后缀树/后缀数组
字典树:https://blog.csdn.net/hebtu666/article/details/83141560
后缀树:后缀树,就是把一串字符的所有后缀保存并且压缩的字典树。
相对于字典树来说,后缀树并不是针对大量字符串的,而是针对一个或几个字符串来解决问题。比如字符串的回文子串,两个字符串的最长公共子串等等。
比如单词banana,它的所有后缀显示到下面的。0代表从第一个字符为起点,终点不用说都是字符串的末尾。
以上面的后缀,我们建立一颗后缀树。如下图,为了方便看到后缀,我没有合并相同的前缀。
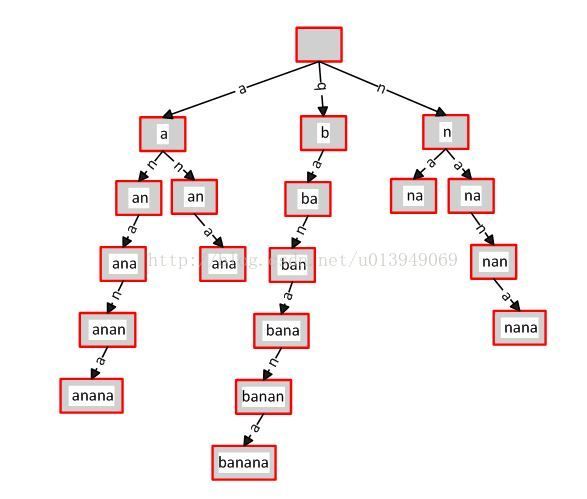
把非公共部分压缩:
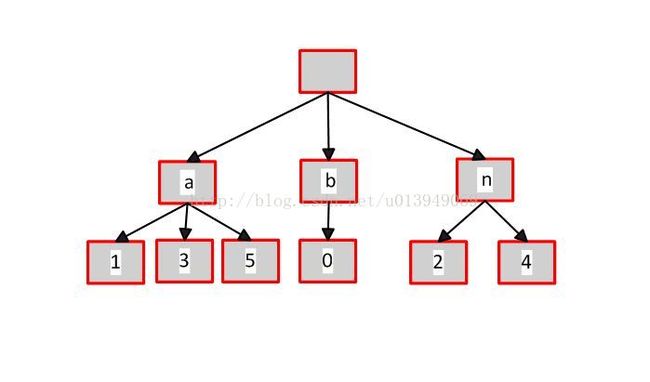
![]()
后缀树的应用:
(1)查找某个字符串s1是否在另外一个字符串s2中:如果s1在字符串s2中,那么s1必定是s2中某个后缀串的前缀。
(2)指定字符串s1在字符串s2中重复的次数:比如说banana是s1,an是s2,那么计算an出现的次数实际上就是看an是几个后缀串的前缀。
(3)两个字符串S1,S2的最长公共部分(广义后缀树)
(4)最长回文串(广义后缀树)
关于后缀树的实现和应用以后再写,这次主要写后缀数组。
在字符串处理当中,后缀树和后缀数组都是非常有力的工具。其实后缀数组是后缀树的一个非常精巧的替代品,它比后缀树容易编程实现,能够实现后缀树的很多功能而时间复杂度也不太逊色,并且,它比后缀树所占用的空间小很多。可以说,在信息学竞赛中后缀数组比后缀树要更为实用。
后缀数组:就是把某个字符串的所有后缀按照字典序排序后的数组。(数组中保存起始位置就好了,结束位置一定是最后)
先说如何计算后缀数组:
倍增的思想,我们先把每个长度为2的子串排序,再利用结果把每个长度为4的字串排序,再利用结果排序长度为8的子串。。。直到长度大于等于串长。
设置sa[]数组来记录排名:sa[i]代表排第i名的是第几个串。
结果用rank[]数组返回,rank[i]记录的是起始位置为第i个字符的后缀排名第几小。
我们开始执行过程:
比如字符串abracadabra
长度为2的排名:a ab ab ac ad br br ca da ra ra,他们分别排第0,1,2,2,3,4,5,5,6,7,8,8名
sa数组就是11(空串),10(a),0(ab),7,3,5,1,8,4,6,2,9(ra排名最后)
这样,所有长度为2的子串的排名就出来了,我们如何利用排名把长度为4的排名搞出来呢?
abracadabra中,ab,br,ra这些串排名知道了。我们把他们两两合并为长度为4的串,进行排名。
比如abra和brac怎么比较呢?
用原来排名的数对来表示
abra=ab+ra=1+8
brac=br+ac=4+2
对于字符串的字典序,这个例子比1和4就比出来了。
如果第一个数一样,也就是前两个字符一样,那再比后面就可以了。
简单说就是先比前一半字符的排名,再比后一半的排名。
具体实现,我们可以用系统sort,传一个比较器就好了。
还有需要注意,长度不可能那么凑巧是2^n,所以 一般的,k=n时,rank[i]表示从位置i开始向后n个字符的排名第几小,而剩下不足看个字符,rank[i]代表从第i个字符到最后的串的排名第几小,也就是后缀。
保证了每一个后缀都能正确表示并排序。比如k=4时,就表示出了长度为1,2,3的后缀:a,ra,bra.这就保证了k=8时,长度为5,6,7的后缀也能被表示出来:4+1,4+2,4+3
还有,sa[0]永远是空串,空串的排名rank[sa[0]]永远是最大。
int n;
int k;
int rank[MAX_N+1];//结果(排名)数组
int tmp[MAX_N+1];//临时数组
//定义比较器
bool compare(int i,int j)
{
if(rank[i]!=rank[j])return rank[i]具体应用以后再写。。。。。