 方法进行解密转换之后再进行之后的操作。这种方案的好处是速度可以得到充分的提升(在 YARN 资源充足的情况下),因为Hive 在解析完 SQL 之后会转为 MR 任务提交到 YARN 集群上执行,不过这种方案涉及到的业务上的改动也是最大的,不仅 SQL 脚本要进行修改,如果其它业务要查询这类数据时也需要进行改动,同时这种方法的 SQL 执行的速度受 YARN 集群的资源影响较大,如果资源充足时会比较快,如果资源不充足时可能需要等待,且可能会进行大量重复的解密操作。
下面会分别介绍这几种方案的具体实现。
4 解密算法
AES(Advanced Encryption Standard)高级加密标准,是一种常见的对称加密算法。可通过这篇文章了解 A Stick Figure Guide to the Advanced Encryption Standard (AES) 。
通过提供的工具类 jar 分析,我们可以提取出解密的核心逻辑(在第二部分分析中可以看到原解密和加密的逻辑主要为AesUtil 工具类),然后将核心逻辑整理为如下的工具类方法,代码如下(这部分可以单独放到一个工具类模块下):
package yore.utils;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.crypto.Cipher;
import javax.crypto.NoSuchPaddingException;
import javax.crypto.spec.SecretKeySpec;
import java.io.UnsupportedEncodingException;
import java.security.NoSuchAlgorithmException;
/**
* Created by yore on 2020/5/6 09:57
*/
public class AesUtil {
private static Logger LOG = LoggerFactory.getLogger(AesUtil.class);;
private static final String CHARSET_NAME = "UTF-8";
private static final String C_Key = "Mercury";
private static SecretKeySpec skeySpec;
private static Cipher cipher;
static {
init(C_Key);
}
/**
* 初始化加密工具类
*
* @param key 指定的密钥
*/
public static void init(String key){
if(StringUtils.isEmpty(key)){
key = C_Key;
}else if(key.length()<16){
key = String.format("%-16s", key);
}else if(key.length()>16){
key = key.substring(0, 16);
}
System.out.println("key = " + key);
try {
byte[] raw = key.getBytes("ASCII");
skeySpec = new SecretKeySpec(raw, "AES");
cipher = Cipher.getInstance("AES");
} catch (UnsupportedEncodingException e) {
LOG.error(e.getMessage());
} catch (NoSuchPaddingException e) {
LOG.error(e.getMessage());
} catch (NoSuchAlgorithmException e) {
LOG.error(e.getMessage());
}
}
/**
* 返回解密后的字符串(默认使用 cKey)
*
* @param content 待解密的字符串
* @return 解密后的字符串。null 值返回 null,空字符串返回空字符串
*/
public static String decrypt(String content) throws Exception {
if(null == content) return null;
if("".equals(content)) return "";
try {
cipher.init(2, skeySpec);
return new String(cipher.doFinal(toByte(new String(content.getBytes(), CHARSET_NAME))), CHARSET_NAME);
} catch (Exception e) {
LOG.error("AES解密失败,失败原因:" + e.getMessage());
return null;
}
}
/**
* 返回加密后的字符串(默认使用 cKey)
*
* @param content 待加密的字符串
* @return 加密后的字符串
*/
public static String encrypt(String content) throws Exception {
try {
cipher.init(1, skeySpec);
return toHexStr(cipher.doFinal(content.getBytes("utf-8")));
}catch (Exception e){
LOG.error("AES加密失败,失败原因:" + e.getMessage());
e.printStackTrace();
return null;
}
}
public static byte[] toByte(String hexStr) {
if (hexStr.length() < 1) {
return null;
} else {
byte[] result = new byte[hexStr.length() / 2];
for(int i = 0; i < hexStr.length() / 2; ++i) {
int high = Integer.parseInt(hexStr.substring(i * 2, i * 2 + 1), 16);
int low = Integer.parseInt(hexStr.substring(i * 2 + 1, i * 2 + 2), 16);
result[i] = (byte)(high * 16 + low);
}
return result;
}
}
public static String toHexStr(byte[] buf) {
StringBuffer sb = new StringBuffer();
for(int i = 0; i < buf.length; ++i) {
String hex = Integer.toHexString(buf[i] & 255);
if (hex.length() == 1) {
hex = '0' + hex;
}
sb.append(hex.toUpperCase());
}
return sb.toString();
}
}
pom.xml如下,通过 maven 打完 jar 包后为 yore-utils-1.0-SNAPSHOT.jar(注意工具包尽可能不要和 DataX 中的代码有冲突,否则 reader 或 writer 可能连接时无法正常建立连接等问题),然后将其上传到 datax/lib 下
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>yoregroupId>
<artifactId>common-utilsartifactId>
<version>1.0-SNAPSHOTversion>
<packaging>jarpackaging>
<name>yore utilsname>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-simpleartifactId>
<version>1.7.12version>
<scope>compilescope>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.3.2version>
dependency>
dependencies>
<build>
<finalName>yore-utils-${project.version}finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.7.0version>
<configuration>
