[转]Ceph:OpenStack标配&Linux PB级分布式文件系统详解
Ceph:一个 Linux PB 级分布式文件系统
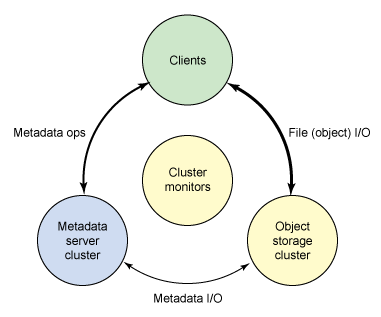
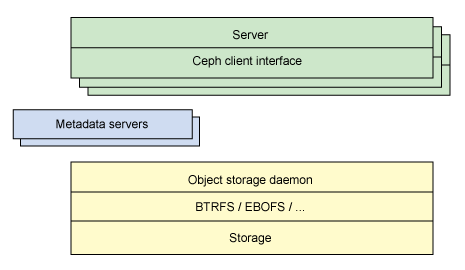
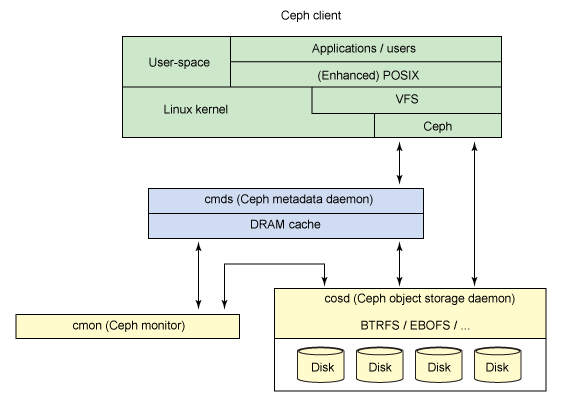
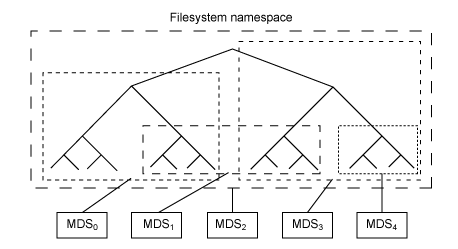
来源:http://www.ibm.com/developerworks/cn/linux/l-ceph/
Ceph架构剖析
1. 介绍
云硬盘是IaaS云平台的重要组成部分,云硬盘给虚拟机提供了持久的块存储设备。目前的AWS 的EBS(Elastic Block store)给Amazon的EC2实例提供了高可用高可靠的块级存储卷,EBS适合于一些需要访问块设备的应用,比如数据库、文件系统等。 在OpenStack中,可以使用Ceph、Sheepdog、GlusterFS作为云硬盘的开源解决方案,下面我们来了解Ceph的架构。
Ceph是统一存储系统,支持三种接口。
- Object:有原生的API,而且也兼容Swift和S3的API
- Block:支持精简配置、快照、克隆
- File:Posix接口,支持快照
Ceph也是分布式存储系统,它的特点是:
- 高扩展性:使用普通x86服务器,支持10~1000台服务器,支持TB到PB级的扩展。
- 高可靠性:没有单点故障,多数据副本,自动管理,自动修复。
- 高性能:数据分布均衡,并行化度高。对于objects storage和block storage,不需要元数据服务器。
2. 背景
目前Inktank公司掌控Ceph的开发,但Ceph是开源的,遵循LGPL协议。Inktank还积极整合Ceph和其他云计算和大数据平台,目前Ceph支持OpenStack、CloudStack、OpenNebula、Hadoop等。
当前Ceph的最新稳定版本0.67(Dumpling),它的objects storage和block storage已经足够稳定,而且Ceph社区还在继续开发新功能,包括跨机房部署和容灾、支持Erasure encoding等。Ceph具有完善的社区设施和发布流程[1](每三个月发布一个稳定版本) 。
目前Ceph有很多用户案列,这是2013.03月Inktank公司在邮件列表中做的调查,共收到了81份有效反馈[2]。从调查中可以看到有26%的用户在生产环境中使用Ceph,有37%的用户在私有云中使用Ceph,还有有16%的用户在公有云中使用Ceph。
目前Ceph最大的用户案例是Dreamhost的Object Service,目前总容量是3PB,可靠性达到99.99999%,数据存放采用三副本,它的价格比S3还便宜。下图中,左边是Inktank的合作伙伴,右边是Inktank的用户。
3. 架构
3.1 组件
Ceph的底层是RADOS,它的意思是“A reliable, autonomous, distributed object storage”。 RADOS由两个组件组成:
- OSD: Object Storage Device,提供存储资源。
- Monitor:维护整个Ceph集群的全局状态。
RADOS具有很强的扩展性和可编程性,Ceph基于RADOS开发了
Object Storage、Block Storage、FileSystem。Ceph另外两个组件是:
- MDS:用于保存CephFS的元数据。
- RADOS Gateway:对外提供REST接口,兼容S3和Swift的API。
3.2 映射
Ceph的命名空间是 (Pool, Object),每个Object都会映射到一组OSD中(由这组OSD保存这个Object):
(Pool, Object) → (Pool, PG) → OSD set → Disk
Ceph中Pools的属性有:
- Object的副本数
- Placement Groups的数量
- 所使用的CRUSH Ruleset
在Ceph中,Object先映射到PG(Placement Group),再由PG映射到OSD set。每个Pool有多个PG,每个Object通过计算hash值并取模得到它所对应的PG。PG再映射到一组OSD(OSD的个数由Pool 的副本数决定),第一个OSD是Primary,剩下的都是Replicas。
数据映射(Data Placement)的方式决定了存储系统的性能和扩展性。(Pool, PG) → OSD set 的映射由四个因素决定:
- CRUSH算法:一种伪随机算法。
- OSD MAP:包含当前所有Pool的状态和所有OSD的状态。
- CRUSH MAP:包含当前磁盘、服务器、机架的层级结构。
- CRUSH Rules:数据映射的策略。这些策略可以灵活的设置object存放的区域。比如可以指定 pool1中所有objecst放置在机架1上,所有objects的第1个副本放置在机架1上的服务器A上,第2个副本分布在机架1上的服务器B上。 pool2中所有的object分布在机架2、3、4上,所有Object的第1个副本分布在机架2的服务器上,第2个副本分布在机架3的服 器上,第3个副本分布在机架4的服务器上。
Client从Monitors中得到CRUSH MAP、OSD MAP、CRUSH Ruleset,然后使用CRUSH算法计算出Object所在的OSD set。所以Ceph不需要Name服务器,Client直接和OSD进行通信。伪代码如下所示:
locator = object_name obj_hash = hash(locator) pg = obj_hash % num_pg osds_for_pg = crush(pg) # returns a list of osds primary = osds_for_pg[0] replicas = osds_for_pg[1:]
这种数据映射的优点是:
- 把Object分成组,这降低了需要追踪和处理metadata的数量(在全局的层面上,我们不需要追踪和处理每个object的metadata和placement,只需要管理PG的metadata就可以了。PG的数量级远远低于object的数量级)。
- 增加PG的数量可以均衡每个OSD的负载,提高并行度。
- 分隔故障域,提高数据的可靠性。
3.3 强一致性
- Ceph的读写操作采用Primary-Replica模型,Client只向Object所对应OSD set的Primary发起读写请求,这保证了数据的强一致性。
- 由于每个Object都只有一个Primary OSD,因此对Object的更新都是顺序的,不存在同步问题。
- 当Primary收到Object的写请求时,它负责把数据发送给其他Replicas,只要这个数据被保存在所有的OSD上时,Primary才应答Object的写请求,这保证了副本的一致性。
3.4 容错性
在分布式系统中,常见的故障有网络中断、掉电、服务器宕机、硬盘故障等,Ceph能够容忍这些故障,并进行自动修复,保证数据的可靠性和系统可用性。
- Monitors是Ceph管家,维护着Ceph的全局状态。Monitors的功能和zookeeper类似,它们使用Quorum和Paxos算法去建立全局状态的共识。
- OSDs可以进行自动修复,而且是并行修复。
故障检测:
OSD之间有心跳检测,当OSD A检测到OSD B没有回应时,会报告给Monitors说OSD B无法连接,则Monitors给OSD B标记为down状态,并更新OSD Map。当过了M秒之后还是无法连接到OSD B,则Monitors给OSD B标记为out状态(表明OSD B不能工作),并更新OSD Map。
备注:可以在Ceph中配置M的值。
故障恢复:
- 当某个PG对应的OSD set中有一个OSD被标记为down时(假如是Primary被标记为down,则某个Replica会成为新的Primary,并处理所有读写 object请求),则该PG处于active+degraded状态,也就是当前PG有效的副本数是N-1。
- 过了M秒之后,假如还是无法连接该OSD,则它被标记为out,Ceph会重新计算PG到OSD set的映射(当有新的OSD加入到集群时,也会重新计算所有PG到OSD set的映射),以此保证PG的有效副本数是N。
- 新OSD set的Primary先从旧的OSD set中收集PG log,得到一份Authoritative History(完整的、全序的操作序列),并让其他Replicas同意这份Authoritative History(也就是其他Replicas对PG的所有objects的状态达成一致),这个过程叫做Peering。
- 当Peering过程完成之后,PG进 入active+recoverying状态,Primary会迁移和同步那些降级的objects到所有的replicas上,保证这些objects 的副本数为N。
4. 优点
4.1 高性能
- Client和Server直接通信,不需要代理和转发
- 多个OSD带来的高并发度。objects是分布在所有OSD上。
- 负载均衡。每个OSD都有权重值(现在以容量为权重)。
- client不需要负责副本的复制(由primary负责),这降低了client的网络消耗。
4.2 高可靠性
- 数据多副本。可配置的per-pool副本策略和故障域布局,支持强一致性。
- 没有单点故障。可以忍受许多种故障场景;防止脑裂;单个组件可以滚动升级并在线替换。
- 所有故障的检测和自动恢复。恢复不需要人工介入,在恢复期间,可以保持正常的数据访问。
