高性能Excel操作工具
引
最近业务需要实现数据库导入导出Excel功能,我想这是个毫无难度的功能,就直接使用POI快速实现了该功能,谁知拿到测试部门傻眼了直接OOM。
囧大了,开发前没有问清楚数据量和应用场景,业务部门需要拉出交易流水对帐,而每月流水都有百万胜至千万级数据,由于POI会缓存到内存所以肯定OOM没跑。于是又换SAX版本POI实现试试,这次虽然不抛OOM但是速度太慢,一千万导出需要几个小时完全无法接受。
于是去万能的github上搜了一把,结果还真不少,有阿里的easyexcel但是看介绍依然是基于POI的SAX版本实现,找了好久发现一个叫EEC(Excel Export Core)的开源工具,由个人开发者提供,不使用POI实现。
引用EEC的介绍
eec(Excel Export Core)是一个Excel读取和写入工具,目前仅支持xlsx格式的导入导出。
与传统Excel操作不同之处在于eec执行导出的时候需要用户传入
java.sql.PreparedStatement或java.sql.ResultSet,取数据的过程在eec内部执行,边读取游标边写文件,省去了将数据拉取到内存的操作也降低了OOM的可能。eec并不是一个功能全面的excel操作工具类,它功能有限并不能用它来完全替代Apache POI,它最擅长的操作是表格处理。比如将数据库表导出为excel文档或者读取excel表格内容到Stream或数据库。
吸引我的优点在于EEC做excel导出时没有中间过程,直接将SQL传给EEC它就能边读数据库游标边写文件,取数据和写Excel行数据的复杂过程根本不用操心
下面我画了一下整个导出流程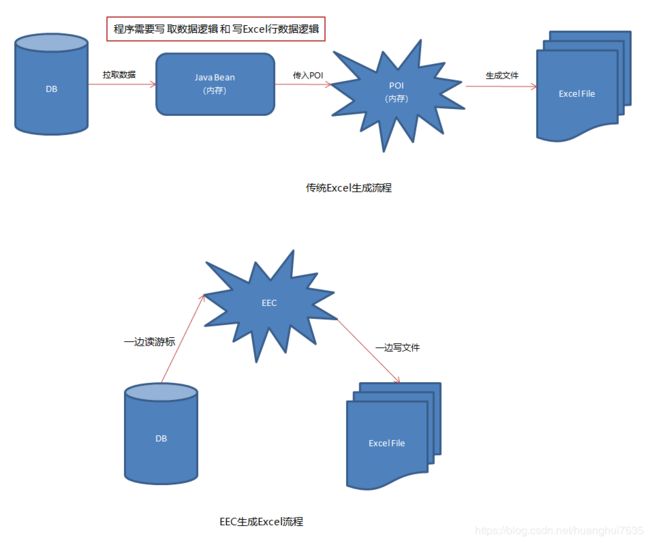
写Excel例子
EEC使用起来非常简单,只需要设置SQL语句和列头即可,是的,你没看错,这就是全部的代码。取数据的过程都省掉了
注:由于公司信息安全,我拿eec-example工程的表做测试例子
/* 产品列表 */
final String[] pros = {"", "LOL", "WOW", "极品飞车", "守望先锋", "怪物世界", "天堂", "斗地主", "炉石传说", "星际2", "魔兽世界", "LIMBO"};
/* 设置值是否共享 */
final boolean share = true;
try (Connection con = dataSource.getConnection()) {
new Workbook("用户充值", "左拖拖") // 设置文件名和作者
.setCompany("自定义公司名") // 设置公司
.setConnection(con) // 配置数据库连接
.setAutoSize(true) // 自动调整列宽
.addSheet("用户充值" // 添加一个Worksheet
, "select id, aid, pro_id, fill_amount, fill_time, use_flag from wh_fill limit ?"