<source>${maven.compiler.source}source>
<target>${maven.compiler.target}target>
<encoding>${project.build.sourceEncoding}encoding>
configuration>
plugin>
plugins>
build>
project>
5 Hive UDF
5.1 测试数据
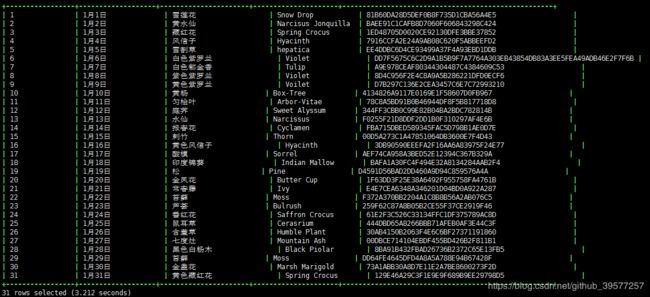
假如有如下测试数据,其中字段utterance 为加密的内容,下面通过 UDF 方式实现该字段的解密。
-- 建表
CREATE TABLE `flower_name` (
`id` int COMMENT '主键',
`date` varchar(110) COMMENT '日期',
`en_name` varchar(128) COMMENT '英文名',
`name` varchar(128) COMMENT '花名',
`utterance` varchar(255) COMMENT '含义'
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE;
-- 如下数据文件,以 | 分割的文本数据
1|1月1日|雪莲花|Snow Drop|81B60DA28D5DEF0B8F735D1CBA56A4E5
2|1月2日|黄水仙|Narcisus Jonquilla|BAEE91C1CAFB8D7060F606843298C424
3|1月3日|藏红花|Spring Crocus|1ED48705D0020CE92130DFE3BBE37852
4|1月4日|风信子|Hyacinth|7916CCFA2E24A9AB08C620F5ABBEEFD2
5|1月5日|雪割草|hepatica|EE4DDBC6D4CE93499A37F4A93EBD1DDB
6|1月6日|白色紫罗兰|Violet|DD7F5675C6C2D9A1B5B9F7A7764A303EB43854DB83A3EE5FEA49ADB46E2F7F6B
7|1月7日|白色郁金香|Tulip|A9E978CEAF80344304487C4384609C53
8|1月8日|紫色紫罗兰|Violet|8D4C956F2E4C8A9A5B286221DFD0ECF6
9|1月9日|黄色紫罗兰|Voilet|D7B297C136E2CEA3457C6E7C72993210
10|1月10日|黄杨|Box-Tree|4134826A9117E0169E1F58607D0FB967
11|1月11日|匀桧叶|Arbor-Vitae|78C8A5BD91B0B46944DF8F5B817718D8
12|1月12日|庭荠|Sweet Alyssum|344FF3CBB0C99E82B04BA2BDC782814B
13|1月13日|水仙|Narcissus|F0255F21D8DDF2DD1B0F310297AF4E6B
14|1月14日|报春花|Cyclamen|FBA715DBED589345FAC5D798B1AE0D7E
15|1月15日|剌竹|Thorn|00D5A273C1A47851064DB3600E7F4D43
16|1月16日|黄色风信子|Hyacinth|3DB90590EEEFA2F16AA6A83975F24E77
17|1月17日|酸模|Sorrel|AEF74CA958A3BED52E12394C367B329A
18|1月18日|印度锦葵|Indian Mallow|BAFA1A30FC4F494E32A8134284AAB2F4
19|1月19日|松|Pine|D4591D56BAD2DD460A9D94C859576A4A
20|1月20日|金凤花|Butter Cup|1F63DD3F25E38A6492F955758FA4761B
21|1月21日|常春藤|Ivy|E4E7CEA6348A346201D04BD0A922A287
22|1月22日|苔藓|Moss|F372A370BB2204A1C8B8B56A2AB076C5
23|1月23日|芦荟|Bulrush|259F62C87A8B05B2CE55F37CE2919F46
24|1月24日|番红花|Saffron Crocus|61E2F3C526C33134FFC1DF375789AC8D
25|1月25日|鼠耳草|Cerasrium|444DBD65A8266BBB71AFEB0AF3E44C3F
26|1月26日|含羞草|Humble Plant|30AB4150B2063F4E6C6BF27371191860
27|1月27日|七度灶|Mountain Ash|00DBCE714104EBDF455BD426B2F811B1
28|1月28日|黑色白杨木|Black Piolar|8BA91B432FBAD26736B2372C65E13FB5
29|1月29日|苔藓|Moss|DD64FE4645DFD4A8A5A788E94B67428F
30|1月30日|金盏花|Marsh Marigold|73A1ABB30A8D7E11E2A7BE8600273F2D
31|1月31日|黄色藏红花|Spring Crocus|129E46A29C3F1E9E9F689B9EE29798D5
-- 将数据导入 Hive。从本地到如到表
LOAD DATA LOCAL INPATH '/home/yore/data/flower_name.txt' OVERWRITE INTO TABLE flower_name;
5.2 新建 Maven 项目
例如使用 IntelliJ IDEA 创建一个 Maven 项目,GAV 信息类似于如下:
<artifactId>udf_decryptartifactId>
<groupId>yoregroupId>
<version>1.0-SNAPSHOTversion>
<packaging>jarpackaging>
5.3 POM
POM 为 Maven 的项目对象模型(Project Object Model),是 Maven 工程的基本工作单元,是一个XML文件,包含了项目的基本信息,用于描述项目如何构建,声明项目依赖,等等。因此我们先在前面创建的 Maven 项目下的 pom.xml 中引入 hive 相关的依赖,因为大数据环境中 Hive 和 Hadoop 相关的 jar 包都存在,因此可以将依赖方位改为 provided(打包的时候,在开发编译时改为默认的就行),
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<provided.scope>providedprovided.scope>
<hadoop.version>3.1.2hadoop.version>
<hive.version>3.1.1hive.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.2version>
<scope>${provided.scope}scope>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>3.1.1version>
<scope>${provided.scope}scope>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-cliartifactId>
<version>3.1.1version>
<scope>${provided.scope}scope>
dependency>
<dependency>
<groupId>yoregroupId>
<artifactId>common-utilsartifactId>
<version>1.0-SNAPSHOTversion>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
dependencies>
打包构建采用如下插件,
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.7.0version>
<configuration>
<source>${maven.compiler.source}source>
<target>${maven.compiler.target}target>
<encoding>${project.build.sourceEncoding}encoding>
configuration>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<version>2.6version>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