- 并行恢复。并行的恢复机制极大的降低了数据恢复时间,提高数据的可靠性。
4.2 高扩展性
- 高度并行。没有单个中心控制组件。所有负载都能动态的划分到各个服务器上。把更多的功能放到OSD上,让OSD更智能。
- 自管理。容易扩展、升级、替换。当组件发生故障时,自动进行数据的重新复制。当组件发生变化时(添加/删除),自动进行数据的重分布。
5. 测试
使用fio测试RBD的IOPS,使用dd测试RBD的吞吐率,下面是测试的参数:
- fio的参数:bs=4K, ioengine=libaio, iodepth=32, numjobs=16, direct=1
- dd的参数:bs=512M,oflag=direct
我们的测试服务器是AWS上最强的实例:
- 117GB内存
- 双路 E5-2650,共16核
- 24 * 2TB 硬盘
服务器上的操作系统是Ubuntu 13.04,安装Ceph Cuttlefish 0.61版,副本数设置为2,RBD中的块大小设置为1M。为了对比,同时还对软件RAID10进行了测试。下面表格中的性能比是Ceph与RAID10性能之间的比较。
5.1 注意
因为使用的是AWS上的虚拟机,所以它(Xen)挂载的磁盘都是设置了Cache的。因此下面测试的数据并不能真实反应物理磁盘的真实性能,仅供与RAID10进行对比。
5.2 IOPS
| 磁盘数 | 随机写 | 随机读 | ||||
|---|---|---|---|---|---|---|
| Ceph | RAID10 | 性能比 | Ceph | RAID10 | 性能比 | |
| 24 | 1075 | 3772 | 28% | 6045 | 4679 | 129% |
| 12 | 665 | 1633 | 40% | 2939 | 4340 | 67% |
| 6 | 413 | 832 | 49% | 909 | 1445 | 62% |
| 4 | 328 | 559 | 58% | 666 | 815 | 81% |
| 2 | 120 | 273 | 43% | 319 | 503 | 63% |
5.3 吞吐率
| 磁盘数 | 顺序写(MB/S) | 顺序读(MB/S) | ||||
|---|---|---|---|---|---|---|
| Ceph | RAID10 | 性能比 | Ceph | RAID10 | 性能比 | |
| 24 | 299 | 879 | 33% | 617 | 1843 | 33% |
| 12 | 212 | 703 | 30% | 445 | 1126 | 39% |
| 6 | 81 | 308 | 26% | 233 | 709 | 32% |
| 4 | 67 | 284 | 23% | 170 | 469 | 36% |
| 2 | 34 | 153 | 22% | 90 | 240 | 37% |
5.4 结果分析
从测试结果中,我们看到在单机情况下,RBD的性能不如RAID10,这是为什么?我们可以通过三种方法找到原因:
- 阅读Ceph源码,查看I/O路径
- 使用blktrace查看I/O操作的执行
- 使用iostat观察硬盘的读写情况
RBD的I/O路径很长,要经过网络、文件系统、磁盘:
Librbd -> networking -> OSD -> FileSystem -> Disk
Client的每个写操作在OSD中要经过8种线程,写操作下发到OSD之后,会产生2~3个磁盘seek操作:
- 把写操作记录到OSD的Journal文件上(Journal是为了保证写操作的原子性)。
- 把写操作更新到Object对应的文件上。
- 把写操作记录到PG Log文件上。
我使用fio向RBD不断写入数据,然后使用iostat观察磁盘的读写情况。在1分钟之内,fio向RBD写入了3667 MB的数据,24块硬盘则被写入了16084 MB的数据,被读取了288 MB的数据。
向RBD写入1MB数据 = 向硬盘写入4.39MB数据 + 读取0.08MB数据
6. 结论
在单机情况下,RBD的性能不如传统的RAID10,这是因为RBD的I/O路径很复杂,导致效率很低。但是Ceph的优势在于它的扩展性,它的性能会随着磁盘数量线性增长,因此在多机的情况下,RBD的IOPS和吞吐率会高于单机的RAID10(不过性能会受限于网络的带宽)。
如前所述,Ceph优势显著,使用它能够降低硬件成本和运维成本,但它的复杂性会带来一定的学习成本。
Ceph的特点使得它非常适合于云计算,那么OpenStack使用Ceph的效果如何?下期《Ceph与OpenStack》将会介绍Ceph的自动化部署、Ceph与OpenStack的对接。
[1] http://www.ustack.com/blog/ceph-distributed-block-storage/#2_Ceph
[2] http://ceph.com/community/results-from-the-ceph-census/
来源:https://www.ustack.com/blog/ceph_infra/
Ceph对象存储运维惊魂72小时
针对于前段时间的福叔讲存储的Ceph对象存储运维惊魂72小时,社区在这里做了一下总结。希望能够对大家有所帮助
Ceph作为一款开源的分布式存储软件,可以利用X86服务器自身的本地存储资源,创建一个或多个存储资源池,并基于资源池对用户提供统一存储服务,包括块存储、对象存储、文件存储,满足企业对存储高可靠性、高性能、高可扩展性方面的需求,并越来越受到企业的青睐。经过大量的生产实践证明,Ceph的设计理念先进,功能全面,使用灵活,富有弹性。不过,Ceph的这些优点对企业来说也是一把双刃剑,驾驭的好可以很好地服务于企业,倘若功力不够,没有摸清Ceph的脾性,有时也会制造不小的麻烦,下面我要给大家分享的正是这样的一个案例。
A公司通过部署Ceph对象存储集群,对外提供云存储服务,提供SDK帮助客户快速实现对图片、视频、apk安装包等非结构化数据的云化管理。在业务正式上线前,曾经对Ceph做过充分的功能测试、异常测试和性能测试。
集群规模不是很大,使用的是社区0.80版本,总共有30台服务器,每台服务器配置32GB内存,10块4T的SATA盘和1块160G的Intel S3700 SSD盘。300块SATA盘组成一个数据资源池(缺省配置情况下就是名称为.rgw.buckets的pool),存放对象数据;30块SSD盘组成一个元数据资源池(缺省配置情况下就是名称为.rgw.buckets.index的pool),存放对象元数据。有过Ceph对象存储运维部署经验的朋友都知道,这样的配置也算是国际惯例,因为Ceph对象存储支持多租户,多个用户在往同一个bucket(用户的一个逻辑空间)中PUT对象的时候,会向bucket索引对象中写入对象的元数据,由于是共享同一个bucket索引对象,访问时需要对这个索引对象加锁,将bucket索引对象存放到高性能盘SSD组成的资源池中,减少每一次索引对象访问的时间,提升IO性能,提高对象存储的整体并发量。
系统上线后,客户数据开始源源不断地存入到Ceph对象存储集群,在前面的三个月中,一切运行正常。期间也出现过SATA磁盘故障,依靠Ceph自身的故障检测、修复机制轻松搞定,运维的兄弟感觉很轻松。进入到5月份,运维兄弟偶尔抱怨说SSD盘对应的OSD有时会变的很慢,导致业务卡顿,遇到这种情况他们简单有效的办法就是重新启动这个OSD,又能恢复正常。大概这种现象零星发生过几次,运维兄弟询问是不是我们在SSD的使用上有什么不对。我们分析后觉得SSD盘的应用没有什么特别的地方,除了将磁盘调度算法修改成deadline,这个已经修改过了,也就没有太在意这个事情。
5月28日晚上21:30,运维兄弟手机上接到系统告警,少部分文件写入失败,马上登陆系统检查,发现是因为一台服务器上的SSD盘对应的OSD读写缓慢引起的。按照之前的经验,此类情况重启OSD进程后就能恢复正常,毫不犹豫地重新启动该OSD进程,等待系统恢复正常。但是这一次,SSD的OSD进程启动过程非常缓慢,并引发同台服务器上的SATA盘OSD进程卡顿,心跳丢失,一段时间后,又发现其它服务器上开始出现SSD盘OSD进程卡顿缓慢。继续重启其它服务器上SSD盘对应的OSD进程,出现了类似情况,这样反复多次重启SSD盘OSD进程后,起不来的SSD盘OSD进程越来越多。运维兄弟立即将此情况反馈给技术研发部门,要求火速前往支援。
到办公室后,根据运维兄弟的反馈,我们登上服务器,试着启动几个SSD盘对应的OSD进程,反复观察比对进程的启动过程:
1、 用top命令发现这个OSD进程启动后就开始疯狂分配内存,高达20GB甚至有时达到30GB;有时因系统内存耗尽,开始使用swap交换分区;有时即使最后进程被成功拉起,但OSD任然占用高达10GB的内存。
2、 查看OSD的日志,发现进入FileJournal::_open阶段后就停止了日志输出。经过很长时间(30分钟以上)后才输出进入load_pg阶段;进入load_pg阶段后,再次经历漫长的等待,虽然load_pg完成,但进程仍然自杀退出。
3、 在上述漫长启动过程中,用pstack查看进程调用栈信息,FileJournal::_open阶段看到的调用栈是在做OSD日志回放,事务处理中是执行levelDB的记录删除;在load_pg阶段看到的调用栈信息是在利用levelDB的日志修复levelDB文件。
4、 有时候一个SSD盘OSD进程启动成功,运行一段时间后会导致另外的SSD盘OSD进程异常死掉。
