中科院计算所在可信大数据软件技术方面的研究工作【DOC+PPT下载】
http://pan.baidu.com/s/1qWOCMxm
清单:
中科院计算所在可信大数据软件技术方面的研究工作.doc 【本文doc文档】
中科院计算所在可信大数据软件技术方面的研究工作.ppt 【本文ppt演讲稿】
PS:前段时间接到任务,对中科院计算所在可信大数据软件技术方面的研究工作进行调研,以下是正文。
第1章 鉴定/验收的代表性成果
1.1 天玑大规模网络信息处理系统
在 国 家“973” 课题“ 基 于 Internet 超大规模知识检索的算法及应用”(课题编号:G1998030413)、“大规模文本内容计算”(课题编号:2004CB318109),以及“863”计划“大规模网络内容安全监控关键技术与示范系统研究(课题编号:2006AA01Z452)”、“863”计划子课题“CNGrid 网格软件测试及工程化”(课题编号:2005AA119010)等项目的持续支持下,中科院计算所和国家计算机网络与信息安全管理中心等单位历时十余年研制了“天玑大规模网络信息处理系统”。
“天玑大规模网络信息处理系统”覆盖了大规模网络信息获取、存储与管理、分析与挖掘等深度处理的关键环节,在信息分析的精度、信息挖掘的深度和信息处理的广度等方面取得了系统性成果。系统在高维稀疏特征的精准分析、多元异构数据融合的深度挖掘、跨尺度演变的聚集行为发现和海量数据的分布式存储管理等四个方面的关键技术上取得了重要突破。项目所形成的技术成果发表学术论文356余篇,SCI收录 60余篇,被包括Nature、PhysicsReports、IEEE汇刊等SCI学术刊物引用 183 次。已形成了覆盖网络信息监测与服务领域成体系的核心技术发明专利群和软件著作权,申请发明专利20项,授权12项,软件著作权16项。该系统在由美国国防部高级研究计划局(DARPA)、美国国家标准技术研究所(NIST)等机构主办的国际权威评测中,有4 项技术获得国际排名第一;所提出来的分布式数据存储结构(RCFile)技术系国际首创,被Apache Hive、Pig 等主流开源软件采纳,已成为国际上分布式离线数据分析系统中存储结构的事实标准;所研制的开源软件影响范围遍及全球,全文索引与检索平台系统(Firtex)全球下载10万余次,在东亚开源大赛中获得杰出成就奖。
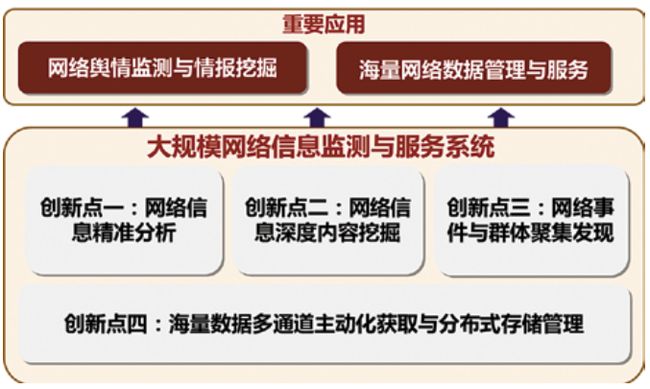
系统结构框图
项目在核心技术和应用系统上均实现突破,整体系统和关键技术在国务院新闻办、中国人民解放军、公安部、安全部、教育部、工信部、广电总局、中国证监会、中国互联网协会等国家级网络空间舆情分析、情报挖掘等重大战略性任务中得到规模化应用,在重大突发事件的监测中,分析结果准确,反应及时。在北京奥运会、上海世博会、广州亚运会、国庆 60 周年、全国“两会”、台湾地区领导人选举等特殊时期的信息监测与安全保障中发挥了重要作用,为维护社会稳定、保障国家安全做出了突出贡献。同时,成果在中国教育电视台、华为公司、百度公司、淘宝公司等大型企业的线上系统中得到广泛使用,显著提升了大型互联网企业的核心竞争力,取得了突出的经济效益。该成果为满足国家网络空间的战略需求,推动互联网产业的发展做出了重要贡献。该成果于 2011 年 8 月 7 日通过了由中国科学院在北京组织的科技成果鉴定会。由何德全、胡启恒、邬贺铨、陈俊亮、王小谟、蔡吉人、姜景山、戴浩、张尧学、于全等 10 位院士和领域内著名专家组成的鉴定委员会一致认为,该系统“技术难度很大,在理论与技术上均具有重大创新,研究成果整体上处于国际先进水平。其中,中文词法分析、查询推荐、网络核心人物发现、网络动态更新摘要、关联实体查找、行列混合式数据存储等算法与技术达到国际领先水平;RCFile 技 术系国际首创,被 Apache Hive、Pig等主流开源软件采纳,已成为国际上分布式离线数据分析系统中存储结构的事实标准。建议进一步加强应用系统的规模化产品开发和市场推广,进一步发挥系统在国家重大任务中的作用”。“大规模网络信息监测与服务系统关键技术及应用”获得 2011 年度“中国电子学会电子信息科学技术奖”一等奖。