<configuration>
<finalName>udf_decryptfinalName>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
<plugin>
<artifactId>maven-surefire-pluginartifactId>
<version>2.20.1version>
<configuration>
<skip>trueskip>
configuration>
plugin>
<plugin>
<artifactId>maven-source-pluginartifactId>
<version>2.4version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>jar-no-forkgoal>
goals>
execution>
executions>
plugin>
plugins>
build>
5.4 UDF
@Description用来定义 UDF 的描述信息,这个信息可以通过执行 DESCRIBE FUNCTION EXTENDED 函数名;SQL 来查看。这里通过继承GenericUDF 实现自定义的UDF,而不是通过继承 UDF,因为通过继承 UDF类的方式在新版本已经废弃(但是可以正常使用)。重写 initialize方法用来对传入的数据类型进行初始化的验证操作,如果验证失败(即不是预期的数据类型),会直接抛出异常。重写 evaluate方法用来实现具体的解密逻辑。getDisplayString必须重写,但是逻辑可选,主要用来显示函数的帮助信息。
package yore;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.log4j.Logger;
import yore.utils.AesUtil;
/**
*
*
* hadoop fs -put zodiac.jar /app/udf-lib/
*
* CREATE FUNCTION default.udf_decrypt AS 'yore.DecryptUDF' USING jar 'hdfs:/app/udf-lib/zodiac.jar';
* CREATE TEMPORARY FUNCTION default.udf_decrypt2 AS 'yore.DecryptUDF' USING jar 'hdfs:/app/udf-lib/zodiac.jar';
*
* SELECT udf_decrypt("F9953708E0E479101887BF30ECF4606A");
* SELECT udf_decrypt("F9953708E0E479101887BF30ECF4606A") FROM movie LIMIT 20;
* DROP FUNCTION udf_decrypt;
*
*
* Created by yore on 2020/5/6 09:57
*/
@Description(name="udf_decrypt",
value="_FUNC_(value) - Returns the decrypted value of the encrypted string",
extended = "Example:\n"
+ " > SELECT _FUNC_('4A6DE4A853E3C69B5FA63D70C7B1F350') AS a1 FROM pdata_chq.t_test_jm limit 1; \n")
public class DecryptUDF extends GenericUDF {
private static Logger logger = Logger.getLogger(DecryptUDF.class);
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if(arguments.length != 1){
throw new UDFArgumentException("The operator 'udf_decrypt' accepts 1 arguments.");
}
ObjectInspector returnType = PrimitiveObjectInspectorFactory.getPrimitiveJavaObjectInspector(PrimitiveObjectInspector.PrimitiveCategory.STRING);
return returnType;
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
if(arguments[0].get()==null)return null;
try {
return AesUtil.decrypt(String.valueOf(arguments[0].get()));
}catch (Exception e){
logger.error(e.getMessage());
return null;
}
}
@Override
public String getDisplayString(String[] children) {
StringBuilder sb = new StringBuilder();
sb.append("返回 " + children[0] + " 的解密后的值")
.append("\n")
.append("Usage: udf_decrypt(cloumn_name)")
.append("\n")
.append("当解密过程中报异常,返回 null");
return sb.toString();
}
}
5.5 测试代码
可以在不进行部署的情况下,测试 UDF 的逻辑是否有误,测试代码采用 JUNIT测试框架实现(但这不保证集群环境一定没问题,因为测试过程中没有获取元数据的过程,但可以检测计算逻辑是否正确),如下
package yore;
import junit.framework.Assert;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF.DeferredJavaObject;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF.DeferredObject;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
import org.junit.Test;
/**
* Created by yore on 2020/4/30 10:12
*/
public class DecryptUDFTest {
@Test
public void decryptUDFTest() throws HiveException {
DecryptUDF udf = new DecryptUDF();
ObjectInspector valueOI1 = PrimitiveObjectInspectorFactory.writableVoidObjectInspector;
ObjectInspector[] arguments = { valueOI1};
udf.initialize(arguments);
DeferredObject[] args = new DeferredObject[1];
String columnVal = "F9953708E0E479101887BF30ECF4606A";
args[0] = new DeferredJavaObject(columnVal==null? null: new Text(columnVal));
Object result = udf.evaluate(args);
System.out.println(result);
Assert.assertEquals(result, "Yore");
columnVal = null;
args[0] = new DeferredJavaObject(columnVal==null? null: new Text(columnVal));
result = udf.evaluate(args);
Assert.assertEquals(result, null);
columnVal = "DD64FE4645DFD4A8A5A788E94B67428F";
args[0] = new DeferredJavaObject(columnVal==null? null: new Text(columnVal));
result = udf.evaluate(args);