从这些现象来看,都是跟levelDB有关系,内存大量分配是不是跟这个有关系呢?进一步查看levelDB相关的代码后发现,在一个事务处理中使用levelDB迭代器,迭代器访问记录过程中会不断分配内存,直到迭代器使用完才会释放全部内存。从这一点上看,如果迭代器访问的记录数非常大,就会在迭代过程中分配大量的内存。根据这一点,我们查看bucket中的对象数,发现有几个bucket中的对象数量达到了2000万、3000万、5000万,而且这几个大的bucket索引对象存储位置刚好就是出现问题的那几个SSD盘OSD。内存大量消耗的原因应该是找到了,这是一个重大突破,此时已是30日21:00,这两天已经有用户开始电话投诉,兄弟们都倍感“鸭梨山大”。已经持续奋战近48小时,兄弟们眼睛都红肿了,必须停下来休息,否则会有兄弟倒在黎明前。31日8:30,兄弟们再次投入战斗。 还有一个问题,就是有些OSD在经历漫长启动过程,最终在load_pg完成后仍然自杀退出。通过走读ceph代码,确认是有些线程因长时间没有被调度(可能是因levelDB的线程长时间占用了CPU导致)而超时自杀所致。在ceph的配置中有一个filestore_op_thread_suicide_timeout参数,通过测试验证,将这个参数设置成一个很大的值,可以避免这种自杀。又看到了一点点曙光,时钟指向12:30。 有些进程起来后,仍然会占用高达10GB的内存,这个问题不解决,即使SSD盘OSD拉起来了,同台服务器上的其它SATA盘OSD运行因内存不足都要受到影响。兄弟们再接再厉啊,这是黎明前的黑暗,一定要挺过去。有人查资料,有人看代码,终于在14:30从ceph资料文档查到一个强制释放内存的命令:ceph tell osd.* heap release,可以在进程启动后执行此命令释放OSD进程占用的过多内存。大家都格外兴奋,立即测试验证,果然有效。 一个SSD盘OSD起来后运行一会导致其它SSD盘OSD进程退出,综合上面的分析定位,这主要是因为发生数据迁移,有数据迁出的OSD,在数据迁出后会删除相关记录信息,触发levelDB删除对象元数据记录,一旦遇到一个超大的bucket索引对象,levelDB使用迭代器遍历对象的元数据记录,就会导致过度内存消耗,从而导致服务器上的OSD进程异常。 根据上述分析,经过近2个小时的反复讨论论证,我们制定了如下应急措施: 1、 给集群设置noout标志,不允许做PG迁移,因为一旦出现PG迁移,有PG迁出的OSD,就会在PG迁出后删除PG中的对象数据,触发levelDB删除对象元数据记录,遇到PG中有一个超大的bucket索引对象就会因迭代器遍历元数据记录而消耗大量内存。 2、 为了能救活SSD对应的OSD,尽快恢复系统,在启动SSD对应的OSD进程时,附加启动参数filestore_op_thread_suicide_timeout,设置一个很大的值。由于故障OSD拉起时,LevelDB的一系列处理会抢占CPU,导致线程调度阻塞,在Ceph中有线程死锁检测机制,超过这个参数配置的时间线程仍然没有被调度,就判定为线程死锁。为了避免因线程死锁导致将进程自杀,需要设置这个参数。 3、 在目前内存有限的情况下,异常的OSD启动会使用swap交换分区,为了加快OSD进程启动,将swap分区调整到SSD盘上。 4、 启动一个定时任务,定时执行命令ceph tell osd.* heap release,强制释放OSD占用的内存。 5、 SSD对应的OSD出现问题的时候,按如下步骤处理: a) 先将该服务器上的所有OSD进程都停掉,以腾出全部内存。 b) 然后启动OSD进程,并携带filestore_op_thread_suicide_timeout参数,给一个很大的值,如72000。 c) 观察OSD的启动过程,一旦load_pgs执行完毕,可以立即手动执行ceph tell osd.N heap release命令,将其占用的内存强制释放。 d) 观察集群状态,当所有PG的状态都恢复正常时,再将其他SATA盘对应的OSD进程启动起来。 按照上述步骤,我们从17:30开始逐个恢复OSD进程,在恢复过程中,那几个超大bucket索引对象在做backfilling的时候需要较长时间,在此期间访问这个bucket的请求都被阻塞,导致应用业务请求出现超时,这也是单bucket存储大量对象带来的负面影响。 5月31日23:00,终于恢复了全部OSD进程,从故障到系统全部成功恢复,我们惊心动魄奋战了72小时,大家相视而笑,兴奋过度,再接再厉,一起讨论制定 彻底解决此问题的方案: 1、 扩大服务器内存到64GB。 2、 对新建bucket,限制存储对象的最大数量。 3、 Ceph 0.94版本经过充分测试后,升级到0.94版本,解决单bucket索引对象过大问题。
4、 优化Ceph对levelDB迭代器的使用,在一个大的事务中,通过分段迭代,一个迭代器在完成一定数量的记录遍历后,记录其当前迭代位置,将其释放,再重新创建一个新的迭代器,从上次迭代的位置开始继续遍历,如此可以控制迭代器的内存使用量。
前事不忘后事之师,汲取经验教训,我们总结如下几点:1、 系统上线前必须经过充分的测试
A公司的系统上线前,虽然对ceph做了充分的功能、性能、异常测试,但却没有大量数据的压力测试,如果之前单bucket灌入了几千万对象测试,也许就能提前发现这个隐患。 2、 运维过程中的每一个异常都要及时引起重视 此案例中,在问题爆发前一段时间,运维部门已经有反馈SSD异常的问题,可惜没有引起我们重视,倘若当时就深入分析,也许可以找到问题根由,提前制定规避措施。 3、 摸清ceph的脾性 任何软件产品都有相应的规格限制,ceph也不例外。如果能提前深入了解ceph架构及其实现原理,了解单bucket过度存放大量对象所带来的负面影响,提前规划,也不会出现本案例中遇到的问题。RGW对配额的支持非常全面,包括用户级别的、bucket级别的,都可以配置单个bucket允许存放的最大对象数量。 4、 时刻跟踪社区最新进展 在Ceph的0.94版本中,已经支持了bucket索引对象的shard功能,一个bucket索引对象可以分成多个shard对象存储,可有效缓解单bucket索引对象过大问题。来源:http://ceph.org.cn/2016/05/08/ceph%E5%AF%B9%E8%B1%A1%E5%AD%98%E5%82%A8%E8%BF%90%E7%BB%B4%E6%83%8A%E9%AD%8272%E5%B0%8F%E6%97%B6/
Ceph性能优化总结(v0.94)
最近一直在忙着搞Ceph存储的优化和测试,看了各种资料,但是好像没有一篇文章把其中的方法论交代清楚,所以呢想在这里进行一下总结,很多内容并不是我原创,只是做一个总结。如果其中有任何的问题,欢迎各位喷我,以便我提高。
优化方法论
做任何事情还是要有个方法论的,“授人以鱼不如授人以渔”的道理吧,方法通了,所有的问题就有了解决的途径。通过对公开资料的分析进行总结,对分布式存储系统的优化离不开以下几点:
1. 硬件层面
- 硬件规划
- SSD选择
- BIOS设置
2. 软件层面
- Linux OS
- Ceph Configurations
- PG Number调整
- CRUSH Map
- 其他因素
硬件优化
1. 硬件规划
- Processor
ceph-osd进程在运行过程中会消耗CPU资源,所以一般会为每一个ceph-osd进程绑定一个CPU核上。当然如果你使用EC方式,可能需要更多的CPU资源。
ceph-mon进程并不十分消耗CPU资源,所以不必为ceph-mon进程预留过多的CPU资源。
ceph-msd也是非常消耗CPU资源的,所以需要提供更多的CPU资源。
- 内存
ceph-mon和ceph-mds需要2G内存,每个ceph-osd进程需要1G内存,当然2G更好。
- 网络规划
万兆网络现在基本上是跑Ceph必备的,网络规划上,也尽量考虑分离cilent和cluster网络。
2. SSD选择
硬件的选择也直接决定了Ceph集群的性能,从成本考虑,一般选择SATA SSD作为Journal, Intel® SSD DC S3500 Series 基本是目前看到的方案中的首选。400G的规格4K随机写可以达到11000 IOPS。如果在预算足够的情况下,推荐使用PCIE SSD,性能会得到进一步提升,但是由于Journal在向数据盘写入数据时Block后续请求,所以Journal的加入并未呈现出想象中的性能提升,但是的确会对Latency有很大的改善。
如何确定你的SSD是否适合作为SSD Journal,可以参考SÉBASTIEN HAN的 Ceph: How to Test if Your SSD Is Suitable as a Journal Device? ,这里面他也列出了常见的SSD的测试结果,从结果来看SATA SSD中,Intel S3500性能表现最好。
3. BIOS设置
- Hyper-Threading(HT)
基本做云平台的,VT和HT打开都是必须的,超线程技术(HT)就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。
- 关闭节能
关闭节能后,对性能还是有所提升的,所以坚决调整成性能型(Performance)。当然也可以在操作系统级别进行调整,详细的调整过程请参考 链接 ,但是不知道是不是由于BIOS已经调整的缘故,所以在CentOS 6.6上并没有发现相关的设置。
for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f $CPUFREQ ] || continue; echo -n performance > $CPUFREQ; done- NUMA
简单来说,NUMA思路就是将内存和CPU分割为多个区域,每个区域叫做NODE,然后将NODE高速互联。 node内cpu与内存访问速度快于访问其他node的内存, NUMA可能会在某些情况下影响ceph-osd 。解决的方案,一种是通过BIOS关闭NUMA,另外一种就是通过cgroup将ceph-osd进程与某一个CPU Core以及同一NODE下的内存进行绑定。但是第二种看起来更麻烦,所以一般部署的时候可以在系统层面关闭NUMA。CentOS系统下,通过修改/etc/grub.conf文件,添加numa=off来关闭NUMA。
kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off软件优化
1. Linux OS
- Kernel pid max
echo 4194303 > /proc/sys/kernel/pid_max- Jumbo frames, 交换机端需要支持该功能,系统网卡设置才有效果
ifconfig eth0 mtu 9000永久设置
echo "MTU=9000" | tee -a /etc/sysconfig/network-script/ifcfg-eth0
/etc/init.d/networking restart- read_ahead, 通过数据预读并且记载到随机访问内存方式提高磁盘读操作,查看默认值
cat /sys/block/sda/queue/read_ahead_kb根据一些Ceph的公开分享,8192是比较理想的值
echo "8192" > /sys/block/sda/queue/read_ahead_kb- swappiness, 主要控制系统对swap的使用,这个参数的调整最先见于UnitedStack公开的文档中,猜测调整的原因主要是使用swap会影响系统的性能。
echo "vm.swappiness = 0" | tee -a /etc/sysctl.conf- I/O Scheduler,关于I/O Scheculder的调整网上已经有很多资料,这里不再赘述,简单说SSD要用noop,SATA/SAS使用deadline。
echo "deadline" > /sys/block/sd[x]/queue/scheduler
echo "noop" > /sys/block/sd[x]/queue/scheduler- cgroup
这方面的文章好像比较少,昨天在和Ceph社区交流过程中,Jan Schermer说准备把生产环境中的一些脚本贡献出来,但是暂时还没有,他同时也列举了一些使用cgroup进行隔离的 原因 。
- 不在process和thread在不同的core上移动(更好的缓存利用)
- 减少NUMA的影响
- 网络和存储控制器影响 - 较小
- 通过限制cpuset来限制Linux调度域(不确定是不是重要但是是最佳实践)
- 如果开启了HT,可能会造成OSD在thread1上,KVM在thread2上,并且是同一个core。Core的延迟和性能取决于其他一个线程做什么。
这一点具体实现待补充!!!
2. Ceph Configurations
[global]
| 参数名 | 描述 | 默认值 | 建议值 |
|---|---|---|---|
| public network | 客户端访问网络 | 192.168.100.0/24 | |
| cluster network | 集群网络 | 192.168.1.0/24 | |
| max open files | 如果设置了该选项,Ceph会设置系统的max open fds | 0 | 131072 |
- 查看系统最大文件打开数可以使用命令
cat /proc/sys/fs/file-max[osd] - filestore
| 参数名 | 描述 | 默认值 | 建议值 |
|---|---|---|---|
| filestore xattr use omap | 为XATTRS使用object map,EXT4文件系统时使用,XFS或者btrfs也可以使用 | false | true |
| filestore max sync interval | 从日志到数据盘最大同步间隔(seconds) | 5 | 15 |
| filestore min sync interval | 从日志到数据盘最小同步间隔(seconds) | 0.1 | 10 |
| filestore queue max ops | 数据盘最大接受的操作数 | 500 | 25000 |
| filestore queue max bytes | 数据盘一次操作最大字节数(bytes) | 100 << 20 | 10485760 |
| filestore queue committing max ops | 数据盘能够commit的操作数 | 500 | 5000 |
| filestore queue committing max bytes | 数据盘能够commit的最大字节数(bytes) | 100 << 20 | 10485760000 |
| filestore op threads | 并发文件系统操作数 | 2 | 32 |
- 调整omap的原因主要是EXT4文件系统默认仅有4K
- filestore queue相关的参数对于性能影响很小,参数调整不会对性能优化有本质上提升
[osd] - journal
| 参数名 | 描述 | 默认值 | 建议值 |
|---|---|---|---|
| osd journal size | OSD日志大小(MB) | 5120 | 20000 |
| journal max write bytes | journal一次性写入的最大字节数(bytes) | 10 << 20 | 1073714824 |
| journal max write entries | journal一次性写入的最大记录数 | 100 | 10000 |
| journal queue max ops | journal一次性最大在队列中的操作数 | 500 | 50000 |
| journal queue max bytes | journal一次性最大在队列中的字节数(bytes) | 10 << 20 | 10485760000 |
- Ceph OSD Daemon stops writes and synchronizes the journal with the filesystem, allowing Ceph OSD Daemons to trim operations from the journal and reuse the space.
- 上面这段话的意思就是,Ceph OSD进程在往数据盘上刷数据的过程中,是停止写操作的。
[osd] - osd config tuning
| 参数名 | 描述 | 默认值 | 建议值 |
|---|---|---|---|
| osd max write size | OSD一次可写入的最大值(MB) | 90 | 512 |
| osd client message size cap | 客户端允许在内存中的最大数据(bytes) | 524288000 | 2147483648 |
| osd deep scrub stride | 在Deep Scrub时候允许读取的字节数(bytes) | 524288 | 131072 |
| osd op threads | OSD进程操作的线程数 | 2 | 8 |
| osd disk threads | OSD密集型操作例如恢复和Scrubbing时的线程 | 1 | 4 |
| osd map cache size | 保留OSD Map的缓存(MB) | 500 | 1024 |
| osd map cache bl size | OSD进程在内存中的OSD Map缓存(MB) | 50 | 128 |
| osd mount options xfs | Ceph OSD xfs Mount选项 | rw,noatime,inode64 | rw,noexec,nodev,noatime,nodiratime,nobarrier |
- 增加osd op threads和disk threads会带来额外的CPU开销
[osd] - recovery tuning
| 参数名 | 描述 | 默认值 | 建议值 |
|---|---|---|---|
| osd recovery op priority | 恢复操作优先级,取值1-63,值越高占用资源越高 | 10 | 4 |
| osd recovery max active | 同一时间内活跃的恢复请求数 | 15 | 10 |
| osd max backfills | 一个OSD允许的最大backfills数 | 10 | 4 |
[osd] - client tuning
| 参数名 | 描述 | 默认值 | 建议值 |
|---|---|---|---|
| rbd cache | RBD缓存 | true | true |
| rbd cache size | RBD缓存大小(bytes) | 33554432 | 268435456 |
| rbd cache max dirty | 缓存为write-back时允许的最大dirty字节数(bytes),如果为0,使用write-through | 25165824 | 134217728 |
| rbd cache max dirty age | 在被刷新到存储盘前dirty数据存在缓存的时间(seconds) | 1 | 5 |
关闭Debug
3. PG Number
PG和PGP数量一定要根据OSD的数量进行调整,计算公式如下,但是最后算出的结果一定要接近或者等于一个2的指数。
Total PGs = (Total_number_of_OSD * 100) / max_replication_count
例如15个OSD,副本数为3的情况下,根据公式计算的结果应该为500,最接近512,所以需要设定该pool(volumes)的pg_num和pgp_num都为512.
