Python scrapy使用入门,爬取拉勾网上万条职位信息(下)
继续之前的笔记。上节实现了数据爬取和导出文件。这节学点干的,模拟浏览器请求,对付拉钩的反爬策略,爬取二级页面,获取到具体的职位,薪资等数据。
我们上节爬取的是分类的内容,我们实际浏览网页也是点击分类进入二级页面看职位列表,上节爬取的链接,就是我们点击的那个链接,我们已拿到了:

现在我们点击Java进入二级页面,假如我们要获取如下信息:

使用cookie给爬虫做伪装,应付反爬策略
首先我们通过如下代码访问到二级页面:
yield scrapy.Request(url = jobUrl , callback=self.parse_url)
callback是回调函数,我们需要在下面实现这个方法,但是有一点我们需要提前完成,那就是攻克拉勾的反爬虫机制,我们通过设置cookie来完成这个功能,接下来先教大家获取到cookie。
在Java这个二级页面,F12调出开发者模式
,按F5刷新界面,如图,可以看到发了4个请求,第一个根据字面猜测应该是我们找的那个请求。
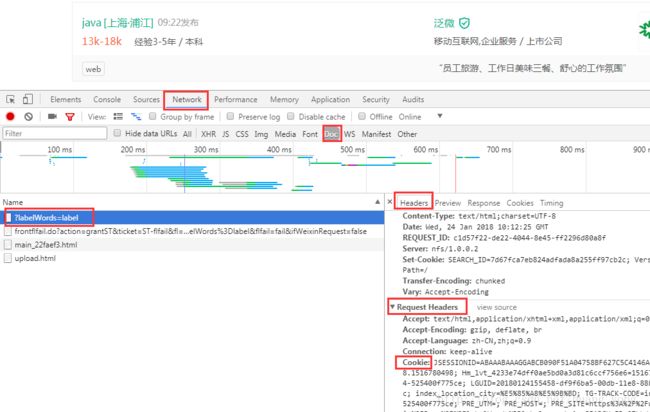
将header里的request的cookie复制出来先放到记事本中,我们需要对其处理后变成键值对的格式,放入scrapy中,完整代码如下:
# -*- coding: utf-8 -*-
import scrapy
from First.items import FirstItem
class SecondSpider(scrapy.Spider):
name = 'second'
allowed_domains = []
start_urls = ['https://www.lagou.com/']
cookie = {
"JSESSIONID": "ABAAABAAAGGABCB090F51A04758BF627C5C4146A091E618",
"_ga": "GA1.2.1916147411.1516780498",
"_gid": "GA1.2.405028378.1516780498",
"Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6": "1516780498",
"user_trace_token": "20180124155458-df9f65bb-00db-11e8-88b4-525400f775ce",
"LGUID": "20180124155458-df9f6ba5-00db-11e8-88b4-525400f775ce",
"X_HTTP_TOKEN": "98a7e947b9cfd07b7373a2d849b3789c",
"index_location_city": "%E5%85%A8%E5%9B%BD",
"TG-TRACK-CODE": "index_navigation",
"LGSID": "20180124175810-15b62bef-00ed-11e8-8e1a-525400f775ce",
"PRE_UTM": "",
"PRE_HOST": "",
"PRE_SITE": "https%3A%2F%2Fwww.lagou.com%2F",
"PRE_LAND": "https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2FJava%2F%3FlabelWords%3Dlabel",
"_gat": "1",
"SEARCH_ID": "27bbda4b75b04ff6bbb01d84b48d76c8",
"Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6": "1516788742",
"LGRID": "20180124181222-1160a244-00ef-11e8-a947-5254005c3644"
}
def parse(self, response):
for item in response.xpath('//div[@class="menu_box"]/div/dl/dd/a'):
jobClass = item.xpath('text()').extract()
jobUrl = item.xpath("@href").extract_first()
oneItem = FirstItem()
oneItem["jobClass"] =jobClass
oneItem["jobUrl"] = jobUrl
yield scrapy.Request(url=jobUrl, cookies=self.cookie,callback=self.parse_url)
def parse_url(self,response):
print("parse_url 方法")
再次运行爬虫,出现如下页面,302重定向到了登录页面

