Python基础(二)字符串和编码
注:本文的Python学习系列是笔者在学习廖雪峰老师的Python教程所记录下的学习笔记,如果想了解更多Python系列的学习资料可以看看 廖雪峰 Python教程
知识回顾:
在上一章的 Python基础(一)数据类型与变量学习了Python 的基本数据类型与逻辑运算符号,比较简单。这一章就一起来复习一下计算机的基础编码格式把…
一,字符编码
背景:
计算机只能处理数字,如果要处理文本,就必须要先把文本转换为数字才能处理。在最早的计算机设计时采用8个比特(bit)作为一个字节,所以一个字节能表示的最大整数就是 255(二进制 11111111 = 十进制 255),如果要表示更大的整数,就必须用更多的字节比如,2个字节能表示的最大整数是65535,4个字节能表示的最大整数是 4294967295
种类与区别:
1,由于计算机是美国人发明的,因此最早只有127个字符被编码到计算机里面去,也就是 ASCII 码。比如大写字母A 是65 ,小写字母z 是122。
(贴出来看看,看不懂也没关系…)
2,但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII码冲突,所以中国定制了 GB2312编码,用来把中文编进去。
3,你可以想到全世界有上百种语言,日本把日文编到 shift_JIS 里,韩国把韩文编到 Euc-kr 里。
各国都有自己的标准,就会不可避免的出现冲突。结果就是在多语言的混合文本里面,显示出来会有乱码。
因此,Unicode 因运而生!Unicode把所有语言都统一到一套编码里面,这样就不会出现乱码的问题了。
4,捋一捋ASCII码与Unicode码的区别。
Unicode最常用的是用两个字节表示一个字符,特殊情况下特别偏僻的字符,需要4个字节。现在大多数操作系统与编程语言都支持Unicode码。
ASCII码编码是1个字节,而Unicode码编码通常是2个字节。
列如:
字符A 用ASCII编码是十进制的65,二进制的 01000001
字符0 用ASCII编码是十进制的48,二进制的 00110000,注意字符’0’ 跟整数 0 是不一样的。
汉子’中’ 已经超出了ASCII码的范围,用Unicode编码 是十进制的 20013,二进制的 01001110 00101101
你可以猜测,如果把ASCII码的A用Unicode编码,只需要在前面补0就可以了,因此 A的Unicode码 是00000000 01000001
这样新的问题又来了,如果统一成Unicode码,那么从此乱码问题消失了。但是如果你写的文本基本上都是英文的话,用Unicode编码比ASCII码会多出一倍
的储存空间,那么在储存跟文件传输的过程中就变得十分不划算了。
所以,本着节约资源的精神,又出现把Unicode码转换成“可变长编码”的 UTF-8 编码。UTF-8编码把一个Unicode字符根据不同大小编码成1-6个字节 ,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会用 4-6个字节。如果你要传输的文本包含大量的英文字符,用UIF-8 就能节省出很多空间。
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
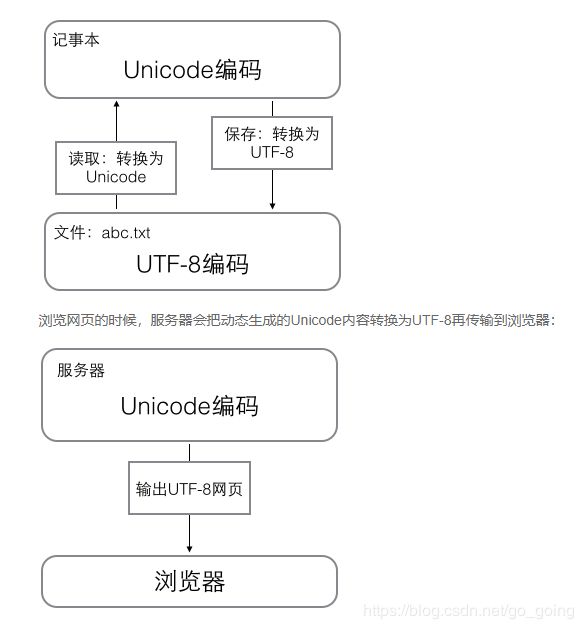
搞清楚了ASCII码,Unicode码,和UTF-8的关系,我们就可以总结一下现在计算机系统通用编码的工作方式:
1,在计算机内存中,统一使用了Unicode编码,当需要保存硬盘或者需要传输数据的时候,就转换成 UTF-8编码。
2,用记事本编辑的时候,从文件里面被读取的UTF-8字符,被转换成Unicode字符到内存里,编辑完成后,保存的时候在把Unicode转换成UTF-8保存文件。
二,Python字符串
搞清楚了让人头痛的字符编码问题后,一起来研究Python的字符串。
在最新的Python 3版本中,字符是以Unicode编码的,也就是说Python字符串支持多语言。
对于单个字符的编码,Python提供了 ord() 函数获取字符的整数表示, chr() 函数把编码转换成对应的字符
>>>ord('A')
65
>>>ord('中')
20013
>>>chr(66)
'B'
>>>chr(25991)
'文'
由于Python中的字符是 str ,在内存中用Unicode表示,一个字符对应若干字节。如果要在网络上传输,或者保存到磁盘上,就需要把str 变成以字节为单位的 bytes。
Python对 bytes类型的数据用 带b 前缀的单引号或者双引号表示:
x = b'ABC'
要注意区分’ABC’ 跟 b’abc’ ,后者虽然内容显示的跟前者一样,但bytes的每个字符都占用一个字节。
一,以Unicode表示的str 通过 encode() 方法可以编码为指定的bytes :
>>> 'ABC'.encode('ascii')
b'ABC'
>>>'中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
二,反过来,从网络上或者磁盘上读取了字节流,那么读到的数据就是 bytes,要把bytes转换成 str ,就需要用到decode() 方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
三,如果bytes中只有一小部分无效的字节,可以传入errors='ignore’忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'
四,要计算str 包含多少个字节时 可以用 len() 函数
>>> len('ABC')
3
>>> len('中文')
2
五,len() 函数在计算str 时 表示字符长度,如果是计算bytes 时就计算的字节数.
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。 当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
#-*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
如果.py文件本身使用UTF-8编码,并且也申明了# -- coding: utf-8 --,打开命令提示符测试就可以正常显示中文:
三,Python 字符串格式化
最后一个常见的问题是 如何输出格式化的字符串,我们经常会在log里面输出类似 ‘亲爱的xxx你好!你xx月的话费是xx,余额是xx’ 之类的字符串
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'
format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'