ceph osd pool set volumes pg_num 512
ceph osd pool set volumes pgp_num 5124. CRUSH Map
CRUSH是一个非常灵活的方式,CRUSH MAP的调整取决于部署的具体环境,这个可能需要根据具体情况进行分析,这里面就不再赘述了。
5. 其他因素的影响
在今年的(2015年)的Ceph Day上,海云捷迅在调优过程中分享过一个由于在集群中存在一个性能不好的磁盘,导致整个集群性能下降的case。通过osd perf可以提供磁盘latency的状况,同时在运维过程中也可以作为监控的一个重要指标,很明显在下面的例子中,OSD 8的磁盘延时较长,所以需要考虑将该OSD剔除出集群:
ceph osd perfosd fs_commit_latency(ms) fs_apply_latency(ms)
0 14 17
1 14 16
2 10 11
3 4 5
4 13 15
5 17 20
6 15 18
7 14 16
8 299 329
ceph.conf
[global]
fsid = 059f27e8-a23f-4587-9033-3e3679d03b31
mon_host = 10.10.20.102, 10.10.20.101, 10.10.20.100
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd pool default size = 3
osd pool default min size = 1
public network = 10.10.20.0/24
cluster network = 10.10.20.0/24
max open files = 131072
[mon]
mon data = /var/lib/ceph/mon/ceph-$id
[osd]
osd data = /var/lib/ceph/osd/ceph-$id
osd journal size = 20000
osd mkfs type = xfs
osd mkfs options xfs = -f
filestore xattr use omap = true
filestore min sync interval = 10
filestore max sync interval = 15
filestore queue max ops = 25000
filestore queue max bytes = 10485760
filestore queue committing max ops = 5000
filestore queue committing max bytes = 10485760000
journal max write bytes = 1073714824
journal max write entries = 10000
journal queue max ops = 50000
journal queue max bytes = 10485760000
osd max write size = 512
osd client message size cap = 2147483648
osd deep scrub stride = 131072
osd op threads = 8
osd disk threads = 4
osd map cache size = 1024
osd map cache bl size = 128
osd mount options xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier"
osd recovery op priority = 4
osd recovery max active = 10
osd max backfills = 4
[client]
rbd cache = true
rbd cache size = 268435456
rbd cache max dirty = 134217728
rbd cache max dirty age = 5总结
优化是一个长期迭代的过程,所有的方法都是别人的,只有在实践过程中才能发现自己的,本篇文章仅仅是一个开始,欢迎各位积极补充,共同完成一篇具有指导性的文章。
来源:http://www.tuicool.com/articles/jaam6f7
ceph运维常用指令
集群
启动一个ceph 进程
启动mon进程
service ceph start mon.node1
启动msd进程
service ceph start mds.node1
启动osd进程
service ceph start osd.0
查看机器的监控状态
[root@client ~]# ceph health
HEALTH_OK
查看ceph的实时运行状态
[root@client ~]# ceph -w
cluster be1756f2-54f7-4d8f-8790-820c82721f17
health HEALTH_OK
monmap e2: 3 mons at {node1=10.240.240.211:6789/0,node2=10.240.240.212:6789/0,node3=10.240.240.213:6789/0}, election epoch 294, quorum 0,1,2 node1,node2,node3
mdsmap e95: 1/1/1 up {0=node2=up:active}, 1 up:standby
osdmap e88: 3 osds: 3 up, 3 in
pgmap v1164: 448 pgs, 4 pools, 10003 MB data, 2520 objects
23617 MB used, 37792 MB / 61410 MB avail
448 active+clean
2014-06-30 00:48:28.756948 mon.0 [INF] pgmap v1163: 448 pgs: 448 active+clean; 10003 MB data, 23617 MB used, 37792 MB / 61410 MB avail
检查信息状态信息
[root@client ~]# ceph -s
cluster be1756f2-54f7-4d8f-8790-820c82721f17
health HEALTH_OK
monmap e2: 3 mons at {node1=10.240.240.211:6789/0,node2=10.240.240.212:6789/0,node3=10.240.240.213:6789/0}, election epoch 294, quorum 0,1,2 node1,node2,node3
mdsmap e95: 1/1/1 up {0=node2=up:active}, 1 up:standby
osdmap e88: 3 osds: 3 up, 3 in
pgmap v1164: 448 pgs, 4 pools, 10003 MB data, 2520 objects
23617 MB used, 37792 MB / 61410 MB avail
448 active+clean
[root@client ~]#
查看ceph存储空间
[root@client ~]# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
61410M 37792M 23617M 38.46
POOLS:
NAME ID USED %USED OBJECTS
data 0 10000M 16.28 2500
metadata 1 3354k 0 20
rbd 2 0 0 0
jiayuan 3 0 0 0
[root@client ~]#
删除一个节点的所有的ceph数据包
[root@node1 ~]# ceph-deploy purge node1
[root@node1 ~]# ceph-deploy purgedata node1
为ceph创建一个admin用户并为admin用户创建一个密钥,把密钥保存到/etc/ceph目录下:
# ceph auth get-or-create client.admin mds ‘allow’ osd ‘allow ’ mon ‘allow ’ > /etc/ceph/ceph.client.admin.keyring
或
# ceph auth get-or-create client.admin mds ‘allow’ osd ‘allow ’ mon ‘allow ’ -o /etc/ceph/ceph.client.admin.keyring
为osd.0创建一个用户并创建一个key
# ceph auth get-or-create osd.0 mon ‘allow rwx’ osd ‘allow *’ -o /var/lib/ceph/osd/ceph-0/keyring
为mds.node1创建一个用户并创建一个key
# ceph auth get-or-create mds.node1 mon ‘allow rwx’ osd ‘allow ’ mds ‘allow ’ -o /var/lib/ceph/mds/ceph-node1/keyring
查看ceph集群中的认证用户及相关的key
ceph auth list
删除集群中的一个认证用户
ceph auth del osd.0
查看集群的详细配置
[root@node1 ~]# ceph daemon mon.node1 config show | more
查看集群健康状态细节
[root@admin ~]# ceph health detail
HEALTH_WARN 12 pgs down; 12 pgs peering; 12 pgs stuck inactive; 12 pgs stuck unclean
pg 3.3b is stuck inactive since forever, current state down+peering, last acting [1,2]
pg 3.36 is stuck inactive since forever, current state down+peering, last acting [1,2]
pg 3.79 is stuck inactive since forever, current state down+peering, last acting [1,0]
pg 3.5 is stuck inactive since forever, current state down+peering, last acting [1,2]
pg 3.30 is stuck inactive since forever, current state down+peering, last acting [1,2]
pg 3.1a is stuck inactive since forever, current state down+peering, last acting [1,0]
pg 3.2d is stuck inactive since forever, current state down+peering, last acting [1,0]
pg 3.16 is stuck inactive since forever, current state down+peering, last acting [1,2]
查看ceph log日志所在的目录
[root@node1 ~]# ceph-conf –name mon.node1 –show-config-value log_file
/var/log/ceph/ceph-mon.node1.log
mon
查看mon的状态信息
[root@client ~]# ceph mon stat
e2: 3 mons at {node1=10.240.240.211:6789/0,node2=10.240.240.212:6789/0,node3=10.240.240.213:6789/0}, election epoch 294, quorum 0,1,2 node1,node2,node3
查看mon的选举状态
[root@client ~]# ceph quorum_status
{“election_epoch”:294,”quorum”:[0,1,2],”quorum_names”:[“node1”,”node2”,”node3”],”quorum_leader_name”:”node1”,”monmap”:{“epoch”:2,”fsid”:”be1756f2-54f7-4d8f-8790-820c82721f17”,”modified”:”2014-06-26 18:43:51.671106”,”created”:”0.000000”,”mons”:[{“rank”:0,”name”:”node1”,”addr”:”10.240.240.211:6789\/0”},{“rank”:1,”name”:”node2”,”addr”:”10.240.240.212:6789\/0”},{“rank”:2,”name”:”node3”,”addr”:”10.240.240.213:6789\/0”}]}}
查看mon的映射信息
[root@client ~]# ceph mon dump
dumped monmap epoch 2
epoch 2