System.out.println(result);
Assert.assertEquals(result, "呵护");
}
}
5.6 编译打包
直接在项目向执行 mvn clean package 命令打包,或者使用 IDEA 集成的 Maven 工具打包,打完包之后在 target 下有如下打好的jar 包。第一个是带依赖的jar,第二个是没有依赖的jar,第三个是源码包。UDF的 jar 包使用第一个带依赖的,上传到 HDFS 上。

5.7 使用
使用 Maven 打包命令,将上述编写好的代码打包,上传到HDFS 的指定路径下(例如/app/udf-lib/),然后执行如下 SQL。
-- 创建函数。
-- 这样会创建一个永久函数,如果是临时函数在 CREATE 后加上 TEMPORARY 关键字即可
CREATE FUNCTION udf_decrypt AS 'yore.DecryptUDF' USING jar 'hdfs:/app/udf-lib/udf_decrypt-jar-with-dependencies.jar';
-- 查看函数说明
DESCRIBE FUNCTION EXTENDED udf_decrypt ;
-- 解密数据
DESCRIBE FUNCTION EXTENDED udf_decrypt ;
-- 查询数据,解密 utterance 字段信息
SELECT id,`date`,en_name,name,udf_decrypt(utterance) FROM flower_name;
-- 删除自定义函数
DROP FUNCTION udf_decrypt;

6 DataX
6.1 DataX Transformer
在数据同步、传输过程中,存在用户对于数据传输进行特殊定制化的需求场景,包括裁剪列、转换列等工作,可以借助ETL的T过程实现(Transformer)。DataX包含了完成的E(Extract)、T(Transformer)、L(Load)支持。
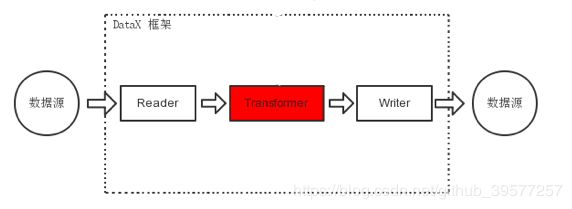
DataX Transformer的运行模型如下图所示,红色部分就是 Transformer 就是 DataX 在整个架构中所处的位置,类似于 ETL 过程中的T 过程,数据源由 DataX Reader 获取,Reader 获取的数据通过 Transformer 之后进入到 DataX Writer,最后输出到目标位置。
6.2 Transformer配置样例
下面我们看一下Transformer 的一个配置模板。一般情况下,只需要在 content 中配置 reader 和 writer 的配置项就可以将数据离线同步的目标位置,如果使用 Transformer 需要在 content 中添加一个 jsonArray,因为可能会用到多个 Transformer 方法对不同字段的值进行处理,jsonArray 中配置具体 Transformer 方法,配置的模板 json 如下。
{
"job": {
"setting": {……},
"content": [
{
"reader": {……},
"writer": {……},
"transformer": [
{
"name": "dx_substr",
"parameter": {
"columnIndex": 5,
"paras": [ "1", "3" ]
}
}
]
}
]
}
}
6.3 一份测试数据
以 MySQL 到 Hive 为例,需要在 MySQL 中准备一份测试数据,当然也可以使用 Hive UDF 章节的数据,只需要将 Reader 改为hdfsreader即可 ,这里还是主要以目前的流程为例,演示 MySQL 到 Hive 中间如何对指定字段进行解密处理。
-- 建表(MySQL)
CREATE TABLE `flower_name` (
`id` int(6) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`date` varchar(110) COLLATE utf8_bin DEFAULT NULL COMMENT '日期',
`en_name` varchar(128) COLLATE utf8_bin NOT NULL COMMENT '英文名',
`name` varchar(128) COLLATE utf8_bin NOT NULL COMMENT '花名',
`utterance` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '含义',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=367 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- 插入测试数据
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(1, '1月1日', '雪莲花', 'Snow Drop', '81B60DA28D5DEF0B8F735D1CBA56A4E5');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(2, '1月2日', '黄水仙', 'Narcisus Jonquilla', 'BAEE91C1CAFB8D7060F606843298C424');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(3, '1月3日', '藏红花', 'Spring Crocus', '1ED48705D0020CE92130DFE3BBE37852');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(4, '1月4日', '风信子', 'Hyacinth', '7916CCFA2E24A9AB08C620F5ABBEEFD2');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(5, '1月5日', '雪割草', 'hepatica', 'EE4DDBC6D4CE93499A37F4A93EBD1DDB');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(6, '1月6日', '白色紫罗兰', 'Violet', 'DD7F5675C6C2D9A1B5B9F7A7764A303EB43854DB83A3EE5FEA49ADB46E2F7F6B');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(7, '1月7日', '白色郁金香', 'Tulip', 'A9E978CEAF80344304487C4384609C53');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(8, '1月8日', '紫色紫罗兰', 'Violet', '8D4C956F2E4C8A9A5B286221DFD0ECF6');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(9, '1月9日', '黄色紫罗兰', 'Voilet', 'D7B297C136E2CEA3457C6E7C72993210');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(10, '1月10日', '黄杨', 'Box-Tree', '4134826A9117E0169E1F58607D0FB967');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(11, '1月11日', '匀桧叶', 'Arbor-Vitae', '78C8A5BD91B0B46944DF8F5B817718D8');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(12, '1月12日', '庭荠', 'Sweet Alyssum', '344FF3CBB0C99E82B04BA2BDC782814B');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(13, '1月13日', '水仙', 'Narcissus', 'F0255F21D8DDF2DD1B0F310297AF4E6B');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(14, '1月14日', '报春花', 