获中国电子学会电子信息科学技术一等奖
1.2 基于虚拟机架构的可信计算环境与可信软件设计
本项目为国家自然科学基金重点项目(编号为 90718040),于 2011 年 1 月通过国家基金委验收,验收结果为“优秀”,项目取得如下成果:
◇ 在平台基础设施方面,对虚拟计算资源的建模、分配与隔离、有效利用与管理等方面进行了深入的研究,并按计划书要求构建了TRainbow 可信虚拟计算平台系统。在此平台基础上,重点对虚拟集群的可信增强技术、信任链构建机制、虚拟平台的可靠机制、虚拟监控器的可信机理等进行了研究。
◇ 项目组在下列研究领域取得了若干创新成果:可信平台能力服务计算理论及三层资源调度框架和以此为基础的按需资源流动算法、可信平台下服务整合的效用分析模型、管理域及虚拟存储的完整性检测方法、基于多核技术的可信计算机制、面向流动的内存全局优化方案、指令监控和替换技术、虚拟机监控器多域隔离技术、虚拟域运行时监控技术、虚拟集群中休眠节点的Optimal 和 Demotion 管理算法等。
◇ 实现了包括 TRainbow 可信虚拟计算平台、TMemCanal 内存全局优化系统、VMGuard管理域完整性检测系统、VSchecker 虚拟存储完整性透明检测工具、Luvalley 虚拟机监视器等多个虚拟机架构下的可信保障及增强系统,为后续研究工作提供了平台和基础。项目成果在中国移动大云计划“基于虚拟化的 DSN 多业务融合架构研究项目”和华为云计划“基于 Xen 架构虚拟机安全技术合作项目”中得到推广应用。作为对本项目工作的进一步延续与发展,项目组拟以网络服务器可信增强技术为切入点申请国家自然科学基金项目“云计算环境下虚拟化网络服务器的可信增强技术”。项目发表学术论文 31 篇;申请国家发明专利14 项,已授权 3 项;申请软件登记 2 项,1 项已登记;培养博士 9 名、硕士 16 名;有 10 人次参加国际学术会议。
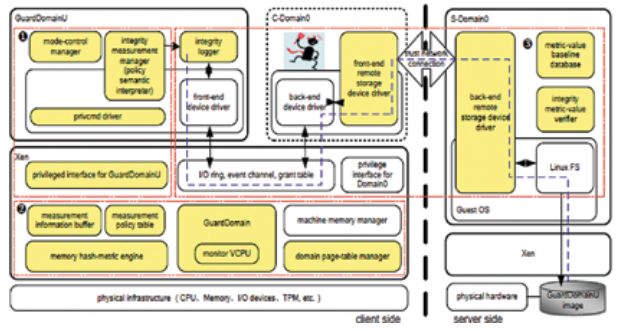
VMGuard :一种面向管理者虚拟机的完整性检测系统

VSchecker :透明的虚拟存储完整性检测工具
1.3 基于云计算的海量数据挖掘
本项目为国家基金重点项目(课题编号:61035003),起止时间是 2011 年 1 月至 2014年 12 月。项目组按计划进行深入研究,圆满地完成了2013 年的工作,取得如下进展。
1. 基于云计算的海量数据挖掘方法和算法
(1)并行数据挖掘方法利用数据库来模拟链表结构,管理挖掘出来
的知识,提供了树形结构、图模型的分布式计算方法,提出一种在 Hadoop 上高效数据挖掘框架。
为了加速分布式 SVM 优化的全局一致性,我们提出分组式的分布式交替方向乘子法,引入分组机制,将学到的组结构信息用于全局变量优化。
(2)特征捆绑框架
针对视觉感知,提出特征捆绑的 CCF 框架,由视觉特征提取、紧凑编码、特征捆绑三层构成。针对视频轨迹,提出了一种基于轨迹分段与多示例学习的异常检测框架 TRASMIL。提出了多模态稀疏表示分类器 mSRC。提出混合生成式和判别式学习的图像自动标注模型 HGDM、基于概率潜语义分析(PLSA) 和最大二等分模型(MAX-BIS) 的图像语义标注方法、基于概率潜语义分析 (PLSA) 和随机游走模型(RW) 的两阶段精细化图像语义标注方法。
(3)基于大脑皮层功能柱结构的粒度计算基于粒度计算的观点把模糊逻辑设计与机器学习有机的结合起来,提出了脑皮层粒度计算模型。该方法能有效提升照片的信息含量,具有更好的去雾效果。
(4)跨领域典型相关性分析
针对大数据环境下,由于数据快速更新带来的有标签训练样本与测试样本间分布的差异,提出了一种跨领域典型相关性分析 CD-CCA 算法。
该算法在传统典型相关性分析方法的基础上,结合基于特征映射迁移学习的思路,用于分析领域特有特征与领域共享特征之间的相关性。
(5)数据挖掘算法