, ps -> ps.setInt(1, 100) // 设定SQL参数,取前100行数据
, new Sheet.Column("ID", int.class)
, new Sheet.Column("AID", int.class)
, new Sheet.Column("产品ID", int.class, i -> pros[i], share) // 设置共享
, new Sheet.Column("充值金额", int.class)
.setType(Const.ColumnType.RMB) // 设置RMB样式
, new Sheet.Column("充值时间", Timestamp.class)
, new Sheet.Column("是否使用", boolean.class)
)
.writeTo(Paths.get("e:/export")); // 将excel文件写到e:/export目录
} catch (SQLException | IOException | ExportException e) {
e.printStackTrace();
}
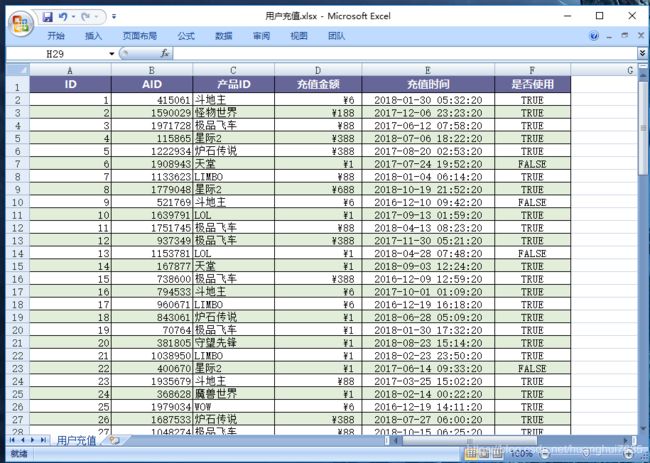
我们将得到如下Excel文件,EEC内部已经做了默认样式,有利于阅读.
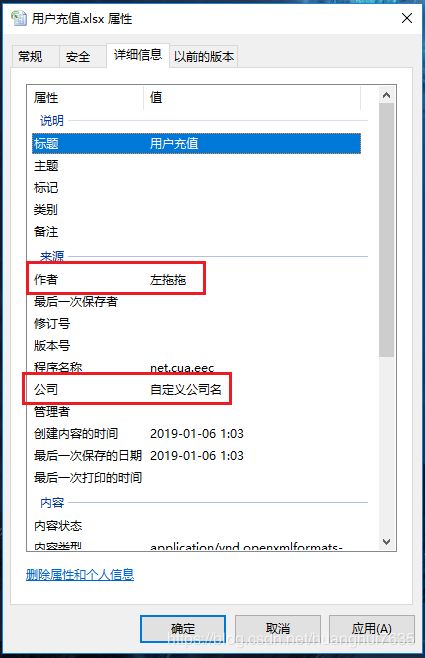
实例化Workbook时设置的 作者 和 公司 显示在文件属性里
详细简介一下上面那段代码的作用:
new Workbook("用户充值", creator)实例化Workbook并且设置Excel文件名和作者setCompany(company)设置公司名setConnection(con)设置数据库连接setAutoSize(true)设置列宽自动调节,也可以在Sheet.Column上使用setWidth()方法来指定某列宽度addSheet添加一个Worksheet,如果SQL抽取数据超过每页上限会自动分页writeTo将文件写到某个地方,也可以直接写到OutputStream中,如果是做Excel导出并下载的话这里可以直接使用writeTo(response.getOutputStream())
其中Sheet.Column还包含一些很强大的功能
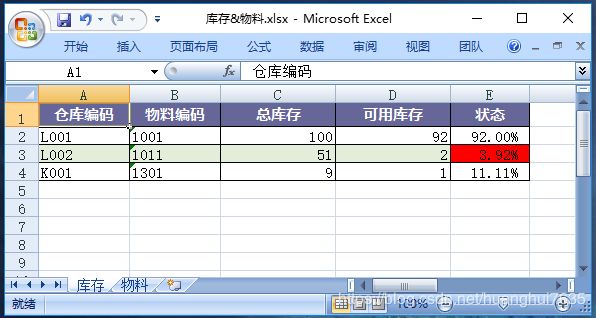
new Sheet.Column("产品ID", int.class, i -> pros[i], share)这里做了一个转换,数据库里保存的是数字型ID,i->pros[i]这一句将ID转换为游戏名,share是将该列的值进行分享,使得整个Excel中只会保存一份游戏名,实际应用中可以将重复率高的列设为共享。setType(Const.ColumnType.RMB)由于这列显示金额,所以我这里直接设置Type,内置样式还有PARENTAGE百分比显示。它的好处是仅设置样式而不会改变单元格的值,请看如下红框标识
下面展示一些更复杂的导出
try (Connection con = dataSource.getConnection()) {
boolean share = true;
// 红色填充
final Fill fill = new Fill(PatternType.solid, Color.red);
new Workbook("库存&物料", creator)
.setConnection(con)
.setAutoSize(true)
.addSheet("库存"