'Cyclamen', 'FBA715DBED589345FAC5D798B1AE0D7E');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(15, '1月15日', '剌竹', 'Thorn', '00D5A273C1A47851064DB3600E7F4D43');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(16, '1月16日', '黄色风信子', 'Hyacinth', '3DB90590EEEFA2F16AA6A83975F24E77');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(17, '1月17日', '酸模', 'Sorrel', 'AEF74CA958A3BED52E12394C367B329A');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(18, '1月18日', '印度锦葵', 'Indian Mallow', 'BAFA1A30FC4F494E32A8134284AAB2F4');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(19, '1月19日', '松', 'Pine', 'D4591D56BAD2DD460A9D94C859576A4A');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(20, '1月20日', '金凤花', 'Butter Cup', '1F63DD3F25E38A6492F955758FA4761B');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(21, '1月21日', '常春藤', 'Ivy', 'E4E7CEA6348A346201D04BD0A922A287');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(22, '1月22日', '苔藓', 'Moss', 'F372A370BB2204A1C8B8B56A2AB076C5');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(23, '1月23日', '芦荟', 'Bulrush', '259F62C87A8B05B2CE55F37CE2919F46');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(24, '1月24日', '番红花', 'Saffron Crocus', '61E2F3C526C33134FFC1DF375789AC8D');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(25, '1月25日', '鼠耳草', 'Cerasrium', '444DBD65A8266BBB71AFEB0AF3E44C3F');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(26, '1月26日', '含羞草', 'Humble Plant', '30AB4150B2063F4E6C6BF27371191860');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(27, '1月27日', '七度灶', 'Mountain Ash', '00DBCE714104EBDF455BD426B2F811B1');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(28, '1月28日', '黑色白杨木', 'Black Piolar', '8BA91B432FBAD26736B2372C65E13FB5');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(29, '1月29日', '苔藓', 'Moss', 'DD64FE4645DFD4A8A5A788E94B67428F');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(30, '1月30日', '金盏花', 'Marsh Marigold', '73A1ABB30A8D7E11E2A7BE8600273F2D');
INSERT INTO flower_name(id, date, name, en_name, utterance) VALUES(31, '1月31日', '黄色藏红花', 'Spring Crocus', '129E46A29C3F1E9E9F689B9EE29798D5');
插入完毕后如下图,其中utterance为已加密的内容,需要查看时必须要对其进行解密操作,这部分的数据会通过 DataX离线同步到 Hive,我们就在离线通过的过程中将其解密放置到 HDFS 上,下面会通过 DataX Transformer 的两种方式实现这个功能。
6.4 方法1:开发自定义的解密 Transformer功能
在实现这部分功能是,需要我们对源码进行一定研究,下面先查看源码逻辑,主要涉及到Transformer的 DataX模块有datax-transformer 和 datax-core两个,如下图所示,左侧是datax-transformer模块,里面定义了两个抽象类。右侧是 datax-core 模块的代码,其中在com.alibaba.datax.core.transport.transformer包下是Transformer的主要实现。
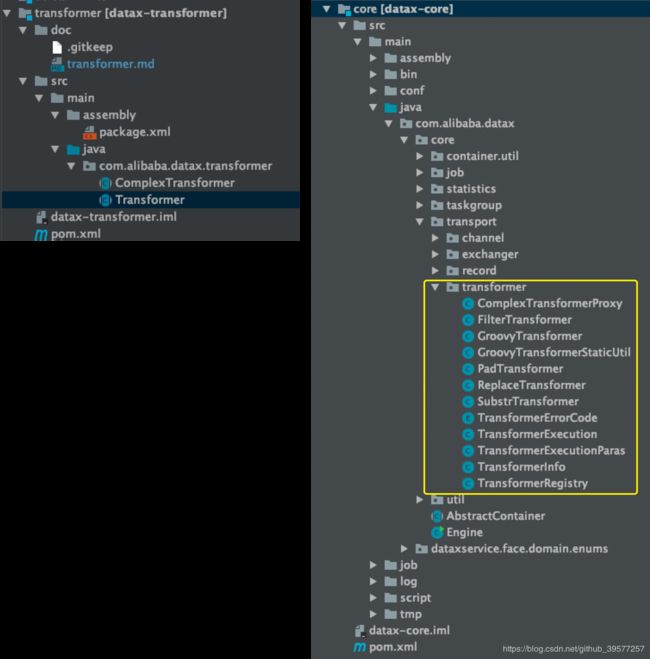
datax-transformer 模块有两个抽象类,Transformer 抽象类用于普通的 Transformer 实现,其中定义了 transformerName,用于设置 Transformer 方法的名称,abstract public Record evaluate(Record record, Object... paras)用于具体的处理逻辑的实现。ComplexTransformer 抽象类用于复杂的 Transformer 实现,大体上和 Transformer抽象类类似,唯一不同的是evaluate抽象方法多了一个Map 参数,用于传递transformer运行的配置项信息。
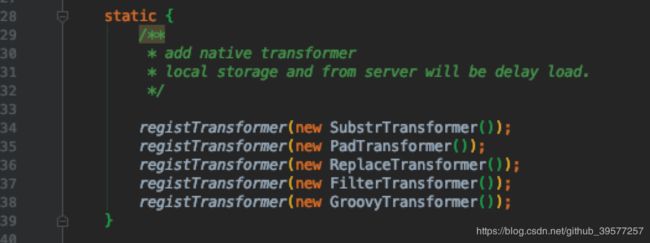
查看 Transformer 的注册类com.alibaba.datax.core.transport.transformer.TransformerRegistry,可以看到官方默认注册了 5 个方法,分别是截取字符串、填补、替换、过滤、groovy 代码段(后面会详细介绍)。因此我们也可以通过继承 Transformer 重写 evaluate,类似于实现自己的一个 UDF,其中实现具体的解密逻辑,最后在这里进行注册生效即可。
对框架进行修改一般需要拉取源码到本地,导入 IDEA(也可以是其它开发工具),修改或扩展源码,编译打包,部署到环境开始使用。但这里我们只针对datax-core 模块进行修改和扩展,本着最小化的方式,我们直接新建一个 Maven 项目,pom 中引入如下配置。GAV 信息可以根据情况自行填写。yore.utils:jiemi 为我们引入的一个内部的解密的工具类(这里可以不用,我会把解密的核心逻辑抽取出来,并进一步优化对象的创建方式)。
根据源码分析,datax-core 依赖于 datax-transformer模块,datax-transformer又依赖于 datax-common 模块,因此需要依次引入项目,因为这三个 DataX的 jar 依赖在外部仓库中并不存在,引入方法要么手动执行 maven 的 install 命令将 这三个 jar 包导入 本地仓库,这里则直接从环境中的 DataX 的安装解压的目录 lib/ 下下载获取 datax-common-0.0.1-SNAPSHOT.jar、datax-core-0.0.1-SNAPSHOT.jar、datax-transformer-0.0.1-SNAPSHOT.jar 三个 jar 包,在项目的根目录下创建一个 lib 文件夹,放入到此文件中,然后按照下面的方式引入项目中。因为可以不用打包,maven 的 Build 相关的其它插件此时可以不用引入。
<groupId>com.yoregroupId>