fsid be1756f2-54f7-4d8f-8790-820c82721f17
last_changed 2014-06-26 18:43:51.671106
created 0.000000
0: 10.240.240.211:6789/0 mon.node1
1: 10.240.240.212:6789/0 mon.node2
2: 10.240.240.213:6789/0 mon.node3
删除一个mon节点
[root@node1 ~]# ceph mon remove node1
removed mon.node1 at 10.39.101.1:6789/0, there are now 3 monitors
2014-07-07 18:11:04.974188 7f4d16bfd700 0 monclient: hunting for new mon
获得一个正在运行的mon map,并保存在1.txt文件中
[root@node3 ~]# ceph mon getmap -o 1.txt
got monmap epoch 6
查看上面获得的map
[root@node3 ~]# monmaptool –print 1.txt
monmaptool: monmap file 1.txt
epoch 6
fsid 92552333-a0a8-41b8-8b45-c93a8730525e
last_changed 2014-07-07 18:22:51.927205
created 0.000000
0: 10.39.101.1:6789/0 mon.node1
1: 10.39.101.2:6789/0 mon.node2
2: 10.39.101.3:6789/0 mon.node3
[root@node3 ~]#
把上面的mon map注入新加入的节点
ceph-mon -i node4 –inject-monmap 1.txt
查看mon的amin socket
root@node1 ~]# ceph-conf –name mon.node1 –show-config-value admin_socket
/var/run/ceph/ceph-mon.node1.asok
查看mon的详细状态
[root@node1 ~]# ceph daemon mon.node1 mon_status
{ “name”: “node1”,
“rank”: 0,
“state”: “leader”,
“election_epoch”: 96,
“quorum”: [
0,
1,
2],
“outside_quorum”: [],
“extra_probe_peers”: [
“10.39.101.4:6789\/0”],
“sync_provider”: [],
“monmap”: { “epoch”: 6,
“fsid”: “92552333-a0a8-41b8-8b45-c93a8730525e”,
“modified”: “2014-07-07 18:22:51.927205”,
“created”: “0.000000”,
“mons”: [
{ “rank”: 0,
“name”: “node1”,
“addr”: “10.39.101.1:6789\/0”},
{ “rank”: 1,
“name”: “node2”,
“addr”: “10.39.101.2:6789\/0”},
{ “rank”: 2,
“name”: “node3”,
“addr”: “10.39.101.3:6789\/0”}]}
删除一个mon节点
[root@os-node1 ~]# ceph mon remove os-node1
removed mon.os-node1 at 10.40.10.64:6789/0, there are now 3 monitors
msd
查看msd状态
[root@client ~]# ceph mds stat
e95: 1/1/1 up {0=node2=up:active}, 1 up:standby
查看msd的映射信息
[root@client ~]# ceph mds dump
dumped mdsmap epoch 95
epoch 95
flags 0
created 2014-06-26 18:41:57.686801
modified 2014-06-30 00:24:11.749967
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
last_failure 84
last_failure_osd_epoch 81
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap}
max_mds 1
in 0
up {0=5015}
failed
stopped
data_pools 0
metadata_pool 1
inline_data disabled
5015: 10.240.240.212:6808/3032 ‘node2’ mds.0.12 up:active seq 30
5012: 10.240.240.211:6807/3459 ‘node1’ mds.-1.0 up:standby seq 38
删除一个mds节点
[root@node1 ~]# ceph mds rm 0 mds.node1
mds gid 0 dne
osd
查看ceph osd运行状态
[root@client ~]# ceph osd stat
osdmap e88: 3 osds: 3 up, 3 in
查看osd映射信息
[root@client ~]# ceph osd dump
epoch 88
fsid be1756f2-54f7-4d8f-8790-820c82721f17
created 2014-06-26 18:41:57.687442
modified 2014-06-30 00:46:27.179793
flags
pool 0 ‘data’ replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1 owner 0 flags hashpspool crash_replay_interval 45 stripe_width 0
pool 1 ‘metadata’ replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1 owner 0 flags hashpspool stripe_width 0
pool 2 ‘rbd’ replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1 owner 0 flags hashpspool stripe_width 0
pool 3 ‘jiayuan’ replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 256 pgp_num 256 last_change 73 owner 0 flags hashpspool stripe_width 0
max_osd 3
osd.0 up in weight 1 up_from 65 up_thru 75 down_at 64 last_clean_interval [53,55) 10.240.240.211:6800/3089 10.240.240.211:6801/3089 10.240.240.211:6802/3089 10.240.240.211:6803/3089 exists,up 8a24ad16-a483-4bac-a56a-6ed44ab74ff0
osd.1 up in weight 1 up_from 59 up_thru 74 down_at 58 last_clean_interval [31,55) 10.240.240.212:6800/2696 10.240.240.212:6801/2696 10.240.240.212:6802/2696 10.240.240.212:6803/2696 exists,up 8619c083-0273-4203-ba57-4b1dabb89339
osd.2 up in weight 1 up_from 62 up_thru 74 down_at 61 last_clean_interval [39,55) 10.240.240.213:6800/2662 10.240.240.213:6801/2662 10.240.240.213:6802/2662 10.240.240.213:6803/2662 exists,up f8107c04-35d7-4fb8-8c82-09eb885f0e58
[root@client ~]#
查看osd的目录树
[root@client ~]# ceph osd tree
# id weight type name up/down reweight
-1 3 root default
-2 1 host node1
0 1 osd.0 up 1
-3 1 host node2
1 1 osd.1 up 1
-4 1 host node3
2 1 osd.2 up 1
down掉一个osd硬盘
[root@node1 ~]# ceph osd down 0 #down掉osd.0节点
在集群中删除一个osd硬盘
[root@node4 ~]# ceph osd rm 0
removed osd.0
在集群中删除一个osd 硬盘 crush map
[root@node1 ~]# ceph osd crush rm osd.0
在集群中删除一个osd的host节点
[root@node1 ~]# ceph osd crush rm node1
removed item id -2 name ‘node1’ from crush map
查看最大osd的个数
[root@node1 ~]# ceph osd getmaxosd
max_osd = 4 in epoch 514 #默认最大是4个osd节点
设置最大的osd的个数(当扩大osd节点的时候必须扩大这个值)
[root@node1 ~]# ceph osd setmaxosd 10
设置osd crush的权重为1.0
ceph osd crush set {id} {weight} [{loc1} [{loc2} …]]
例如:
[root@admin ~]# ceph osd crush set 3 3.0 host=node4
set item id 3 name ‘osd.3’ weight 3 at location {host=node4} to crush map
[root@admin ~]# ceph osd tree
# id weight type name up/down reweight
-1 6 root default
-2 1 host node1
0 1 osd.0 up 1
-3 1 host node2
1 1 osd.1 up 1
-4 1 host node3
2 1 osd.2 up 1
-5 3 host node4
3 3 osd.3 up 0.5
或者用下面的方式
[root@admin ~]# ceph osd crush reweight osd.3 1.0
reweighted item id 3 name ‘osd.3’ to 1 in crush map
[root@admin ~]# ceph osd tree
# id weight type name up/down reweight
-1 4 root default
-2 1 host node1
0 1 osd.0 up 1
-3 1 host node2
1 1 osd.1 up 1
-4 1 host node3
2 1 osd.2 up 1
-5 1 host node4
3 1 osd.3 up 0.5
设置osd的权重
[root@admin ~]# ceph osd reweight 3 0.5
reweighted osd.3 to 0.5 (8327682)
[root@admin ~]# ceph osd tree
# id weight type name up/down reweight
-1 4 root default
-2 1 host node1
0 1 osd.0 up 1
-3 1 host node2
1 1 osd.1 up 1
-4 1 host node3
2 1 osd.2 up 1
-5 1 host node4
3 1 osd.3 up 0.5
把一个osd节点逐出集群
[root@admin ~]# ceph osd out osd.3
marked out osd.3.
[root@admin ~]# ceph osd tree
# id weight type name up/down reweight
-1 4 root default
-2 1 host node1
0 1 osd.0 up 1
-3 1 host node2
1 1 osd.1 up 1
-4 1 host node3
2 1 osd.2 up 1
-5 1 host node4
3 1 osd.3 up 0 # osd.3的reweight变为0了就不再分配数据,但是设备还是存活的
把逐出的osd加入集群
[root@admin ~]# ceph osd in osd.3
marked in osd.3.