提出多类监督型新分类器、安全性半监督学习算法、无监督大间隔聚类算法、 基于视图间成对约束信息的协同度量学习方法,并以并行结构集成的鲁棒人脸识别模型及其相应算法。
2. 海量数据预处理
(1)云数据库系统
研究了云数据库系统 GCDB,对其系统架构、功能模块进行设计。云数据库系统采用了分布式架构和数据查询优化技术的关键技术。
(2)特征选择
针对多目标问题,结合基于 Pareto 优化的演化算法设计了特征选择方法,并与传统的单一目标方法进行了实验对比。提出一种基于视图差异性与相关分析的多视图特征选择方法,来同时选择每个视图的差异性特征与判别性特征。
(3)维度约简与特征降维
提出了决策粗糙集模型中基于最小化决策代价的优化问题。提出了启发式算法、遗传算法和模拟退火算法三种约简算法。
对于非线性降维,我们提出一种基于关系图增强融合类别信息的图像语义流形学习算法,可充分利用反馈信息,有效实现高维图像特征数据的降维,学习查询图像的语义子空间。
3. 面向海量数据挖掘的云计算模式
(1)GCFS 云存储系统
研究了存储虚拟化,提出了一种分布式存储技术:GCFS 云存储系统。对其系统架构采用分布式架构进行设计,对系统可用性、数据安全、数据去重等关键技术进行了研究。
4. 基于云计算的海量数据挖掘按需服务
(1)自适应支撑框架
为海量数据挖掘云服务提供了一个自适应的支撑框架,具有自适应需求描述语言等。
(2)Web 服务
提出了一种全新的 web 服务分解算法,将QoS 优化和冗余服务去除两个功能整合到一起。
(3)自适应学习算法
针对大规模离散(或连续)状态空间强化学习问题,提出了基于分段线性基的时间差分学习方法 PLVF-TD。
(4)扩展多智能体环境 MAGE
扩 展 了 多 智 能 体 环 境 MAGE, 增加 了BDI 推理机,构建具有推理机的多智能体环境MAGER。
5. 云计算海量数据挖掘引擎
初步开发了大数据挖掘云引擎 CBDME,为智能城市知识数据中心提供解决方案。研发基于MapReduce 的并行海量数据挖掘算法工具箱DoDo。
2013年度发表专著3本,发表国际期刊论文35篇,其中SCI收录25篇,EI收录10篇,发表国际会议上论文33篇,其中EI收录19篇,在国内重要期刊发表(含录用)文章14篇,其中EI收录5篇,参加国际会议特邀报告2次,国内会议特邀报告7次。申请国家专利11项,已有2项获得正式授权。获软件著作权4项。课题负责人史忠植获得2013年中国人工智能学会吴文俊人工智能科学技术成就奖。
第2章 研究方向科研进展
2.1 面向大数据处理的存储系统(软件)研究
键值数据的组织方式,是影响高通量大数据系统性能的关键。本项目从构建一个数据中心软件栈的基石的角度出发,设计和开发了一个扩展键值对象存储系统 EKOS(Extended KeyObjectStore)。EKOS 设计和实现了如下有别于传统键值存储系统的创新特征:支持不同粒度对象的高效存储和管理;为基于其构建文件系统、数据库等提
供了丰富的可扩展的对象接口;支持异构存储资源的动态管理。大量实验结果表明,EKOS 相对经典的键值存储系统和文件系统等,性能均有明显的提升。对于广泛应用于大数据键值存储和管理系统的 LSM(LogStructured Merge tree)数据组织,创新性地提出了基于流水线的键值排序算法,明显提升了 EKOS 的读写性能。针对部分大数据应用对 Range Query 结果精确度要求不高,但对系统效能要求较高的场景,创新性地提出了用户自定义的高效能 Range Query 机制。主要研究成果包括专利申请 12 项,发表 CCF B 类会议论文 1 篇,workshop 论文 1 篇,软件原型系统 1 个。
2.2 大数据基准测试程序集