重定向到了拉钩的登录界面,在这个界面我们是无法爬取到数据的,所以我们应该想办法解决这个问题,这也是拉勾的另一个反爬虫机制。
因为我们没有使用浏览器代理来进行请求,拉勾网可以通过这个方式来对我们的爬虫进行重定向,使我们无法获取到数据
我们需要获取到User-Agent ,用来模拟浏览器访问
还在刚才获取cookie的页面,在最下面可以看到我们需要的User-Agent
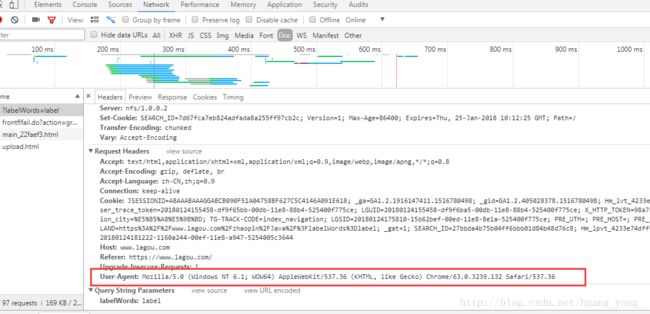
配置settings.py文件,User-agent可以设置多个,以逗号分开,这里先写两个,一个是Windows下的,一个是Linux下的,Linux的我是从虚拟机Linux里的火狐浏览器拿到的,然后配置为随机用其中一个。
MY_USER_AGENT = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
]
然后我们还需要对下载中间件进行配置:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
'First.middlewares.MyUserAgentMiddleware': 400,
}
settings.py最终如图所示:

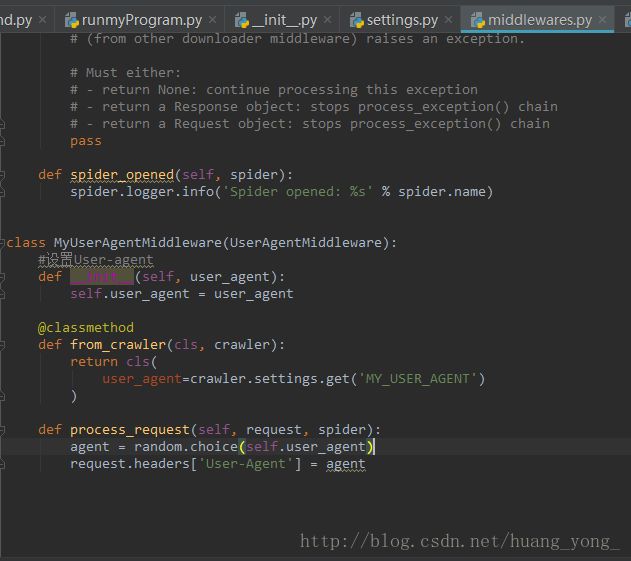
然后进入middlewares.py文件,进行User-Agent的选择:
首先导入所需依赖:
import scrapy
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
在下面定义类,继承UserAgentMiddleware,对User-Agent进行设置:
class MyUserAgentMiddleware(UserAgentMiddleware):
#设置User-agent
def __init__(self, user_agent):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
return cls(
user_agent=crawler.settings.get('MY_USER_AGENT')
)
def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agent
如图:
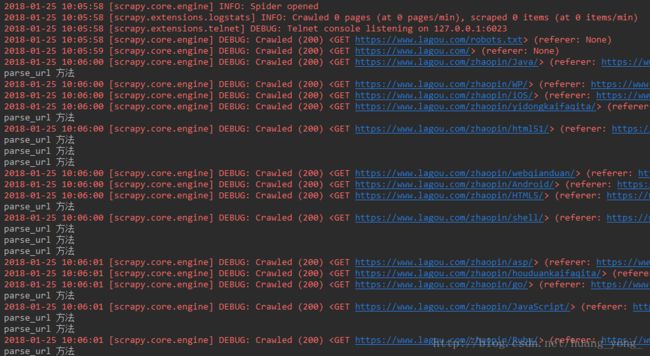
然后再次运行爬虫,状态码200,访问正常,成功回调:
接下来我们又需要分析网站的结构,来获取到自己需要的数据
还是使用之前的方法:

还是用xpath方法提取所需的数据:
先在Item.py中定义字段:
jobName = scrapy.Field()
jobMoney = scrapy.Field()
jobNeed = scrapy.Field()
jobCompany = scrapy.Field()
jobType = scrapy.Field()
jobSpesk = scrapy.Field()
然后在second.py中增加解析代码:
def parse_url(self,response):
for sel2 in response.xpath('//ul[@class="item_con_list"]/li'):
jobName = sel2.xpath('div/div/div/a/h3/text()').extract()
jobMoney = sel2.xpath('div/div/div/div/span/text()').extract()
jobNeed = sel2.xpath('div/div/div/div/text()').extract()
jobCompany = sel2.xpath('div/div/div/a/text()').extract()
jobType = sel2.xpath('div/div/div/text()').extract()
jobSpesk = sel2.xpath('div[@class="list_item_bot"]/div/text()').extract()
Item = FirstItem()
Item["jobName"] = jobName
Item["jobMoney"] = jobMoney
Item["jobNeed"] = jobNeed
Item["jobCompany"] = jobCompany
Item["jobType"] = jobType
Item["jobSpesk"] = jobSpesk
yield Item
格式同上篇一样,最终second.py完整代码如下:
# -*- coding: utf-8 -*-
import scrapy
from First.items import FirstItem
class SecondSpider(scrapy.Spider):
name = ‘second’
allowed_domains = []
start_urls = [‘https://www.lagou.com/‘]
cookie = {
"JSESSIONID": "ABAAABAAAGGABCB090F51A04758BF627C5C4146A091E618",
"_ga": "GA1.2.1916147411.1516780498",
"_gid": "GA1.2.405028378.1516780498",
"Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6": "1516780498",
"user_trace_token": "20180124155458-df9f65bb-00db-11e8-88b4-525400f775ce",
"LGUID": "20180124155458-df9f6ba5-00db-11e8-88b4-525400f775ce",
"X_HTTP_TOKEN": "98a7e947b9cfd07b7373a2d849b3789c",
"index_location_city": "%E5%85%A8%E5%9B%BD",
"TG-TRACK-CODE": "index_navigation",
"LGSID": "20180124175810-15b62bef-00ed-11e8-8e1a-525400f775ce",
"PRE_UTM": "",
"PRE_HOST": "",
"PRE_SITE": "https%3A%2F%2Fwww.lagou.com%2F",
"PRE_LAND": "https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2FJava%2F%3FlabelWords%3Dlabel",
"_gat": "1",
"SEARCH_ID": "27bbda4b75b04ff6bbb01d84b48d76c8",
"Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6": "1516788742",
"LGRID": "20180124181222-1160a244-00ef-11e8-a947-5254005c3644"
}
def parse(self, response):
for item in response.xpath('//div[@class="menu_box"]/div/dl/dd/a'):
jobClass = item.xpath('text()').extract()
jobUrl = item.xpath("@href").extract_first()
oneItem = FirstItem()
oneItem["jobClass"] =jobClass
oneItem["jobUrl"] = jobUrl
yield scrapy.Request(url=jobUrl, cookies=self.cookie,callback=self.parse_url)
def parse_url(self,response):
for sel2 in response.xpath('//ul[@class="item_con_list"]/li'):
jobName = sel2.xpath('div/div/div/a/h3/text()').extract()
jobMoney = sel2.xpath('div/div/div/div/span/text()').extract()
jobNeed = sel2.xpath('div/div/div/div/text()').extract()
jobCompany = sel2.xpath('div/div/div/a/text()').extract()
jobType = sel2.xpath('div/div/div/text()').extract()
jobSpesk = sel2.xpath('div[@class="list_item_bot"]/div/text()').extract()
Item = FirstItem()
Item["jobName"] = jobName
Item["jobMoney"] = jobMoney
Item["jobNeed"] = jobNeed
Item["jobCompany"] = jobCompany
Item["jobType"] = jobType
Item["jobSpesk"] = jobSpesk
yield Item
现在工作已经完成,准备执行,这次我们将数据导出到json,为了执行方便,建议在IDE中定义好运行文件,例如我之前建立的runmyProgram.py,修改其中命令,如图:

然后执行runmyProgram.py文件,控制台开始输出数据,爬虫已开始工作。
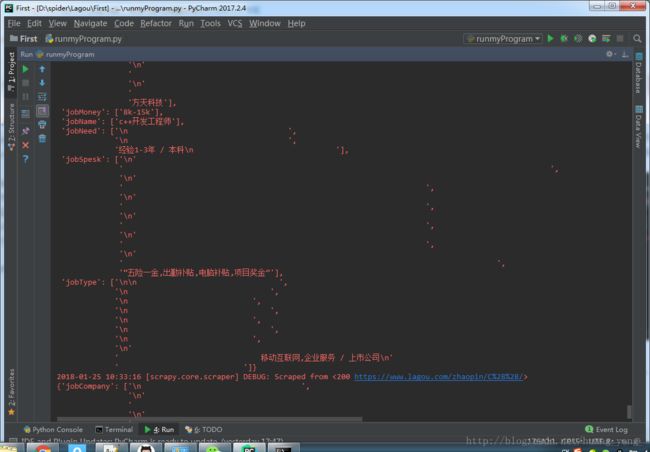
大概半分钟左右,执行结束,打开我们的json文件,在工程根目录下:

前半部分看起来正常,但是后半部分却多了很多换行符,我们需要对换行符进行处理,我们暂且选择strip的方法进行选取,之后再进行优化。
修改代码如下:
def parse_url(self,response):
for sel2 in response.xpath('//ul[@class="item_con_list"]/li'):
jobName = sel2.xpath('div/div/div/a/h3/text()').extract()
jobMoney = sel2.xpath('div/div/div/div/span/text()').extract()
jobNeed = sel2.xpath('div/div/div/div/text()').extract()
jobNeed = jobNeed[2].strip()
jobCompany = sel2.xpath('div/div/div/a/text()').extract()
jobCompany = jobCompany[3].strip()
jobType = sel2.xpath('div/div/div/text()').extract()
jobType = jobType[7].strip()
jobSpesk = sel2.xpath('div[@class="list_item_bot"]/div/text()').extract()
jobSpesk = jobSpesk[-1].strip()
Item = FirstItem()
Item["jobName"] = jobName
Item["jobMoney"] = jobMoney
Item["jobNeed"] = jobNeed
Item["jobCompany"] = jobCompany
Item["jobType"] = jobType
Item["jobSpesk"] = jobSpesk
yield Item
清空输出的json文件,重新运行爬虫:

问题解决。
项目基本完成,但是还有一个问题,我们这只是爬取到了每一种工作的第一页的数据,我们还需要换页。如图所示有30页,我们只爬取到了第一页

通过测试换页,我们可以发现页数的规律

第一页https://www.lagou.com/zhaopin/Java/
第二页https://www.lagou.com/zhaopin/Java/2
第三页https://www.lagou.com/zhaopin/Java/3
那就很简单了,我们只需要在jobUrl后面拼接1-30数字就可以了
修改代码如下:
def parse(self, response):
for item in response.xpath('//div[@class="menu_box"]/div/dl/dd/a'):
jobClass = item.xpath('text()').extract()
jobUrl = item.xpath("@href").extract_first()
oneItem = FirstItem()
oneItem["jobClass"] =jobClass
oneItem["jobUrl"] = jobUrl
for i in range(30):
jobUrl2 = jobUrl+str(i+1)
#print(jobUrl2)
try:
yield scrapy.Request(url=jobUrl2, cookies=self.cookie, callback=self.parse_url)
except:
pass
用jobUrl2接收拼接后的url,请求这个url,一共循环30次。
为了防止有的工作不是30页,我们将请求语句用try。。。except。。。包括,防止出现BUG(好粗暴)
再次运行爬虫,疯狂的爬取数据吧。我运行了13min,显示爬取到了77925条数据。
本篇算是学习笔记,参考这篇而来:http://blog.csdn.net/dangsh_/article/details/78587729
仅仅跑下来并不算什么,其中有很多知识点需要深究,框架的架构设计,各个模块的功能,都是需要熟悉的,另外还要举一反三,更加熟练的去使用工具解决问题,这才是技术的价值所在。加油吧!
github源码:https://github.com/hiliving/Scrapy-4Lagou/