<artifactId>datax-decryptartifactId>
<version>1.0.0-SNAPSHOTversion>
<packaging>jarpackaging>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<java.version>1.8java.version>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<datax.version>0.0.1-SNAPSHOTdatax.version>
properties>
<dependencies>
<dependency>
<groupId>yoregroupId>
<artifactId>common-utilsartifactId>
<version>1.0-SNAPSHOTversion>
dependency>
<dependency>
<groupId>com.alibaba.dataxgroupId>
<artifactId>datax-commonartifactId>
<version>${datax.version}version>
<scope>systemscope>
<systemPath>${project.basedir}/lib/datax-common-0.0.1-SNAPSHOT.jarsystemPath>
dependency>
<dependency>
<groupId>com.alibaba.dataxgroupId>
<artifactId>datax-transformerartifactId>
<version>${datax.version}version>
<scope>systemscope>
<systemPath>${project.basedir}/lib/datax-transformer-0.0.1-SNAPSHOT.jarsystemPath>
dependency>
<dependency>
<groupId>com.alibaba.dataxgroupId>
<artifactId>datax-coreartifactId>
<version>${datax.version}version>
<scope>systemscope>
<systemPath>${project.basedir}/lib/datax-core-0.0.1-SNAPSHOT.jarsystemPath>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>1.7.12version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.3.2version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
dependencies>
在项目下的 src/main/java下创建 com.alibaba.datax.core.transport.transformer 包名(全限定包名一定是这个,不能修改为其它的)。然后在下面新建YoreDecryptTransformer 类,包括解密和加密抽取出的代码也附上如下(已进行尽可能的优化),直接上代码如下。
package com.alibaba.datax.core.transport.transformer;
import com.alibaba.datax.common.element.Column;
import com.alibaba.datax.common.element.Record;
import com.alibaba.datax.common.element.StringColumn;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.transformer.Transformer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import yore.utils.AesUtil;
import java.util.Arrays;
/**
* 自定义一个 DataX Transformer ,用于特殊情况下的解密
*
*
* 编译项目(clone 完整项目时务必这样编译)
* mvn clean compile -Dmaven.test.skip=true
*
*
* Created by yore on 2020/5/7 10:02
*/
public class YoreDecryptTransformer extends Transformer{
private static final Logger LOG = LoggerFactory.getLogger(YoreDecryptTransformer.class);
public YoreDecryptTransformer() {
setTransformerName("dx_yore_decrypt");
}
/**
* 实现对指定字段的解密处理
*
* @author Yore
* @param record 记录
* @param paras transformer 方法传入的参数
* @return Record 记录
*/
@Override
public Record evaluate(Record record, Object... paras) {
int columnIndex;
String aesKey = null;
try {
if(paras.length == 1){
columnIndex = (Integer) paras[0];
}else if(paras.length ==2){
columnIndex = (Integer) paras[0];
aesKey = (String) paras[1];
}else{
throw new RuntimeException(getTransformerName() + " paras at moust 2");
}
}catch (Exception e){
throw DataXException.asDataXException(TransformerErrorCode.TRANSFORMER_ILLEGAL_PARAMETER, "paras:" + Arrays.asList(paras).toString() + " => " + e.getMessage());
}
Column column = record.getColumn(columnIndex);
try {
String oriValue = column.asString();
//如果字段为空,跳过,不进行解密操作
if(oriValue == null){
return record;
}
String newValue;
if(aesKey == null){
newValue = AesUtil.decrypt(oriValue);
}else if(aesKey.trim().length()<1){
newValue = AesUtil.decrypt(oriValue);
LOG.warn("指定的解密密钥 key={} 无效,将采用默认密钥解密", aesKey);
}else {
AesUtil.init(aesKey);
newValue = AesUtil.decrypt(oriValue);
}
record.setColumn(columnIndex, new StringColumn(newValue));
}catch (Exception e){
throw DataXException.asDataXException(TransformerErrorCode.TRANSFORMER_RUN_EXCEPTION, e.getMessage(),e);
}
return record;
}
}
剩下最重要的一步就是把上面扩展的 Transformer 注册到 DataX 中。打开 com.alibaba.datax.core.transport.transformer; 类添加如下代码:
package com.alibaba.datax.core.transport.transformer;
// ……
/**
* no comments.
* Created by liqiang on 16/3/3.
*/
public class TransformerRegistry {
// ……
static {
/**
* add native transformer
* local storage and from server will be delay load.
