什么是增量刷新
所谓增量刷新,是指增量刷新数据。一般情况下,在PowerBI或PowerBI Desktop中点击【刷新】按钮,会将数据源的数据全部刷新一遍,如果数据源数据很多,而每次变化的很少,例如只有最近一日发生变化,那这种不问青红皂白就直接全部刷新的方法显然会耗时耗力。很可惜在默认情况下,PowerBI就只支持这种数据刷新方式。
随着2018年5月PowerBI的升级,Premium开始支持真增量刷新,本文来说明目前可以用来在PowerBI中实现增量数据刷新的技巧。
在PowerBI中实现增量刷新,目前有三种方法:
- 用 PowerQuery M 实现增量刷新,该方法有一定限制,属于假增量刷新。
- 用 DAX 实现增量刷新,该方法也有一定限制,属于假增量刷新。
- 用 Power BI Premium 实现增量刷新,该方法也有一定限制,但属于真增量刷新。
数据场景假设
假设这里有不断在更新的订单表,首先加载2011年到2013年数据,而每次数据刷新只刷新2014年数据,以下的方案应该如何实现呢。
用 PowerQuery M 实现增量刷新
用 PowerQuery M 实现增量刷新的核心技巧在于:查询的纵向合并。这里可以节省的时间在于网络传输的时间,方案如下:
- 首先将远程历史数据通过任何查询形式保存在本机。
- 查询本机历史数据再纵向合并远程的增量数据。
这样一来,每次历史数据的获取只是读取本机磁盘的时间,而不再产生网络传输的时间消耗,进而在一定程度上缓解了数据刷新的时间瓶颈问题。
再使用PowerQuery M的纵向合并表查询把几个查询合并成最终结果,完成增量刷新的效果。如下:
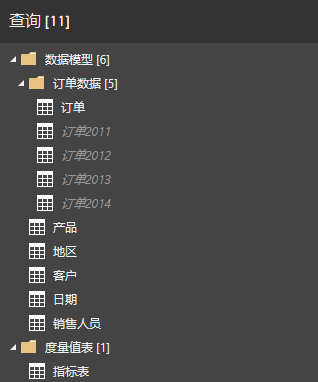
其中订单是由其他的订单数据合并而来,对应的PowerQuery M查询如下:
订单 = Table.Combine( { #"订单2011", #"订单2012", #"订单2013", #"订单2014" } )
可以把订单2011~2013的数据置于本地服务器或PC,在刷新时,虽然会全部刷新,但由于数据可以预先置于本地,则可以有效降低数据的网络传输时间。
另外,如果该模型发布到云端,显然都会有网络传输时间,但可以节省的是,数据在PQ中ETL的时间,可以预先将数据用PQ(或其他ETL工具)进行ETL后进行保存。在实际查询时会节省ETL的时间。
当然,这种方法并不是真正意义上的增量刷新,属于利用了PowerQuery或者说ETL可以缓冲数据存储的思想。
用 DAX 实现增量刷新
由于使用PowerQuery的方式实现假增量刷新是数据进入数据模型前,所以仍然要刷新所有数据,因此并没有降低模型对数据的吞吐量。在数据加载进入数据模型之后,我们也可以实现增量刷新的效果,使用DAX的UNION函数将多个表纵向合并即可。对此,我们设计的结构如下:
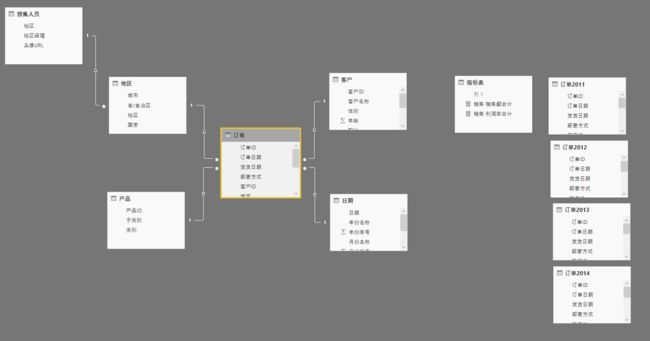
这里需要将订单2011~2014全部加载进入模型,但可以设置只有订单2014包含在报表刷新中,如下:
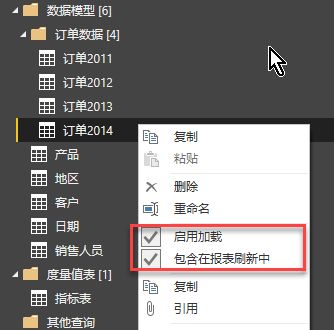
这样每次刷新数据的时候,只有最后一组订单数据(订单2014)会被刷新,如下:
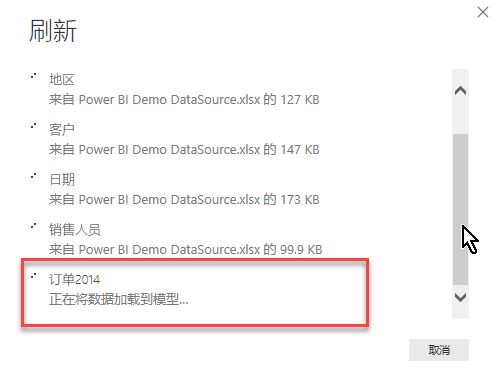
用DAX实现合并的函数表达式如下:
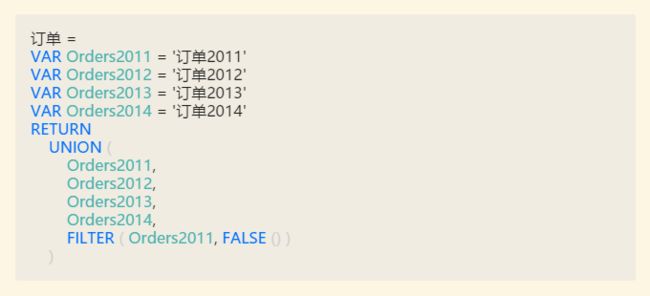
这里面最后一行的FILTER一定会让人困惑不解。没错,不要这句也是没问题的,但它是为了解决下面这个问题了准备的。
有伙伴问到:如果一开始订单是正常加载的,那就无法被UNION了。没错,因为订单这个表名已经存在,以后再想UNION是没办法的。这时候可以尝试:
- 将原有订单拆分成增量加载形式。
- 删除加载的订单,此时数据模型会出现大量报错,因为没有了订单这个表。
- 用UNION的方式合成新表并命名为订单,并补足关系,理论上可以修复所有的错误。但在实际实践中,可能并不能修复所有错误,仍然有大量错误存在,这视具体实际情况而定。
因此,这种删除后重新用DAX计算表的方式弥补订单存在风险,务必备份数据。
一种未雨绸缪的做法是,在建模初期就预料到某些表会很大,可能需要增量加载,那可以直接使用计算表,但此时如果只有一个表怎么办,也就是说,必须实现一个表的UNION作为占位符。由于DAX的UNION函数必须至少有两个参数,且这两个参数必须都是列数一样的表,所以使用FILTER的这句技巧实际返回一个空表与前面的表合并,以起到占位符的作用,待有真正需要合并的表的时候,再做替换。
提示
当然,在只有一个表的时候使用计算表可以不用UNION以更加简单。
这样,就使用DAX的UNION实现了增量刷新的效果,并且该效果确实起到了增量加载数据,但根据DAX引擎的原理,整个数据模型会重建,仍需花费时间,这里省去了数据加载的时间,但无法省去模型重建的时间。另外的一个缺陷是,同样的数据在模型中保留了两份。
经过实际测试,该方法确实可以显著降低模型生成的时间,具体情况以实际为准。
用 Power BI Premium 实现增量刷新
Power BI 5月更新的预览功能中,已经给出了Power BI正统实现增量刷新的方法,但就是在Power BI Desktop只是进行设置,实际到Power BI Service的Premium专有容量中再进行实际阶段的增量加载,由于Power BI Premium允许单个数据模型可超过50G且数据存储达到100T(参考:Microsoft Power BI Premium 白皮书),这个量级的数据在本地PC或Power BI Desktop是无法进行的,而Power BI Premium却提供了这样的能力。如果在Power BI Desktop设置好增量刷新,效果如下:
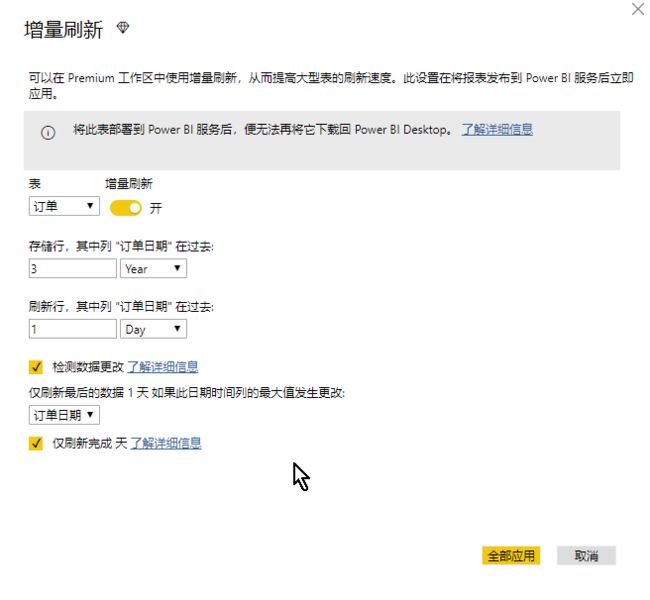
其含义为:
- 将订单表增量刷新
- 存储最后3年的数据行
- 刷新最后1日的数据行
- 在检测到数据更改时触发刷新动作
在Power BI Desktop设计好后,发布的时候会看到:
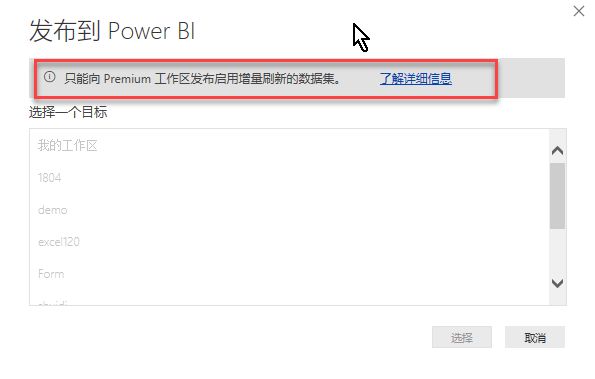
由于设置了增量刷新,必须发布到含有Premium容量的工作区,否则是无法发布的。
很多伙伴会问,在你自己设置增量刷新的时候,不会成功,会提示这样的错误:
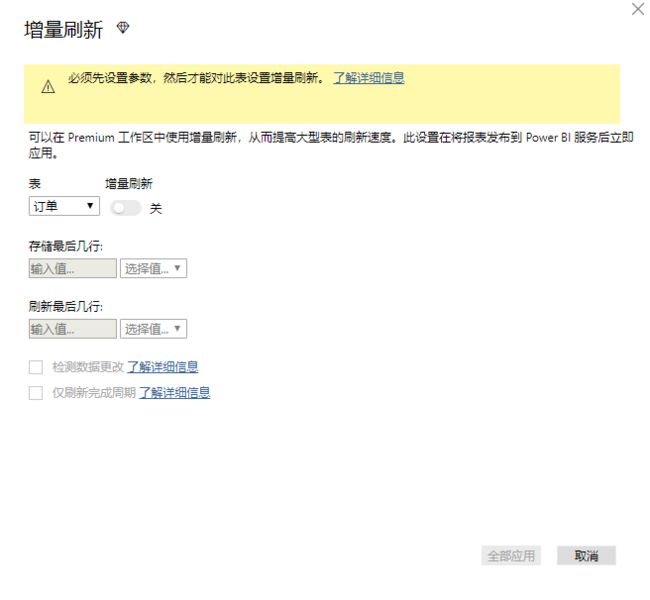
你会发现,无论你怎么设置参数都不对,这里有几个非常重要的细节需要指出:
- 必须在查询编辑中设置参数,且参数的数据类型必须是【日期/时间】,日期型也是不对的。
- 设置的参数必须起名为RangeStart和RangeEnd分别表示时间的开始和结束。参数名用别的也是不对的。
- 对需要增量更新的表,如:订单,让订单日期被上述的两个参数所筛选。
如下:
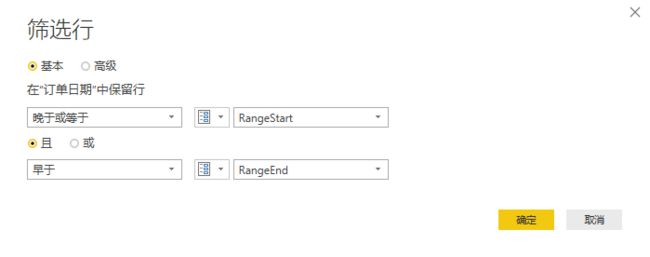
只有满足了以上设置,增量刷新才会乖乖出来给你用。
这种方法当然是真增量刷新,而且可以应对多达100T的数据存储以及单个100G的数据模型,这个能力非常强大,当然,为此付出的代价就是必须购买5K美金/月起步(注意:是起步,实际以定价估算计算器为准)的Power BI Premium服务。
但如果仔细算一笔账,其实这也并非绝不合理,5K美金/月大致为30000RMB/月,相当于一个IT工程师的月薪,而有了Premium,可以不再需要IT工程师来搭建和维护数据环境,这其实是相当的。而这个环境可以支撑多达100T的数据量级以及单个100G的数据模型,足以应付企业级数据分析需求。
总结
本文整体分析并实际演示了在Power BI中实现数据增量刷新的各种方法以及各自优缺点:
- PQ M 方法:简单且便于维护,但并非真正增量刷新,只能节省网络传输和部分ETL的时间。
- DAX 方法:可以在Power BI模型限制范围内部分降低数据加载时间,但要注意在项目开始引入以便避免后期问题。
- PowerBI Premium方法:终极的数据增量刷新方法,支持多达100T的数据存储以及单个数据模型可以超过50G且每天可以刷新48次,但费用昂贵,属于企业级解决方案。
【本案例包括案例示例文件以及视频详细说明,可订阅获取】