【深度学习技术】Softmax和SVM的区别与比较
本博客记录Softmax 和SVM分类器的学习过程,欢迎学习交流。
目前解决图像分类问题,比较流行的方法是卷积神经网络上。这种方法主要有两部分组成:一个是评分函数(score function),它是原始图像数据到类别分值的映射。另一个是损失函数(loss function),它是用来量化预测分类标签的得分与真实标签之间一致性的。该方法可转化为一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数值。
1.线性分类器
1.线性分类器
![]()
2.理解线性分类器
线性分类器计算图像中3个颜色通道中所有像素的值与权重的矩阵乘,从而得到分类分值。根据我们对权重设置的值,对于图像中的某些位置的某些颜色,函数表现出喜好或者厌恶(根据每个权重的符号而定)。举个例子,可以想象“船”分类就是被大量的蓝色所包围(对应的就是水)。那么“船”分类器在蓝色通道上的权重就有很多的正权重(它们的出现提高了“船”分类的分值),而在绿色和红色通道上的权重为负的就比较多(它们的出现降低了“船”分类的分值)。

一个将图像映射到分类分值的例子。为了便于可视化,假设图像只有4个像素(都是黑白像素,这里不考虑RGB通道),有3个分类(红色代表猫,绿色代表狗,蓝色代表船,注意,这里的红、绿和蓝3种颜色仅代表分类,和RGB通道没有关系)。首先将图像像素拉伸为一个列向量,与W进行矩阵乘,然后得到各个分类的分值。需要注意的是,这个W一点也不好:猫分类的分值非常低。从上图来看,算法倒是觉得这个图像是一只狗。
3.将图像看做高维度的点
既然图像被伸展成为了一个高维度的列向量,那么我们可以把图像看做这个高维度空间中的一个点(即每张图像是3072维空间中的一个点)。整个数据集就是一个点的集合,每个点都带有1个分类标签。
既然定义每个分类类别的分值是权重和图像的矩阵乘,那么每个分类类别的分数就是这个空间中的一个线性函数的函数值。我们没办法可视化3072维空间中的线性函数,但假设把这些维度挤压到二维,那么就可以看看这些分类器在做什么了:

图像空间的示意图。其中每个图像是一个点,有3个分类器。以红色的汽车分类器为例,红线表示空间中汽车分类分数为0的点的集合,红色的箭头表示分值上升的方向。所有红线右边的点的分数值均为正,且线性升高。红线左边的点分值为负,且线性降低。
2.损失函数
2.1多类支持向量机损失 Multiclass Support Vector Machine Loss
SVM的损失函数定义:
![]()
折叶损失(hinge loss)
定义如下:
![]()
平方折叶损失(hinge loss)
定义如下:
![]()
边界损失:

SVM举例说明:

用预测错误的得分减去预测正确的得分加上一个容错

N为图片样本的个数,损失函数的大小不和样本图片的数量有关系。
2.2 正则化(Regularization)
为什么要正则化?

权重w1和权重w2对输入的评分结果相同都是1,但是w1只考虑第一个像素,w2把每一个像素都考虑进去了,可知要得到相同的评分结果的权重参数w可能是无穷多个的。
存在问题:假设有一个数据集和一个权重集W能够正确地分类每个数据(即所有的边界都满足,对于所有的i都有L_i=0)。问题在于这个W并不唯一:可能有很多相似的W都能正确地分类所有的数据。
换句话说,我们希望能向某些特定的权重W添加一些偏好,对其他权重则不添加,以此来消除模糊性。这一点是能够实现的,方法是向损失函数增加一个
正则化惩罚(regularization penalty)
![]()
上面的表达式中,将W中所有元素平方后求和。
所以一个完整的损失函数由两个部分组成:数据损失(data loss),即所有样例的的平均损失L_i,以及正则化损失(regularization loss)。
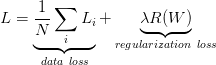
又加了一个正则化惩罚项,惩罚就是惩罚权重参数,一般用L2惩罚,对输入的每个参数进行平方计算。
损失函数的最终版:
![]()
N是训练集的数据量,λ是权重。
正则化项在神经网络中的重要作用::

3.Softmax
SVM得到的是得分值,并不是确定的概率值,可以通过sigmoid函数把输入为任意数的得分值转化为概率值。
Softmax分类器使用交叉熵损失(cross-entropy loss)
softmax函数
softmax函数:
![]()
和SVM 分类器一样,整个数据集的损失值是数据集中所有样本数据的损失Li的均值与正则化损失R(W)之和。
举例如下:

如何求分类的概率?
把得分值取e操作,让大的更大,小的更小,然后求概率。
如何求损失?
对于概率再取log运算。
![]()
![]()
Softmax时一个永远不知道满足的分类器。