导读:XML文档解析是Java框架的基础技术之一。主流的的框架都采用XML文件来存储配置信息,然后通过解析它,将其分解成各种元素并用这些元素来实例化Configuration类。Java库提供两种XML解析器,分别是DOM解析和SAX解析。
XML文件解析器介绍
- DOM解析(Document Object Model),是树形解析,它是将读入的XML文件转换成树结构。
- SAX解析(Simple API for XML),是流机制解析,它是在读入XML文件时候生成相应的时间。
区别: DOM解析必须在解析之前将整个文档装入内存,处理大型文件时候,性能低,适合XML随机访问。SAX解析,事件驱动,它顺序读取XML文件,不需要一次全部载入整个文件,当遇到文件开头、文档结束、标签开头或者标签结束时,它会触发一个事件,用户通过在其回调事件中写入处理代码来处理XML文件,适合顺序访问。
DOM和SAX解析实例
XML文档准备,books.xml
Java 核心技术
Cornell
2014
89
深入浅出MyBatis
杨开振
2016
69
Java RESTful Web Service实战
韩陆
2016
59
XML对应java类
/**
* @author gethin
* @version 创建时间:2018年4月8日 下午2:17:51
* 类说明
*/
public class Book {
private int id;
private String name;
private String author;
private int year;
private double price;
@Override
public String toString() {
return "Book [id=" + id + ", name=" + name + ", author=" + author + ", year=" + year + ", price=" + price + "]";
}
getter,setter省略
}
DOM解析
要读入一个XML文档,首先需要一个DocumentBuilder对象,可以从DocumentBuilderFactory工厂类中得到这个对象。
DocumentBuilderFactory dBuilderFactory =DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder =dBuilderFactory.newDocumentBuilder();
然后可从文件中读入某个文档
File f=...
Document doc=dBuilder.parse(f);
或者用一个URL
URL u=...
Document doc=dBuilder.parse(u);
以books.xml文档为例,用DOM解析读取整个文档。
/**
* @author gethin
* @version 创建时间:2018年4月8日 下午3:17:04
* 类说明
*/
public class ReadXMLByDOM {
private static DocumentBuilderFactory dBuilderFactory = null;
private static DocumentBuilder dBuilder = null;
private static Document document = null;
private static List books = null;
static {
try {
/**
* 要读入一个XML文档,首先要有一个DocumentBuilder对象 可以从DocumentBuilderFactory中得到这个对象
*/
dBuilderFactory = DocumentBuilderFactory.newInstance();
dBuilder = dBuilderFactory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static List listBooks(String filename) throws SAXException, IOException {
List books=new ArrayList();
// 可通过DocumentBuilder对象的parse()方法读入整个文档
Document document = dBuilder.parse(filename);
// 获得根节点,books.xml对应的就是bookstore节点
Element root = document.getDocumentElement();
// 输出根节点的名字,bookstore
System.out.println(root.getTagName());
// 获得所有的book节点
NodeList children = root.getChildNodes();
//循环遍历各个book节点
for (int i = 0; i < children.getLength(); i++) {
//获得第i个book节点
Node child = children.item(i);
//用来存储第i个节点的内容
List bookAttrbuteContent=new ArrayList();
Book book=new Book();
/**
* 这里要注意的是dom会把两个节点之间的空白字符也当做节点 要判断是否是子元素,
* 而不是空白字符,这个可以参照 《Java核心技术卷 二》的解析XML文档章节,有详细的解释
*/
if (child instanceof Element) {
Element childElement = (Element) child;
int bookId=Integer.parseInt(childElement.getAttribute("id"));
System.out.println(bookId);
book.setId(bookId);
NodeList bookAttrbuteList = childElement.getChildNodes();
// 循环遍历book节点的各个子节点,如name,author...
