【NLP】详聊NLP中的阅读理解(MRC)
机器阅读理解,笔者认为他是NLP中最有意思的任务了。机器阅读一份文档之后,可以“理解”其中的内容,并可以回答关于这份文档的问题。听上去,有一种很强的“人工智能”的Feel。
这篇文章介绍机器阅读理解(Machine Reading
Comprehension),包括MRC的概况、做法以及主要模型。
作者&编辑 | 小Dream哥
目标
目前来讲,还没有一种NLP技术,能够端到端的实现对文本的理解。通常是转化位不同的NLP任务,来实现对文本不同层面的“理解”,例如如下的任务:
词性识别
命名实体识别
句法依存
句法依存
MRC也是一种理解文本的任务,它的大体模式是:机器阅读文档,并回答相关的问题。
这跟我们做英语的阅读理解题目是非常的相似,阅读一篇英文章之后,基于此,做后面的几道选择题或者填空题。
MRC发展概况
在MRC的早期主要是一些基于规则和机器学习方法的MRC系统:
1997,QUALM system
1999. Reading Comprehension dataset by Hirschman et al
1999 Deep Read System (rule-based BOW model)
2000 QUARC system (rule-based)
2013-2015 MCTest(and 4 on1) and ProcessBank(Y/N) dataset
2014 Statistical Model
Machine learning Models(map the question to formal queries)
上述基于规则的系统,通常能够获得30-40%的准确率,机器学习模型取得了一些进展,但也有一些问题,例如:
严重依赖一些基于语法和语言学的工具
数据集太小
基于现有的语言学工具,很难特征构建有效的特征
随着深度学习时代的到来,这种情况得到了很大的改上,出现了如下的模型是数据集:
2015. The Attentive Reader(Hermann et al). Achieved 63% accuracy
2015 CNN and Daily Mail
2016 Children Book Test
2016 The Stanford Question Answer Dataset (SQUAD 1)
2017 Match-LSTM,BiDAF,TrivalQA,R-net,RACE
2018. QANet, NarrativeQA ,BiDAF+self-attention+ELMO,SQuAD 2.0, The Standford Attentive Reader,BERT, HotPotQA
我们现在来正式的定义一下基于神经网络的MRC:
给定一个训练数据集{P,Q,A},目标是学习一个函数f:
f(p,q)-> a
其中,P是文档集,Q是问题集,A是答案集。
根据Answer的类型,我们可以把目前的MRC系统分为以下4类:
完形填空类型(cloze)
多项选择(Multiple Choice)
Span Prdiction
Free-From answer
The Standford Attentive Reader
如下图所示,展示了Stanford Attentive Reader模型结构图
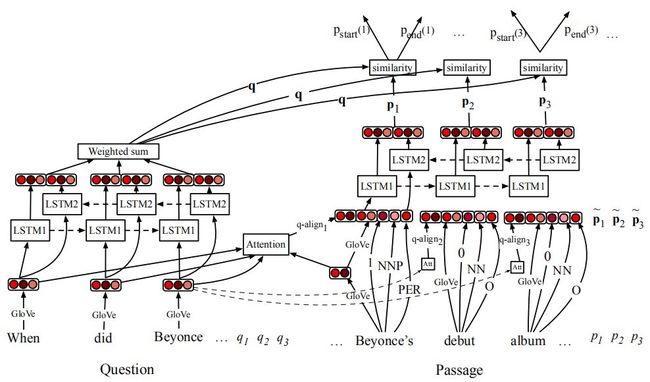
这里的SAR主要用来解决的是span prediction的MRC问题。设给定一篇文章p,长度位l1;同时给定一个问题q,长度位l2;目的是预测一个span(start,end),start和end是P上词位置,并且这个span是这个问题的答案。
模型将这个任务转化为序列上的二分类问题,即对于文章中的每个词,都预测这个词分别是start和end的得分,最后用这个分数来预测span。
1)question部分的编码
主要是对question进行编码,先经过embedding层,而后用BiLSTM进行序列建模,最终每个词的表征为:
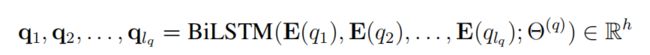
然后,接一个带权重的softmax,得到一个编码向量q,如下的公式所示:
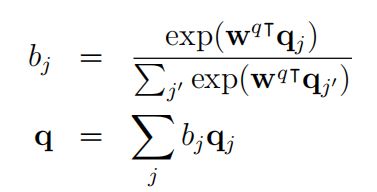
2)Passage编码部分
Passage的编码也是先经过embedding,再通过BiLSTM进行序列建模,最终每个词的表征为:
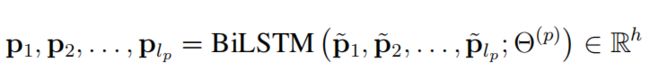
需要注意的是,输入BiLSTM的emdedding向量是由4部分concate而成的:
Glove生成的embedding
embedding对齐特征,通过与q的embedding做attention而得到
词性特征
实体类型特征
3)prediction部分
简单来说就n个二分类,根据q和p分别预测每个词是start及end的概率:

