【PaddleHub创意赛】APP评论情感分析
项目链接
无意中测试了一下paddlehub的情感分析的(唯一的三分类模型)预训练模型emotion_detection_textcnn,发现英文的准确度好像没有中文高?
同一句话的中英文测试:
import paddlehub as hub
module = hub.Module(name = "emotion_detection_textcnn")#模型加载
test_text = ["你真丑", "You're so ugly"]
input_dict = {"text": test_text} #文字输入
results = module.emotion_classify(data = input_dict) #预测结果
for result in results:
print(result['text'])
print(result['emotion_label'])
print(result['emotion_key'])
probs_name = result['emotion_key'] + "_probs"
#print(result['negative_probs'])
#print(probs_name)
print(result[probs_name])#你真丑
#0
#negative
#0.9627
#You're so ugly
#1
#neutral
#0.9766本来是贬义的句子被误判为中性~
Kaggle的Google Play数据集含有APP的评论信息(包含:“APP”:APP的名称,“Translated_Review”:用户评论(已预处理并翻译成英文),“Sentiment”:情感分为:积极/消极/中性,“Sentiment_Polarity”:情绪极性得分,“Sentiment_Subjectivity”:情绪主观性得分)
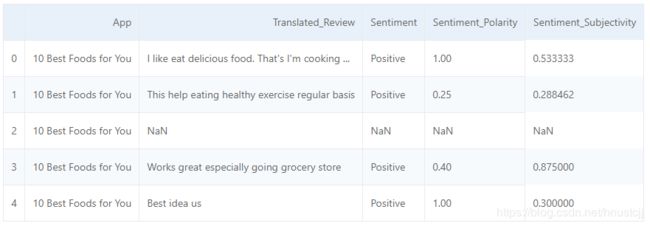
这里通过该数据集测试一下预训练模型并对APP的评论信息加以分析。大致思路:筛选数据;将评论信息翻译为中文;通过预训练模型预测;与真实类别比较计算准确度(预测正确的个数 / 总的个数,测试了小部分~)
尝试了三种方法将英文翻译为中文(项目中都有,这里只说最终用的方法):通过某道翻译,post请求要翻译的英文,获取对应的中文内容。
import requests
def translate(word):
# 有道词典 api
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 传输的参数,其中 i 为需要翻译的内容
key = {
'type': "AUTO",
'i': word,
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"ue": "UTF-8",
"action": "FY_BY_CLICKBUTTON",
"typoResult": "true"
}
# key 这个字典为发送给有道词典服务器的内容
response = requests.post(url, data=key)
# 判断服务器是否相应成功
if response.status_code == 200:
# 然后相应的结果
return response.text
else:
print("有道词典调用失败")
# 相应失败就返回空
return None
def get_cn(repsonse):
result = json.loads(repsonse)
#print ("输入的词为:%s" % result['translateResult'][0][0]['src'])
#print ("翻译结果为:%s" % result['translateResult'][0][0]['tgt'])
return result['translateResult'][0][0]['tgt']可先大致看一下评论情感极性分布(图在项目中有):发现最多的是“Positive”,然后是“Negative”,最后为Neutral。

大部分情绪极性评分大于零,意味总体的APP评论情绪偏向于积极!