for (int j = 0; j < bookAttrbuteList.getLength(); j++) {
Node bookAttrbute = bookAttrbuteList.item(j);
if (bookAttrbute instanceof Element) {
String content=bookAttrbute.getTextContent().trim();
System.out.println(
((Element) bookAttrbute).getTagName() + ":" + content);
bookAttrbuteContent.add(content);
}
}
book.setName(bookAttrbuteContent.get(0));
book.setAuthor(bookAttrbuteContent.get(1));
book.setYear(Integer.parseInt(bookAttrbuteContent.get(2)));
book.setPrice(Integer.parseInt(bookAttrbuteContent.get(3)));
books.add(book);
}
}
return books;
}
public static void main(String args[]) {
String fileName = "./src/main/java/com/gethin/xmlparser/books.xml";
try {
List books=ReadXMLByDOM.listBooks(fileName);
for(Book book:books) {
System.out.println(book);
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行截图

DOM解析books.xml运行截图
SAX解析
DOM解析器完整地读入了XML文档,将其转换为一个树形的结构。对于大多数应用,DOM都运行的很好。但是如果文档很大,而且处理算法又很简单。那么DOM解析可能效率非常低下,此时可以使用SAX解析。
SAX要解析XML文件首先要生成SAXParser,SAXParser可以通过SAXParserFactory工厂类生成。
SAXParserFactory saxParserFactory= SAXParserFactory.newInstance();
SAXParser saxParser=saxParserFactory.newSAXParser();
然后就可以处理XML文档了
saxParser.parse(source,handler)
source可以是一个文件,一个URL字符串或者一个输入流。handler属于DefaultHandler的一个子类。以下通过SAX来解析books.xml
/**
* @author gethin
* @version 创建时间:2018年4月12日 上午10:49:57
* 类说明
*/
class BookXMLParseHandler extends DefaultHandler {
private List list; // 存放解析到的book数组
private Book book; // 存放当前解析的book
private String content = null; // 存放当前节点值
@Override
public void startDocument() throws SAXException {
super.startDocument();
// System.out.println("开始解析xml文件");
list = new ArrayList();
}
@Override
public void endDocument() throws SAXException {
super.endDocument();
super.endDocument();
// System.out.println("xml文件解析完毕");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
// 当节点名为book时,获取book的属性id
if (qName.equals("book")) {
book = new Book();
String id = attributes.getValue("id");// System.out.println("id值为"+id);
book.setId(Integer.parseInt(id));
}
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
if (qName.equals("name")) {
book.setName(content);
// System.out.println("书名"+content);
} else if (qName.equals("author")) {
book.setAuthor(content);
// System.out.println("作者"+content);
} else if (qName.equals("year")) {
book.setYear(Integer.parseInt(content));
// System.out.println("年份"+content);
} else if (qName.equals("price")) {
book.setPrice(Double.parseDouble(content));
// System.out.println("价格"+content);
} else if (qName.equals("book")) { // 当结束当前book解析时,将该book添加到数组后置为空,方便下一次book赋值
list.add(book);
book = null;
}
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
content = new String(ch, start, length);
}
public List getBooks() {
return list;
}
}
public class ReadXMLBySAX {
private static SAXParserFactory saxParserFactory;
private static SAXParser saxParser;
static {
try {
saxParserFactory = SAXParserFactory.newInstance();
saxParser = saxParserFactory.newSAXParser();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
}
public static List listBooks(String fileName) throws SAXException, IOException {
BookXMLParseHandler handler = null;
handler = new BookXMLParseHandler();
saxParser.parse(fileName, handler);
return handler.getBooks();
}
public static void main(String args[]) {
String fileName = "./src/main/java/com/gethin/xmlparser/books.xml";
try {
List books = ReadXMLBySAX.listBooks(fileName);
for (Book book : books) {
System.out.println(book);
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行截图
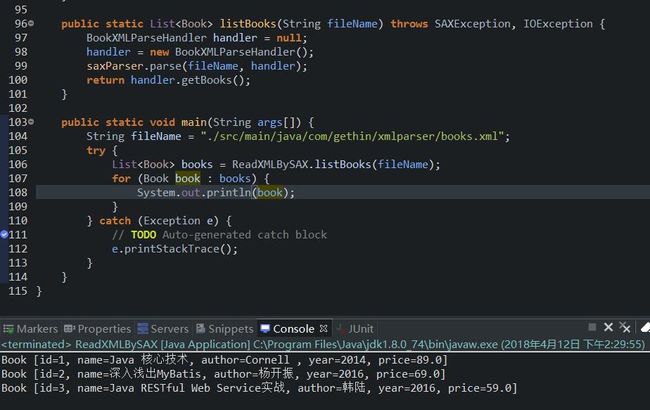
SAX解析XML运行截图