BigDataBench 是 一 个 抽 取 Internet 典型服务构建的大数据基准测试程序集,覆盖了微基准测试、CloudOLTP、关系查询、搜索引擎、社交网络和电子商务六种典型应用场景,包含十九种不同类型的负载和六种不同类型的数据 集。 此 外 BigDataBench 还 提 供 了 数 据生成工具 –BDGS。该工具能在保留原始数据特性的基础上以小规模真实数据生成大规模数据。BigDataBench 同 时 涵 盖 了 完 整 的 系 统 软件栈,覆盖的应用类型包括:实时分析、离线分析和在线服务应用。目前 BigDataBench 的用户包括:华为、国家互联网应急中心、OSH、SAIT 等国内外企业、高校和研究机构;研究领域包括:负载特征刻画、系统评测和性能优化分 析 等。BigDataBench的相关工作已经发表在 IISWC2013(最佳论文)、HPCA2014、Dasfaa2014 等国际知名会议。

大数据基准测试程序集
第3章 科研基地进展
3.1 中科院网络数据科学与技术重点实验室
学科基地对计算所可持续发展至关重要。2013 年 4 月中科院批准成立网络数据科学与技术重点实验室,并于 2013 年 11 月正式揭牌成立。该实验室是我国首个专门研究网络大数据的省部级重点实验室。重点实验室的建设目标是推动网络数据学科发展,突破 ZB 级网络数据感知、传输、存储、管理与分析体系架构,研究网络数据界的溯源、定位、预测与控制方法,支撑安全大数据、情报大数据、金融大数据、商业与媒体消费大数据等系列应用。2013 年在基础研究、大项目争取、数据平台建设和推动大数据研究与发展等方面都取得了进展。具体包括:
在基础研究方面,围绕着网络数据研究,发表论文近 70 篇,专著 1 部,译著 1 部,文章总数比去年增长 16%。其中,发表在 Plos One 等A 类期刊上的论文有 9 篇,发表在 WWW、SIGIR等 A 类会议上的论文有 13 篇,A 类会议文章增长 46%。同时我们组织了和大数据和社会计算相关的学术专刊,撰写了一系列与大数据相关的前瞻性论文,完成了大数据学科的布局与推进。

网络数据科学与技术重点实验室研究布局
在网络数据平台建设方面,面向高端数据分析、金融数据工程、互联网信息监测、商业智能等应用,积累数据的规模持续增长。建成了数千个计算节点,PB 级存储容量,Gbps级互联网带宽和大量群体合作的网络爬盟与网络感知;达到百万领域信源入口,千万级 ID 与自媒体源,亿级微博关联用户、百万级名博关注;积累了带标签的百亿级网页、百亿级消息文本信息、每天千万级消息更新。与 2012 年底相比,信源增加 6倍,配置效率提高 1倍,积累百亿消息文本信息,每天千万级消息更新。
在重要项目争取方面,由中国科学院计算技术研究所牵头,华云生教授作为首席科学家,联合清华大学、北京大学、中国人民大学、同济大学、天津大学、武汉大学、公安部第三研究所等单位共同申报并获得立项的国家重点基础研究发展计划(973 计划)项目“网络大数据计算的基础理论及其应用研究”。这是我国在大数据研究领域被批准的第一个国家 973 计划项目。

网络数据科学与技术重点实验室学术委员会2013年度会议
在推动大数据学科与产业发展方面,牵头组织了的国内规模最大、最具影响的大数据领域技术盛会——2013中国大数据技术大会(Big Data Technology Conference 2013,BDTC 2013)。大会以“应用驱动的架构与技术”为主题,邀请了多位国际著名专家以及来自Hortonworks、Cloudera、Linkedin、阿里、腾讯、百度、中国移动、华为等大数据相关企业的80 余位演讲嘉宾,参会人数接近2000 人,在学界和业界都产生了重大影响,已成为大数据领域的旗帜性技术大会。

网络数据科学与技术重点实验室揭牌仪式
第4章 学术活动
4.1 中国大数据技术大会
2013年12月5-6日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,我所与CSDN具体组织的中国规模最大、最具影响的大数据领域技术盛会——2013中国大数据技术大会(Big Data TechnologyConference 2013,BDTC 2013)在北京世纪金源大饭店圆满落幕。
