Ceph常见的几种异常状态——运维
【报错1】:HEALTH_WARN mds cluster is degraded!!!
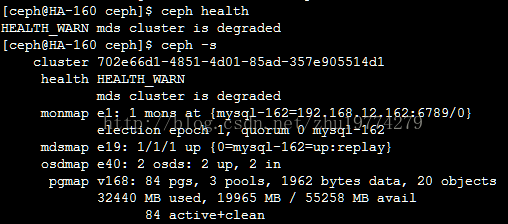
解决办法有2步,第一步启动所有节点:
service ceph -a start
如果重启后状态未ok,那么可以将ceph服务stop后再进行重启
第二步,激活osd节点(我这里有2个osd节点HA-163和mysql-164,请根据自己osd节点的情况修改下面的语句):
ceph-deploy osd activate HA-163:/var/local/osd0 mysql-164:/var/local/osd1
【报错2】:1 requests are blocked > 32 sec
原因:
有可能是在数据迁移过程中, 用户正在对该数据块进行访问, 但访问还没有完成, 数据就迁移到别的 OSD 中, 那么就会导致有请求被 block, 对用户也是有影响的
解决方法
寻找 block 的请求
# ceph health detail HEALTH_WARN 1 requests are blocked > 32 sec; 1 osds have slow requests 1 ops are blocked > 33554.4 sec 1 ops are blocked > 33554.4 sec on osd.16 1 osds have slow requests
可以看到 osd.16 具有一个操作 block
查询 osd 对应主机
# ceph osd tree
重启 osd
# /etc/init.d/ceph stop osd.16 # /etc/init.d/ceph start osd.16
系统会对该 osd 执行 recovery 操作, recovery 过程中, 会断开 block request, 那么这个 request 将会重新请求 mon 节点, 并重新获得新的 pg map, 得到最新的数据访问位置, 从而解决上述问题
参考恢复后的状态
[root@hh-yun-puppet-129021 ~]# ceph -s cluster dc4f91c1-8792-4948-b68f-2fcea75f53b9 health HEALTH_OK
【报错3】:too few PGs per OSD (16 < min 30)
$ sudo ceph osd lspools
0 rbd,
查看rbd pool的PGS
$ sudo ceph osd pool get rbd pg_num
pg_num: 64
pgs为64,因为是2副本的配置,所以当有8个osd的时候,每个osd上均分了64/8 *2=16个pgs,也就是出现了如上的错误小于最小配置30个
64/5*1=13《 30
解决办法:
修改默认pool rbd的pgs
$ sudo ceph osd pool set rbd pg_num 128
set pool 0 pg_num to 128
$ sudo ceph -s
cluster 257faba1-f259-4164-a0f9-1726bd70b05a
health HEALTH_WARN
64 pgs stuck inactive
64 pgs stuck unclean
pool rbd pg_num 128 > pgp_num 64
monmap e1: 1 mons at {bdc217=192.168.13.217:6789/0}
election epoch 2, quorum 0 bdc217
osdmap e52: 8 osds: 8 up, 8 in
flags sortbitwise
pgmap v121: 128 pgs, 1 pools, 0 bytes data, 0 objects
715 MB used, 27550 GB / 29025 GB avail
64 active+clean
64 creating
发现需要把pgp_num也一并修改,默认两个pg_num和pgp_num一样大小均为64,此处也将两个的值都设为128
$ sudo ceph osd pool set rbd pgp_num 128
set pool 0 pgp_num to 128
最后查看集群状态,显示为OK。
【报错】: too many PGs per OSD (704 > max 300)
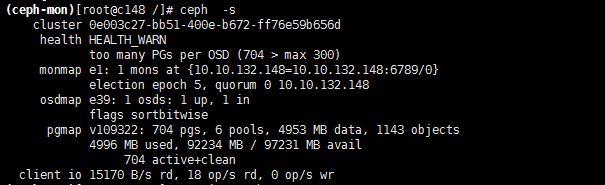
问题原因为集群osd 数量较少,测试过程中建立了大量的pool,每个pool要咋用一些pg_num 和pgs ,ceph集群默认每块磁盘都有默认值,好像每个osd 为128个pgs,默认值可以调整,调整过大或者过小都会对集群性能优影响,此为测试环境以快速解决问题为目的,解决此报错的方法就是,调大集群的此选项的告警阀值;方法如下,在mon节点的ceph.conf 配置文件中添加:
[global]
.......
mon_pg_warn_max_per_osd = 1000
然后重启服务:
/etc/init.d/ceph restart mon
临时生效:
# ceph tell 'mon.*' injectargs "--mon_pg_warn_max_per_osd 0"
使用tell命令修改的配置只是临时的,只要服务一重启,配置就会回到解放前,从ceph.conf 中读取配置。所以长久之计是把这个配置加到Ceph Mon节点的配置文件里,然后重启Mon服务。
【报错3】:若安装部署osd失败,怎么处理?
# ceph-deploy disk zap compute1s:sdb
# ceph-deploy --overwrite-conf osd create compute1s:sdb
【报错4】:状态是HEALTH_WARN,Monitor clock skew detected
ceph集群监控状态是HEALTH_WARN, clock skew detected on mon.cephmon154, Monitor clock skew detected
说明2个mon之间的时间相差超过允许值了,需要做同步。
Log报错信息:[WRN] mon.1 10.2.180.183:6789/0 clock skew 0.207341s > max 0.05s
【解决方法】在ceph上面/etc/ceph/ceph.conf中设置monitor间的允许时钟偏移最大值
[mon]
mon clock drift allowed = 2 #允许在mon之间差多少时间,默认为0.050秒
重启ceph
#service ceph restart
【报错】:root空间爆满,导致mon节点被自动踢出集群
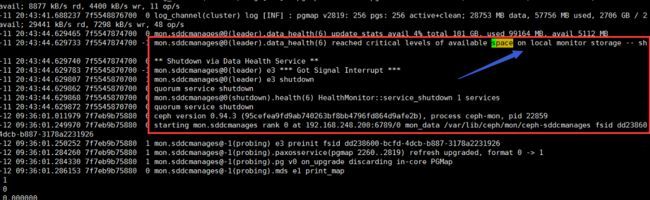
# service ceph restart