opencv3/C++ ANN神经网络字母识别
调试平台:VS2015 windows10 64位
openc版本:opencv3.4.0
本例子采用opencv 自带的ANN神经网络识别算法,训练库是我自己用1280*720的摄像头采集的,该训练库包含了大写英文字母A~Z,共26个字母,每个字母1000张样本图片,图片尺寸才30*30。
大约花了3个多小时训练完成。
word中字体样本参数设置。

训练图片样本部分截图如下:


#include
#include
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace std;
using namespace ml;
#define CLASSSUM 26 // 图片共有26类
#define IMAGE_ROWS 30 // 统一图片高度
#define IMAGE_COLS 30 // 统一图片宽度
#define IMAGESSUM 1000 // 每一类图片张数
//std::string dirNum[CLASSSUM] = { "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z" };
//std::string dirNum[CLASSSUM] = { "0", "1", "2", "3", "4", "5", "6", "7", "8", "9"};
std::string dirNum[CLASSSUM] = { "A", "B", "C", "D", "E", "F", "G", "H","I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z" };
float trainingData[CLASSSUM*IMAGESSUM][IMAGE_ROWS*IMAGE_COLS] = { { 0 } }; // 每一行一个训练图片
float labels[CLASSSUM*IMAGESSUM][CLASSSUM] = { { 0 } }; // 训练样本标签
void TestXml()
{
Ptr model = StatModel::load("./Image/English.xml");
for (int dnum = 0; dnum < CLASSSUM; dnum++)
{
std::string inPath = ".\\Image\\english\\" + dirNum[dnum] + "\\*.jpg";
intptr_t handle;
struct _finddata_t fileinfo;
handle = _findfirst(inPath.c_str(), &fileinfo);
if (handle == -1) return;
int num = 0;
int imgok = 0;
int imgnum = 0;
do {
std::string imgname = "./Image/english/" + dirNum[dnum] + "/" + fileinfo.name;
//cout << imgname << endl;
Mat srcImage = imread(imgname, 0);
//imshow("srcImage", srcImage);
//waitKey(1);
if (!srcImage.empty())
{
//将测试图像转化为1*128的向量
resize(srcImage, srcImage, Size(IMAGE_ROWS, IMAGE_COLS), (0, 0), (0, 0), INTER_AREA);
threshold(srcImage, srcImage, 0, 255, CV_THRESH_BINARY | CV_THRESH_OTSU);
Mat_ testMat(1, IMAGE_ROWS*IMAGE_COLS);
for (int i = 0; i < IMAGE_ROWS*IMAGE_COLS; i++) {
testMat.at(0, i) = (float)srcImage.at(i / IMAGE_ROWS, i % IMAGE_COLS);
}
//使用训练好的MLP model预测测试图像
Mat dst;
model->predict(testMat, dst);
//std::cout << "testMat: \n" << testMat << "\n" << std::endl;
//std::cout << "dst: \n" << dst << "\n" << std::endl;
double maxVal = 0;
Point maxLoc;
minMaxLoc(dst, NULL, &maxVal, NULL, &maxLoc);
//std::cout << dirNum[dnum] << " " << num++ << " 测试结果:" << dirNum[maxLoc.x] << "置信度:" << maxVal * 100 << "%" << std::endl;
if (dirNum[dnum] == dirNum[maxLoc.x]) {
imgok++;
}
else
{
std::string errPath = ".\\Image\\Error\\" + dirNum[dnum] + "\\" + fileinfo.name + " " + dirNum[maxLoc.x] + ".jpg";
// cout << errPath << endl;
imwrite(errPath, srcImage);
}
imgnum++;
}
} while (!_findnext(handle, &fileinfo) && imgnum < IMAGESSUM);
std::cout << dirNum[dnum] << " " << imgok << endl;
_findclose(handle);
}
}
int main()
{
#if 0
for (int i = 0; i < CLASSSUM; i++)
{
int k = 0;
std::string inPath = ".\\Image\\english\\" + dirNum[i] + "\\*.jpg";
intptr_t handle;
struct _finddata_t fileinfo;
handle = _findfirst(inPath.c_str(), &fileinfo);
if (handle == -1) return -1;
do {
std::string imgname = "./Image/english/" + dirNum[i] + "/" + fileinfo.name;
cout << imgname << endl;
Mat srcImage = imread(imgname, 0);
if (srcImage.empty()) {
std::cout << "Read image error:" << imgname << std::endl;
return -1;
}
resize(srcImage, srcImage, Size(IMAGE_ROWS, IMAGE_COLS), (0, 0), (0, 0), INTER_AREA);
threshold(srcImage, srcImage, 0, 255, CV_THRESH_BINARY | CV_THRESH_OTSU);
for (int j = 0; jmodel = ANN_MLP::create();
Mat layerSizes = (Mat_(1, 5) << IMAGE_ROWS*IMAGE_COLS, 128, 128, 128, CLASSSUM);
model->setLayerSizes(layerSizes);
model->setTrainMethod(ANN_MLP::BACKPROP, 0.001, 0.1);
model->setActivationFunction(ANN_MLP::SIGMOID_SYM, 1.0, 1.0);
model->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER | TermCriteria::EPS, 10000, 0.0001));
Ptr trainData = TrainData::create(trainingDataMat, ROW_SAMPLE, labelsMat);
model->train(trainData);
model->save("./Image/English.xml"); //保存训练结果
#endif
// 测试训练结果
cout << "------------------test-------------------" << endl;
TestXml();
cout << "------------------end-------------------" << endl;
waitKey(0);
while (1);
return 0;
}
执行结果如下:
使用样本进行识别测试,26个字母,1000张样本,成功率100%。
实际测试效果演示如下,目前稍微测试了下,尚未发现识别错误的情况:
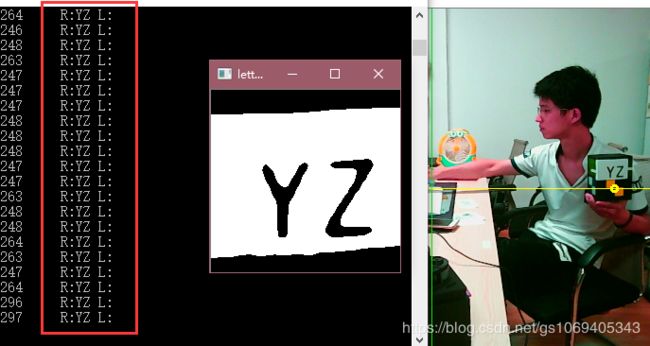
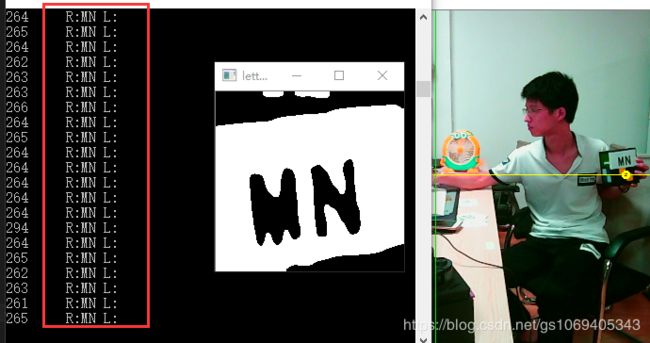
训练样本图片下载:
https://download.csdn.net/download/gs1069405343/11505319
源码下载
https://download.csdn.net/download/gs1069405343/11505454