本次大会的前身是去年举办的“Hadoop与大数据技术”大会,在此之前是“Hadoop中国云计算大会(Hadoopin China)”。为了因应大数据时代的到来,今年大会正式更名为“中国大数据技术大会(Big Data Technology Conference,BDTC)”。 BDTC 2013以“应用驱动的架构与技术”为主题,共设立“大数据架构与系统”、“大数据技术”、“大数据应用”、“大数据研究与发展”,“大数据基准测试(Benchmark)”五大技术分论坛,并首次增加“2013中国智能交通与大数据技术峰会”和“传统行业如何驾驭大数据总裁研讨会”。作为分论坛数量最多的一届大会,2013中国大数据技术大会参会人数首次突破2000人。
2014中国大数据技术大会(Big Data TechnologyConference 2014,BDTC 2014)暨第二届CCF大数据学术会议于12月12-14日在北京新云南皇冠假日酒店顺利召开。本次大会由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,由中科院计算所与CSDN具体组织,主旨在于推进大数据科研、应用与产业的发展。

CCF大数据专委会主任李国杰院士致辞
本次大会历时三天,以更加国际化的视野,帮助与会者了解海内外大数据技术的发展趋势;从技术与实践角度出发,探讨“大数据生态系统”、“大数据技术”、“大数据应用”、“大数据基础设施”等领域的新技术应用和实践经验;通过创新大赛和培训课程等方式,深度剖析大数据创业热点和分享行业实战经验。为了更好地讨论大数据技术生态系统的现状和发展趋势,交流大数据技术实践经验,进一步推进大数据技术创新与应用,展示国内外大数据领域的最新成果。
BDTC 2014特邀近百位来自全球大数据产业界知名学者、企业领军人物、行业资深专家、一线实践技术代表,内容涵盖Hadoop、YARN、Spark、Tez、HBase、Kafka、OceanBase等开源软件的最新进展,NoSQL/NewSQL、内存计算、流计算和图计算技术的发展趋势,OpenStack生态系统对于大数据计算需求的思考,以及大数据下的可视化、机器学习/深度学习、商业智能、数据分析等的最新业界应用。
在大会开幕式上,中科院计算所网络数据科学与技术重点实验室主任程学旗研究员作为CCF大数据专家委员会秘书长发布了《中国大数据技术与产业发展白皮书(2014)》和《2015大数据十大发展趋势预测》,代表了百余位业内专家在大数据典型应用现状、大数据技术体系现状、大数据IT产业链与生态环境、大数据人才资源、大数据发展趋势与建议等方面的深入思考,为企业制定大数据战略规划提供了极具价值的参考建议。

程学旗研究员发表大数据白皮书与发展趋势报告
作为中国大数据领域最具价值的IT盛会,历经七届沉淀,中国大数据技术大会已经成为中国最具影响、规模最大、参会者人数最多的大数据领域技术盛会。2014中国大数据技术大会对于产业的发展与推进有着重要意义。2014中国大数据技术大会,六十余场主题演讲、技术论坛和专业培训,数千名业内人士与会齐聚的深度实践之旅。作为大数据技术与应用深度结合的新起点,BDTC 2014已经成为产业界、科技界与政府部门密切合作的新平台,为推动我国大数据的产学研用做出了重大贡献。
第5章 结论与研究点思考
在大数据概念兴起之前,中科院计算所围绕大规模信息处理已经开展了多个国家项目的研究,并研制了天玑系统、海云系统等等。近年来随着大数据技术的流行,计算所成立了网络数据科学与技术重点实验室,重点研究突破 ZB 级网络数据的感知、传输、存储、管理与分析体系架构,网络数据界的溯源、定位、预测与控制方法,研发支撑安全大数据、情报大数据、金融大数据、商业与媒体消费大数据等系列应用,在A类期刊和会议上发表了20多篇论文。计算所牵头申请获批的973项目是在大数据研究领域被批准的第一个国家 973 计划项目。由计算所具体组织的中国大数据技术大会是目前我国规格最高的大数据方面的技术会议,已经成为产业界、科技界与政府部门密切合作的新平台。综上所述,在大数据软件技术领域,中科院计算所在在研项目、论文、学术活动等方面的成果较为突出。