4)损失函数
训练过程中采用的损失函数如下:
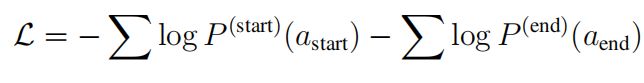
这个模型还可以转化为上述的cloze,multiple-choice等类型的MRC任务,做一些简单的调整即可。
我们前面还介绍过,如何基于BERT来做MRC的任务,感兴趣的读者可以看看:
【NLP】如何利用BERT来做基于阅读理解的信息抽取
总结
基于MRC可以完成知识抽取、QA等重要的NLP任务,读者务必熟悉。
读者们可以留言,或者加入我们的NLP群进行讨论。感兴趣的同学可以微信搜索jen104,备注"加入有三AI NLP群"。
下期预告:暂无
知识星球推荐

扫描上面的二维码,就可以加入我们的星球,助你成长为一名合格的自然语言处理算法工程师。
知识星球主要有以下内容:
(1) 聊天机器人;
(2) 知识图谱;
(3) NLP预训练模型。
转载文章请后台联系
侵权必究


往期精选
【完结】 12篇文章带你完全进入NLP领域,掌握核心技术
【年终总结】2019年有三AI NLP做了什么,明年要做什么?
【NLP-词向量】词向量的由来及本质
【NLP-词向量】从模型结构到损失函数详解word2vec
【NLP-NER】什么是命名实体识别?
【NLP-NER】命名实体识别中最常用的两种深度学习模型
【NLP-NER】如何使用BERT来做命名实体识别
【NLP-ChatBot】我们熟悉的聊天机器人都有哪几类?
【NLP-ChatBot】搜索引擎的最终形态之问答系统(FAQ)详述
【NLP-ChatBot】能干活的聊天机器人-对话系统概述
【知识图谱】人工智能技术最重要基础设施之一,知识图谱你该学习的东西
【知识图谱】知识表示:知识图谱如何表示结构化的知识?
【知识图谱】如何构建知识体系:知识图谱搭建的第一步
【知识图谱】获取到知识后,如何进行存储和便捷的检索?
【知识图谱】知识推理,知识图谱里最“人工智能”的一段
【文本信息抽取与结构化】目前NLP领域最有应用价值的子任务之一
【文本信息抽取与结构化】详聊文本的结构化【上】
【文本信息抽取与结构化】详聊文本的结构化【下】
【NLP实战】tensorflow词向量训练实战
【NLP实战系列】朴素贝叶斯文本分类实战
【NLP实战系列】Tensorflow命名实体识别实战
【NLP实战】如何基于Tensorflow搭建一个聊天机器人
【NLP实战】基于ALBERT的文本相似度计算
【每周NLP论文推荐】从预训练模型掌握NLP的基本发展脉络
【每周NLP论文推荐】 NLP中命名实体识别从机器学习到深度学习的代表性研究
【每周NLP论文推荐】 介绍语义匹配中的经典文章
【每周NLP论文推荐】 对话管理中的标志性论文介绍
【每周NLP论文推荐】 开发聊天机器人必读的重要论文
【每周NLP论文推荐】 掌握实体关系抽取必读的文章
【每周NLP论文推荐】 生成式聊天机器人论文介绍
【每周NLP论文推荐】 知识图谱重要论文介绍