[root@admin ~]# ceph osd tree
# id weight type name up/down reweight
-1 4 root default
-2 1 host node1
0 1 osd.0 up 1
-3 1 host node2
1 1 osd.1 up 1
-4 1 host node3
2 1 osd.2 up 1
-5 1 host node4
3 1 osd.3 up 1
暂停osd (暂停后整个集群不再接收数据)
[root@admin ~]# ceph osd pause
set pauserd,pausewr
再次开启osd (开启后再次接收数据)
[root@admin ~]# ceph osd unpause
unset pauserd,pausewr
查看一个集群osd.2参数的配置
ceph –admin-daemon /var/run/ceph/ceph-osd.2.asok config show | less
PG组
查看pg组的映射信息
[root@client ~]# ceph pg dump
dumped all in format plain
version 1164
stamp 2014-06-30 00:48:29.754714
last_osdmap_epoch 88
last_pg_scan 73
full_ratio 0.95
nearfull_ratio 0.85
pg_stat objects mip degr unf bytes log disklog state state_stamp v reported up up_primary acting acting_primary last_scrub scrub_stamp last_deep_scrudeep_scrub_stamp
0.3f 39 0 0 0 163577856 128 128 active+clean 2014-06-30 00:30:59.193479 52’128 88:242 [0,2] 0 [0,2] 0 44’25 2014-06-29 22:25:25.282347 0’0 2014-06-26 19:52:08.521434
3.3c 0 0 0 0 0 0 0 active+clean 2014-06-30 00:15:38.675465 0’0 88:21 [2,1] 2 [2,1] 2 0’0 2014-06-30 00:15:04.295637 0’0 2014-06-30 00:15:04.295637
2.3c 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:48.583702 0’0 88:46 [2,1] 2 [2,1] 2 0’0 2014-06-29 22:29:13.701625 0’0 2014-06-26 19:52:08.845944
1.3f 2 0 0 0 452 2 2 active+clean 2014-06-30 00:10:48.596050 16’2 88:66 [2,1] 2 [2,1] 2 16’2 2014-06-29 22:28:03.570074 0’0 2014-06-26 19:52:08.655292
0.3e 31 0 0 0 130023424 130 130 active+clean 2014-06-30 00:26:22.803186 52’130 88:304 [2,0] 2 [2,0] 2 44’59 2014-06-29 22:26:41.317403 0’0 2014-06-26 19:52:08.518978
3.3d 0 0 0 0 0 0 0 active+clean 2014-06-30 00:16:57.548803 0’0 88:20 [0,2] 0 [0,2] 0 0’0 2014-06-30 00:15:19.101314 0’0 2014-06-30 00:15:19.101314
2.3f 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:58.750476 0’0 88:106 [0,2] 0 [0,2] 0 0’0 2014-06-29 22:27:44.604084 0’0 2014-06-26 19:52:08.864240
1.3c 1 0 0 0 0 1 1 active+clean 2014-06-30 00:10:48.939358 16’1 88:66 [1,2] 1 [1,2] 1 16’1 2014-06-29 22:27:35.991845 0’0 2014-06-26 19:52:08.646470
0.3d 34 0 0 0 142606336 149 149 active+clean 2014-06-30 00:23:57.348657 52’149 88:300 [0,2] 0 [0,2] 0 44’57 2014-06-29 22:25:24.279912 0’0 2014-06-26 19:52:08.514526
3.3e 0 0 0 0 0 0 0 active+clean 2014-06-30 00:15:39.554742 0’0 88:21 [2,1] 2 [2,1] 2 0’0 2014-06-30 00:15:04.296812 0’0 2014-06-30 00:15:04.296812
2.3e 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:48.592171 0’0 88:46 [2,1] 2 [2,1] 2 0’0 2014-06-29 22:29:14.702209 0’0 2014-06-26 19:52:08.855382
1.3d 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:48.938971 0’0 88:58 [1,2] 1 [1,2] 1 0’0 2014-06-29 22:27:36.971820 0’0 2014-06-26 19:52:08.650070
0.3c 41 0 0 0 171966464 157 157 active+clean 2014-06-30 00:24:55.751252 52’157 88:385 [1,0] 1 [1,0] 1 44’41 2014-06-29 22:26:34.829858 0’0 2014-06-26 19:52:08.513798
3.3f 0 0 0 0 0 0 0 active+clean 2014-06-30 00:17:08.416756 0’0 88:20 [0,1] 0 [0,1] 0 0’0 2014-06-30 00:15:19.406120 0’0 2014-06-30 00:15:19.406120
2.39 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:58.784789 0’0 88:71 [2,0] 2 [2,0] 2 0’0 2014-06-29 22:29:10.673549 0’0 2014-06-26 19:52:08.834644
1.3a 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:58.738782 0’0 88:106 [0,2] 0 [0,2] 0 0’0 2014-06-29 22:26:29.457318 0’0 2014-06-26 19:52:08.642018
0.3b 37 0 0 0 155189248 137 137 active+clean 2014-06-30 00:28:45.021993 52’137 88:278 [0,2] 0 [0,2] 0 44’40 2014-06-29 22:25:22.275783 0’0 2014-06-26 19:52:08.510502
3.38 0 0 0 0 0 0 0 active+clean 2014-06-30 00:16:13.222339 0’0 88:21 [1,0] 1 [1,0] 1 0’0 2014-06-30 00:15:05.446639 0’0 2014-06-30 00:15:05.446639
2.38 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:58.783103 0’0 88:71 [2,0] 2 [2,0] 2 0’0 2014-06-29 22:29:06.688363 0’0 2014-06-26 19:52:08.827342
1.3b 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:58.857283 0’0 88:78 [1,0] 1 [1,0] 1 0’0 2014-06-29 22:27:30.017050 0’0 2014-06-26 19:52:08.644820
0.3a 40 0 0 0 167772160 149 149 active+clean 2014-06-30 00:28:47.002342 52’149 88:288 [0,2] 0 [0,2] 0 44’46 2014-06-29 22:25:21.273679 0’0 2014-06-26 19:52:08.508654
3.39 0 0 0 0 0 0 0 active+clean 2014-06-30 00:16:13.255056 0’0 88:21 [1,0] 1 [1,0] 1 0’0 2014-06-30 00:15:05.447461 0’0 2014-06-30 00:15:05.447461
2.3b 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:48.935872 0’0 88:57 [1,2] 1 [1,2] 1 0’0 2014-06-29 22:28:35.095977 0’0 2014-06-26 19:52:08.844571
1.38 0 0 0 0 0 0 0 active+clean 2014-06-30 00:10:48.597540 0’0 88:46 [2,1] 2 [2,1] 2 0’0 2014-06-29 22:28:01.519137 0’0 2014-06-26 19:52:08.633781
0.39 48 0 0 0 201326592 164 164 active+clean 2014-06-30 00:25:30.757843 52’164 88:432 [1,0] 1 [1,0] 1 44’32 2014-06-29 22:26:33.823947 0’0 2014-06-26 19:52:08.504628
下面部分省略
查看一个PG的map
[root@client ~]# ceph pg map 0.3f
osdmap e88 pg 0.3f (0.3f) -> up [0,2] acting [0,2] #其中的[0,2]代表存储在osd.0、osd.2节点,osd.0代表主副本的存储位置
查看PG状态
[root@client ~]# ceph pg stat
v1164: 448 pgs: 448 active+clean; 10003 MB data, 23617 MB used, 37792 MB / 61410 MB avail
查询一个pg的详细信息
[root@client ~]# ceph pg 0.26 query
查看pg中stuck的状态
[root@client ~]# ceph pg dump_stuck unclean
ok
[root@client ~]# ceph pg dump_stuck inactive
ok
[root@client ~]# ceph pg dump_stuck stale
ok
显示一个集群中的所有的pg统计
ceph pg dump –format plain
恢复一个丢失的pg
ceph pg {pg-id} mark_unfound_lost revert
显示非正常状态的pg
ceph pg dump_stuck inactive|unclean|stale
pool
查看ceph集群中的pool数量
[root@admin ~]# ceph osd lspools
0 data,1 metadata,2 rbd,
在ceph集群中创建一个pool
ceph osd pool create jiayuan 100 #这里的100指的是PG组
为一个ceph pool配置配额
ceph osd pool set-quota data max_objects 10000
在集群中删除一个pool
ceph osd pool delete jiayuan jiayuan –yes-i-really-really-mean-it #集群名字需要重复两次
显示集群中pool的详细信息
[root@admin ~]# rados df
pool name category KB objects clones degraded unfound rd rd KB wr wr KB
data - 475764704 116155 0 0 0 0 0 116379 475764704
metadata - 5606 21 0 0 0 0 0 314 5833
rbd - 0 0 0 0 0 0 0 0 0
total used 955852448 116176
total avail 639497596
total space 1595350044
[root@admin ~]#
给一个pool创建一个快照
[root@admin ~]# ceph osd pool mksnap data date-snap
created pool data snap date-snap
删除pool的快照
[root@admin ~]# ceph osd pool rmsnap data date-snap
removed pool data snap date-snap
查看data池的pg数量
[root@admin ~]# ceph osd pool get data pg_num
pg_num: 64
设置data池的最大存储空间为100T(默认是1T)
[root@admin ~]# ceph osd pool set data target_max_bytes 100000000000000
set pool 0 target_max_bytes to 100000000000000
设置data池的副本数是3
[root@admin ~]# ceph osd pool set data size 3
set pool 0 size to 3
设置data池能接受写操作的最小副本为2
[root@admin ~]# ceph osd pool set data min_size 2
set pool 0 min_size to 2
查看集群中所有pool的副本尺寸
[root@admin mycephfs]# ceph osd dump | grep ‘replicated size’
pool 0 ‘data’ replicated size 3 min_size 2 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 26 owner 0 flags hashpspool crash_replay_interval 45 target_bytes 100000000000000 stripe_width 0