*/
registTransformer(new SubstrTransformer());
registTransformer(new PadTransformer());
registTransformer(new ReplaceTransformer());
registTransformer(new FilterTransformer());
registTransformer(new GroovyTransformer());
// 自定义添加的 transformer
registTransformer(new YoreDecryptTransformer());
}
// ……
}
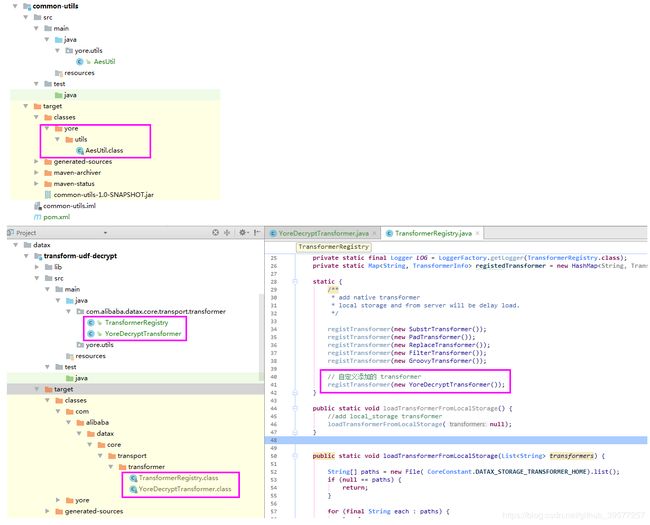
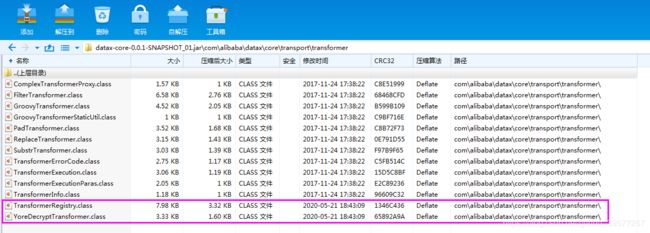
如果是 IntelliJ IDEA ,直接是由右侧 Maven 的生命周期的 compile ,编译我们上面完成的代码。编译成功后如下图左侧,最后将前面获取的 datax-core-0.0.1-SNAPSHOT.jar 包复制一份,用解压工具打开,将左侧红色框中的2个编译后的代码直接添加和复制替换 datax-core-0.0.1-SNAPSHOT.jar 包里的中的内容(注意工具类需要放到 DataX 的环境变量中,也可以直接放到jar或者 datax/lib 下,否则解密方法获取不到),保存更新 jar 包,这样二次开发后的 DataX 核心模块的就开发完毕,外发完毕后,就可以替换服务器环境的 datax-core-0.0.1-SNAPSHOT.jar 包了,复制替换之前可以将原有的这个包拷贝备份一份。
接下来就是使用我们扩展的解密的 Transformer UDF 方法,DataX 的一个 MySQL 到 HDFS 的 json 配置如下。这里对 Reader 和 Writer 不再啰嗦,重点看transformer 配置项,其值为一个 jsonArray,意味着可以配置多个 transformer 方法,确实可以在这里调用不同的transformer 方法对不同的字段进行处理,例如如果需要对表中的三个字段解密,里面配置两个dx_yore_decrypt 扩展 Transformer 时代码中定义的名称)即可,在columnIndex 指定上要处理的字段编号(注意,是从 0 开始),参数列表 paras为 null ,表示使用默认 密钥 key 解密,如果需要指定密钥,也可以在这里传入。
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"date",
"en_name",
"name",
"utterance"
],
"splitPk": "id",
"connection": [
{
"table": [
"flower_name"
],
"jdbcUrl": [
"jdbc:mysql://cdh1:3306/flink_test"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://cdh1:8020",
"column": [
{
"name": "id",
"type": "BIGINT"
},
{
"name": "date",
"type": "STRING"
},
{
"name": "en_name",
"type": "STRING"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "utterance",
"type": "STRING"
}
],
"fieldDelimiter": "|",
"fileName": "flower_name",
"fileType": "text",
"path": "/yore",
"writeMode": "append"
}
},
"transformer": [
{
"name": "dx_yore_decrypt",
"parameter": {
"columnIndex": 4,
"paras": []
}
}
]
}
]
}
}
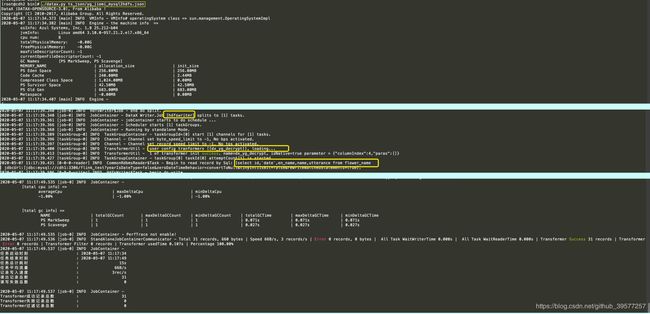
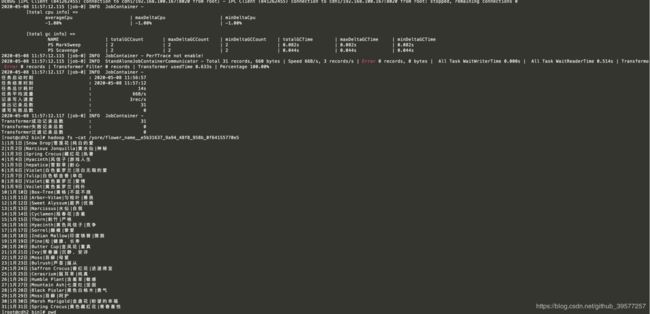
将上面的 json 保存到文件中,例如在datax/bin 执行 python datax.py ts_json/yore_jiemi_mysql2hdfs.json,然后执行命令开始 MySQL 数据到 HDFS 的离线同步。从执行的日志可以看到DataX 加载的Reader 为 mysqlreader、 Writer 为 hdfswriter,对Job切分数为 1,任务组数为 1,因为是往 HDFS 写入数据,所以会先从 NameNode 节点获取信息,在 DEBUG中可以看到更多关于 HDFS 写的过程信息。最后查看本次数离线同步的报告,可以看到 Transformer 成功记录总数为 31,表示表中的 31 条数据已全部成功导出到 HDFS。
我们再来查看导入到 HDFS 上的数据,
# 查看HDFS目标目录下的文件信息
hadoop fs -ls /yore
# 查看数据
hadoop fs -cat /yore/flower_name__b00a2792_1c23_4074_ac94_7d40f5409b16
结果如下图,可以看到最后一个字段的值由原先的加密状态已经全部改为解密的内容了,这样就可以直接使用数据,而不用重复执行解密操作(这里为了演示方便 writer 时的文件格式为 txt,在生产环境建议统一改为 ORC 格式,DataX 那里配置)。

6.5 方法2: 通过使用dx_groovy
通过上一节我们可以看到原项目 datax-core 模块中已经自动注册了GroovyTransformer,查看官方文档我们可以知道其用法。这里我们可以选择这种方式来实现,这种方式是直接使用这个 Transformer 方法,在方法中传入 groovy 代码片段和导入的扩展全限定包名。
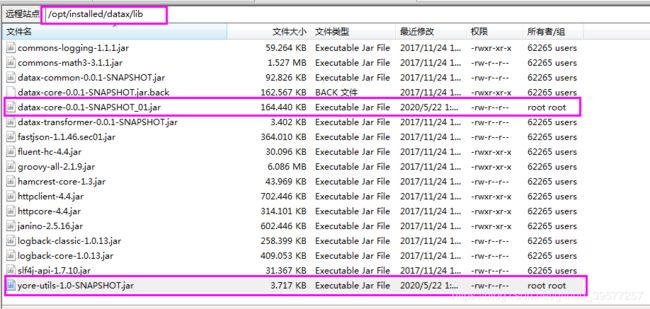