3分类测试小部分:预处理去除评论和情感极性类别为空的行
#英文转中文
import time
en_to_cn = []
#translator = Translator(to_lang = "chinese")
for i in range(len(comments)):
#translation = translator.translate(comments[i])
word = comments[i]
list_trans = translate(word)
t = get_cn(list_trans)
en_to_cn.append(t)
if((i+1) % 20 == 0):
print(i+1,t)
time.sleep(0.5)结果:
#20 神健康
#40 良好的健康食品。
#60 伟大的
#80 predibetic食物列表简单,我害怕。
#100 伟大作品尤其是杂货店
#120 我发现很多财富形式健康…
#140 十佳食品健康促进健康必不可少的长期健康的生活方式使习惯吃的食物促进身体健康。
#160 减肥不坏
#180 废话不工作
#200 良好的搜索工作实习感觉翻译效果不太好,有强烈的预感结果不会很好~
module = hub.Module(name = "emotion_detection_textcnn")#模型加载
#comments,en_to_cn
test_text = en_to_cn
input_dict = {"text": test_text} #文字输入
results = module.emotion_classify(data = input_dict) #预测结果
emotion_key = []
probs = []
for j in range(len(results)):
probs_name = results[j]['emotion_key'] + "_probs"
emotion_key.append(results[j]['emotion_key'])
probs.append(results[j][probs_name])
if( (j+1) % 20 == 0):
print("第%d条有效评论"%(j+1))
print(results[j]['text'])
print(results[j]['emotion_label'])
print(results[j]['emotion_key'])
print(results[j][probs_name])正确率:
right = 0
for i in range(len(f)):
if(f[i] == emotion_key[i]):
right += 1
print("正确率为{:.2f}%".format(right/len(f)*100))果然很低:
#正确率为40.00%正确率不是很高原因有多种:
- 原有的翻译为en的评论信息不够完整(具体为单词不完整)
- 评论信息 带有主观性(原始数据集的情感极性类别真的正确么?)
- 英文翻译为汉语时不够准确(某道翻译准确?)
我还不太甘心,想继续测试一下二分类(积极与消极),去除中性的情感类别:
!hub install senta_lstm==1.1.0
#此模型只能做二分类
binary = app_comments_df[(app_comments_df['Sentiment'] == 'Positive') | (app_comments_df['Sentiment'] == 'Negative') ]K1 = 500
b_comments = list(binary['Translated_Review'][:K1].values)
senta = hub.Module(name = "senta_lstm")
#test_text = ["这家餐厅很好吃", "这部电影真的很差劲"]
test_text = b_comments
input_dict = {"text": test_text}
results = senta.sentiment_classify(data = input_dict)
b_pred = []
for j in range(len(results)):
probs_name = results[j]['sentiment_key'] + "_probs"
b_pred.append(results[j]['sentiment_key'])
#probs.append(results[j][probs_name])
if( (j+1) % 20 == 0):
print("第%d条有效评论"%(j+1))
print(results[j]['text'])
print(results[j]['sentiment_label'])
print(results[j]['sentiment_key'])
print(results[j][probs_name])首先测试了未翻译前的正确率:
right1 = 0
for i in range(len(f1)):
if (b_pred[i] == f1[i]):
right1 += 1
print("未翻译前 二分类正确率为:{:.2f}%".format(right1 / len(f1) * 100))结果显示:
#未翻译前 二分类正确率为:86.20%然后实验翻译后模型的正确率:
right2 = 0
for i in range(len(f1)):
if (preds1[i] == f1[i]):
right2 += 1
print("翻译后 二分类正确率为:{:.2f}%".format(right2 / len(f1) * 100))
##
##
#翻译后 二分类正确率为:83.40%正确率变低了,XSWL!!!
最后,如果你想知道某个APP的大致评价:
import matplotlib.pyplot as plt
import matplotlib.font_manager as font_manager
a_name = '10 Best Foods for You'
#a_name = app_name[2]
pinjia = app_comments_df[app_comments_df['App'] == a_name]['Sentiment'].value_counts()#.plot(kind = 'pie')
plt.pie(pinjia.values, labels = pinjia.index,
labeldistance = 1.1, autopct = '%3.1f%%', shadow = True,
startangle = 90, pctdistance = 0.6)
plt.title('Sentiment of APP: ' + a_name)
plt.show()图像:
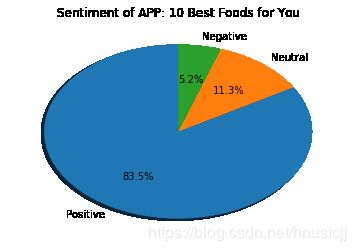
此APP评价比较好~