python nltk库的安装和简单使用
nltk库是python语言为自然语言处理提供的一个功能强大,简单易用的函数库,是学习和进行自然语言处理工作的出色工具,这里加少一下nltk模块的安装和简单使用
1.安装nltk
windows系统:
- Install Python 3.5: http://www.python.org/downloads/ (avoid the 64-bit versions)
- Install Numpy (optional): http://sourceforge.net/projects/numpy/files/NumPy/ (the version that specifies python3.5)
- Install NLTK: http://pypi.python.org/pypi/nltk
- Test installation:
Start>Python35, then typeimport nltk
Mac和Linux系统命令
sudo pip install -U nltk有些mac系统可能需要先安装pip,命令为;
sudo easy_install pip
说明系统中已经存在six 1.4.1,而且sudo命令也无法覆盖系统中已有的project,这时可以用下面命令
sudo pip install nltk --upgrade --ignore-installed six安装完成后,使用 nltk.download() 下载数据包
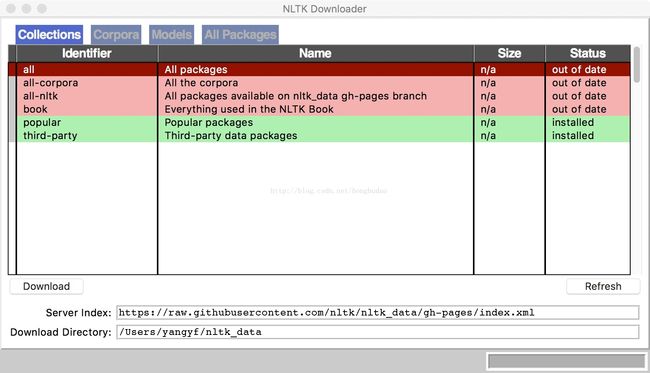
下面就可以用nltk愉快的进行自然语言处理编程了,首先测试分词和词性标注
>>> import nltk
>>> sentence = """At eight o'clock on Thursday morning
... Arthur didn't feel very good."""
>>> tokens = nltk.word_tokenize(sentence)
>>> tokens
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning',
'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
>>> tagged = nltk.pos_tag(tokens)
>>> tagged[0:6]
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'),
('Thursday', 'NNP'), ('morning', 'NN')]>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'),
('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
Tree('PERSON', [('Arthur', 'NNP')]),
('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'),
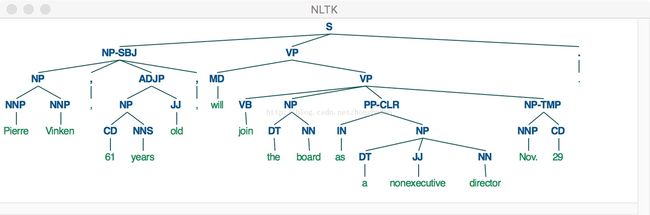
('very', 'RB'), ('good', 'JJ'), ('.', '.')])语法解析树
>>> from nltk.corpus import treebank
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> t.draw()