首先将解密的工具 jar 包放到 datax 的 lib 目录下(在上一节部分我们已经将解密的工具包yore-utils-1.0-SNAPSHOT.jar放到此目录下了,可以略过)。
编写解密的 Groovy 代码片段,如下(这里需要注意的是 dx_groovy只能调用一次。不能多次调用,因此 Groovy 代码片段中需要将所有解密字段的逻辑全部编写完毕)。下面 Groovy 代码,第一行获取第三列的,第二行为获取该列的原始数据值,第三行为调用解密工具类的解密方法,将加密的原始值解密为新值,第四行为将解密后的新值设置到该字段上(修改),第五行返回 record 数据对象。
// getColumn(4) 获取第 reader 处column 中指定的第 5 个字段对象。
Column column = record.getColumn(4);
// .asString() 将获取的第5个字段对象转成字符串的值。
// 同时还支持:asLong、asDouble、asDate、asBytes、asBoolean、asBigDecimal、asBigInteger
String oriValue = column.asString();
// 调用自己内部提供的解密 jar包中的工具类的解密方法
String newValue= AesUtil.decrypt(oriValue);
// 将第五个字段的值改为解密后的值,
// 同时还支持new 的对象有: LongColumn、DoubleColumn、DateColumn、BytesColumn、BoolColumn、
record.setColumn(4, new StringColumn(newValue));
// 返回设置好的记录对象
return record;
也可以将上面的代码合并为一行。如果解密多个字段,可以合并写为(例如同时解密第5 和第 7 个字段的值)
record.setColumn(4, new StringColumn(AesUtil.decrypt(record.getColumn(4).asString())));
record.setColumn(6, new StringColumn(AesUtil.decrypt(record.getColumn(6).asString())));
return record;
json 文件如下,Reader 和 Writer 的配置不变。只是将 Transformer 中改为使用 dx_groovy 方法的配置,在 parameter.code 中配置为上面的 groovy 代码段(\n 字符可以不用加,仅仅是为了输出时格式化为多行显示用)。extraPackage中配置添加的导入的 全限定包名,可以导入多个(例如 json 文件在 datax/bin/ts_json/groovy_jiemi_mysql2hdfs.json)。
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"date",
"en_name",
"name",
"utterance"
],
"splitPk": "id",
"connection": [
{
"table": [
"flower_name"
],
"jdbcUrl": [
"jdbc:mysql://cdh1:3306/flink_test"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://cdh1:8020",
"column": [
{
"name": "id",
"type": "BIGINT"
},
{
"name": "date",
"type": "STRING"
},
{
"name": "en_name",
"type": "STRING"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "utterance",
"type": "STRING"
}
],
"fieldDelimiter": "|",
"fileName": "flower_name",
"fileType": "text",
"path": "/yore",
"writeMode": "append"
}
},
"transformer": [
{
"name": "dx_groovy",
"parameter": {
"code": "record.setColumn(4, new StringColumn(AesUtil.decrypt(record.getColumn(4).asString())));\nreturn record;",
"extraPackage": [
"import yore.utils.AesUtil;"
]
}
}
]
}
]
}
}
执行 python datax.py ts_json/groovy_jiemi_mysql2hdfs.json的结果如下,查看 HDFS 上的数据,可以得到解密后的数据文件(生产环境下文件格式配置为 ORC),速度和自定义扩展的基本相等,同样实现了完美的数据机密处理。
7 小节
前面介绍了三种对指定字段进行转换处理的方法(以解密为例)的,这个也是数据迁移过程中常遇到的需求,各种方法各有优缺点。通过实现 Hive UDF 方法,虽然只能适用于 Hive,但是这样可以充分利用到 YARN 的资源,在资源充足的情况下效率最快,但当资源比较紧张时也可能需要等待,同时如果对指定字段数据涉及到频繁的查询,每次查询都要调用UDF 方法这样势必会重复处理。通过自定义 DataX Transformer UDF,虽然不能利用到 YARN ,但是本地多线程的数据处理速度也是比较快的,同时又能克服移植的问题,只需要一次开发,MySQL、Oracle 、Hive、ODPS等DataX 支持的都可以对指定字段进行转换处理,唯一需要注意的是必须修改源码。通过 DataX Transformer 已提供的方法 dx_groovy 避免了二次开发的烦恼,直接将工具包添加到 DataX 的lib 下,在 JSON 中配置上 dx_groovy 方法,并添加上 code 代码即可完整对指定字段数据的转换处理,code 代码遵循需要遵循 Groovy 编写规范,这种方法需要注意引入的外部 工具包万万不能和 DataX 原有的包冲突,需要对 code 代码片段进行测试。