pool 1 ‘metadata’ replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1 owner 0 flags hashpspool stripe_width 0
pool 2 ‘rbd’ replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1 owner 0 flags hashpspool stripe_width 0
设置一个pool的pg数量
[root@admin ~]# ceph osd pool set data pg_num 100
set pool 0 pg_num to 100
设置一个pool的pgp数量
[root@admin ~]# ceph osd pool set data pgp_num 100
set pool 0 pgp_num to 100
rados指令
查看ceph集群中有多少个pool (只是查看pool)
[root@node-44 ~]# rados lspools
data
metadata
rbd
images
volumes
.rgw.root
compute
.rgw.control
.rgw
.rgw.gc
.users.uid
查看ceph集群中有多少个pool,并且每个pool容量及利用情况
[root@node-44 ~]# rados df
pool name category KB objects clones degraded unfound rd rd KB wr wr KB
.rgw - 0 0 0 0 0 0 0 0 0
.rgw.control - 0 8 0 0 0 0 0 0 0
.rgw.gc - 0 32 0 0 0 57172 57172 38136 0
.rgw.root - 1 4 0 0 0 75 46 10 10
.users.uid - 1 1 0 0 0 0 0 2 1
compute - 67430708 16506 0 0 0 398128 75927848 1174683 222082706
data - 0 0 0 0 0 0 0 0 0
images - 250069744 30683 0 0 0 50881 195328724 65025 388375482
metadata - 0 0 0 0 0 0 0 0 0
rbd - 0 0 0 0 0 0 0 0 0
volumes - 79123929 19707 0 0 0 2575693 63437000 1592456 163812172
total used 799318844 66941
total avail 11306053720
total space 12105372564
[root@node-44 ~]#
创建一个pool
[root@node-44 ~]#rados mkpool test
查看ceph pool中的ceph object (这里的object是以块形式存储的)
[root@node-44 ~]# rados ls -p volumes | more
rbd_data.348f21ba7021.0000000000000866
rbd_data.32562ae8944a.0000000000000c79
rbd_data.589c2ae8944a.00000000000031ba
rbd_data.58c9151ff76b.00000000000029af
rbd_data.58c9151ff76b.0000000000002c19
rbd_data.58c9151ff76b.0000000000000a5a
rbd_data.58c9151ff76b.0000000000001c69
rbd_data.58c9151ff76b.000000000000281d
rbd_data.58c9151ff76b.0000000000002de1
rbd_data.58c9151ff76b.0000000000002dae
创建一个对象object
[root@admin-node ~]# rados create test-object -p test
[root@admin-node ~]# rados -p test ls
test-object
删除一个对象
[root@admin-node ~]# rados rm test-object-1 -p test
rbd命令的用法
查看ceph中一个pool里的所有镜像
[root@node-44 ~]# rbd ls images
2014-05-24 17:17:37.043659 7f14caa6e700 0 – :/1025604 >> 10.49.101.9:6789/0 pipe(0x6c5400 sd=3 :0 s=1 pgs=0 cs=0 l=1 c=0x6c5660).fault
2182d9ac-52f4-4f5d-99a1-ab3ceacbf0b9
34e1a475-5b11-410c-b4c4-69b5f780f03c
476a9f3b-4608-4ffd-90ea-8750e804f46e
60eae8bf-dd23-40c5-ba02-266d5b942767
72e16e93-1fa5-4e11-8497-15bd904eeffe
74cb427c-cee9-47d0-b467-af217a67e60a
8f181a53-520b-4e22-af7c-de59e8ccca78
9867a580-22fe-4ed0-a1a8-120b8e8d18f4
ac6f4dae-4b81-476d-9e83-ad92ff25fb13
d20206d7-ff31-4dce-b59a-a622b0ea3af6
[root@node-44 ~]# rbd ls volumes
2014-05-24 17:22:18.649929 7f9e98733700 0 – :/1010725 >> 10.49.101.9:6789/0 pipe(0x96a400 sd=3 :0 s=1 pgs=0 cs=0 l=1 c=0x96a660).fault
volume-0788fc6c-0dd4-4339-bad4-e9d78bd5365c
volume-0898c5b4-4072-4cae-affc-ec59c2375c51
volume-2a1fb287-5666-4095-8f0b-6481695824e2
volume-35c6aad4-8ea4-4b8d-95c7-7c3a8e8758c5
volume-814494cc-5ae6-4094-9d06-d844fdf485c4
volume-8a6fb0db-35a9-4b3b-9ace-fb647c2918ea
volume-8c108991-9b03-4308-b979-51378bba2ed1
volume-8cf3d206-2cce-4579-91c5-77bcb4a8a3f8
volume-91fc075c-8bd1-41dc-b5ef-844f23df177d
volume-b1263d8b-0a12-4b51-84e5-74434c0e73aa
volume-b84fad5d-16ee-4343-8630-88f265409feb
volume-c03a2eb1-06a3-4d79-98e5-7c62210751c3
volume-c17bf6c0-80ba-47d9-862d-1b9e9a48231e
volume-c32bca55-7ec0-47ce-a87e-a883da4b4ccd
volume-df8961ef-11d6-4dae-96ee-f2df8eb4a08c
volume-f1c38695-81f8-44fd-9af0-458cddf103a3
查看ceph pool中一个镜像的信息
[root@node-44 ~]# rbd info -p images –image 74cb427c-cee9-47d0-b467-af217a67e60a
rbd image ‘74cb427c-cee9-47d0-b467-af217a67e60a’:
size 1048 MB in 131 objects
order 23 (8192 KB objects)
block_name_prefix: rbd_data.95c7783fc0d0
format: 2
features: layering
在test池中创建一个命名为zhanguo的10000M的镜像
[root@node-44 ~]# rbd create -p test –size 10000 zhanguo
[root@node-44 ~]# rbd -p test info zhanguo #查看新建的镜像的信息
rbd image ‘zhanguo’:
size 10000 MB in 2500 objects
order 22 (4096 KB objects)
block_name_prefix: rb.0.127d2.2ae8944a
format: 1
[root@node-44 ~]#
删除一个镜像
[root@node-44 ~]# rbd rm -p test lizhanguo
Removing image: 100% complete…done.
调整一个镜像的尺寸
[root@node-44 ~]# rbd resize -p test –size 20000 zhanguo
Resizing image: 100% complete…done.
[root@node-44 ~]# rbd -p test info zhanguo #调整后的镜像大小
rbd image ‘zhanguo’:
size 20000 MB in 5000 objects
order 22 (4096 KB objects)
block_name_prefix: rb.0.127d2.2ae8944a
format: 1
[root@node-44 ~]#
给一个镜像创建一个快照
[root@node-44 ~]# rbd snap create test/zhanguo@zhanguo123 #池/镜像@快照
[root@node-44 ~]# rbd snap ls -p test zhanguo
SNAPID NAME SIZE
2 zhanguo123 20000 MB
[root@node-44 ~]#
[root@node-44 ~]# rbd info test/zhanguo@zhanguo123
rbd image ‘zhanguo’:
size 20000 MB in 5000 objects
order 22 (4096 KB objects)
block_name_prefix: rb.0.127d2.2ae8944a
format: 1
protected: False
[root@node-44 ~]#
查看一个镜像文件的快照
[root@os-node101 ~]# rbd snap ls -p volumes volume-7687988d-16ef-4814-8a2c-3fbd85e928e4
SNAPID NAME SIZE
5 snapshot-ee7862aa-825e-4004-9587-879d60430a12 102400 MB
删除一个镜像文件的一个快照快照
[root@os-node101 ~]# rbd snap rm volumes/volume-7687988d-16ef-4814-8a2c-3fbd85e928e4@snapshot-ee7862aa-825e-4004-9587-879d60430a12
rbd: snapshot ‘snapshot-60586eba-b0be-4885-81ab-010757e50efb’ is protected from removal.
2014-08-18 19:23:42.099301 7fd0245ef760 -1 librbd: removing snapshot from header failed: (16) Device or resource busy
上面不能删除显示的报错信息是此快照备写保护了,下面命令是删除写保护后再进行删除。
[root@os-node101 ~]# rbd snap unprotect volumes/volume-7687988d-16ef-4814-8a2c-3fbd85e928e4@snapshot-ee7862aa-825e-4004-9587-879d60430a12
[root@os-node101 ~]# rbd snap rm volumes/volume-7687988d-16ef-4814-8a2c-3fbd85e928e4@snapshot-ee7862aa-825e-4004-9587-879d60430a12
删除一个镜像文件的所有快照
[root@os-node101 ~]# rbd snap purge -p volumes volume-7687988d-16ef-4814-8a2c-3fbd85e928e4
Removing all snapshots: 100% complete…done.
把ceph pool中的一个镜像导出
导出镜像
[root@node-44 ~]# rbd export -p images –image 74cb427c-cee9-47d0-b467-af217a67e60a /root/aaa.img
2014-05-24 17:16:15.197695 7ffb47a9a700 0 – :/1020493 >> 10.49.101.9:6789/0 pipe(0x1368400 sd=3 :0 s=1 pgs=0 cs=0 l=1 c=0x1368660).fault
Exporting image: 100% complete…done.
导出云硬盘
[root@node-44 ~]# rbd export -p volumes –image volume-470fee37-b950-4eef-a595-d7def334a5d6 /var/lib/glance/ceph-pool/volumes/Message-JiaoBenJi-10.40.212.24
2014-05-24 17:28:18.940402 7f14ad39f700 0 – :/1032237 >> 10.49.101.9:6789/0 pipe(0x260a400 sd=3 :0 s=1 pgs=0 cs=0 l=1 c=0x260a660).fault
Exporting image: 100% complete…done.
把一个镜像导入ceph中 (但是直接导入是不能用的,因为没有经过openstack,openstack是看不到的)
[root@node-44 ~]# rbd import /root/aaa.img -p images –image 74cb427c-cee9-47d0-b467-af217a67e60a
Importing image: 100% complete…done.
来源:http://blog.csdn.net/wangtaoking1/article/details/46639645
更多参考:
官方网站:http://ceph.com/
官方源码:https://github.com/ceph/ceph
Ceph中国社区:http://ceph.org.cn/
Ceph中文文档:http://docs.ceph.org.cn/
Ceph分布式存储运维实践视频课程 http://edu.51cto.com/course/course_id-5230.html
UnitedStack相关ceph资源:https://www.ustack.com/page/1/?s=ceph