, "select `no`, goods_no, total, `accessible`, `accessible`/total as status from stock"
, new Sheet.Column("仓库编码", String.class)
, new Sheet.Column("物料编码", String.class)
, new Sheet.Column("总库存", int.class)
, new Sheet.Column("可用库存", int.class)
, new Sheet.Column("状态", double.class)
.setType(Const.ColumnType.PARENTAGE)
.setStyleProcessor((n, style, sst) -> {
if ((double) n < 0.100001) { // 低库存报警
style = Styles.clearFill(style) | sst.addFill(fill); // 标红
}
return style;
})
)
.addSheet("物料"
, "select `no`, `name`, short_name, category, supplier from goods"
, new Sheet.Column("物料编码", int.class)
, new Sheet.Column("物料名", String.class)
, new Sheet.Column("简称", String.class)
, new Sheet.Column("分类", String.class, share)
, new Sheet.Column("供应商", int.class)
)
.writeTo(defaultPath);
} catch (SQLException | IOException | ExportException e) {
e.printStackTrace();
}
上面我们实现了多个Worksheet导出,并且添加了高亮报警,当库存低于10%时高亮显示,这个功能非常强大,采购人员拉出Excel一下就知道哪些货架需要采购,实际生产过程中经常使用这个功能。
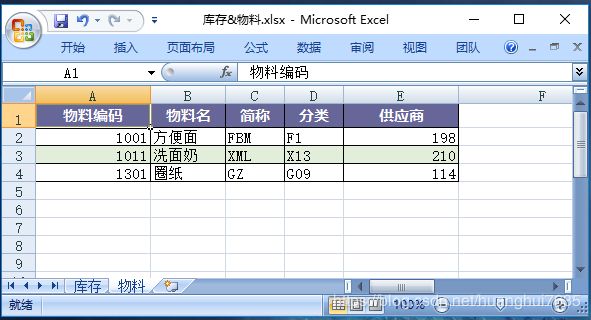
关键点:setStyleProcessor方法用于样式转换,三个参数(n, style, sst)分别表示当前值,当前样式,style实例,需要通过style实例添加新样式。
特别的:EEC将样式设计为一个int值,占用空间少,并且可以使用位运算,奈斯!!!
读取Excel例子
EEC读取Excel可以使用iterator迭代器或者java8的Stream,引用作者的描述
ExcelReader一个流式操作链,游标只会向前,所以不能反复操作同一个流。
同一个Sheet页内部Row对象是内存共享的,所以不要直接将Stream转为集合类,
如果要转为集合类可以使用Row对象内部的to方法row -> row.to(class)转为指定类型对象。
to方法会将每行数据实例化。
Row对象内部还包含一个too方法,用法与to方法一样,唯一区别是too方法返回的对象是内存共享的内存中只有一个实例,
对于流式操作,内存共享是一个好主意。
下面是读取的例子:
-
读取我们上面产生的〈用户充值.xlsx〉并且输出到控制台
ExcelReader.read(Paths.get("e:/export/用户充值.xlsx")).sheets().flatMap(Sheet::rows).forEach(System.out::println)
我们使用Jshell测试结果如下
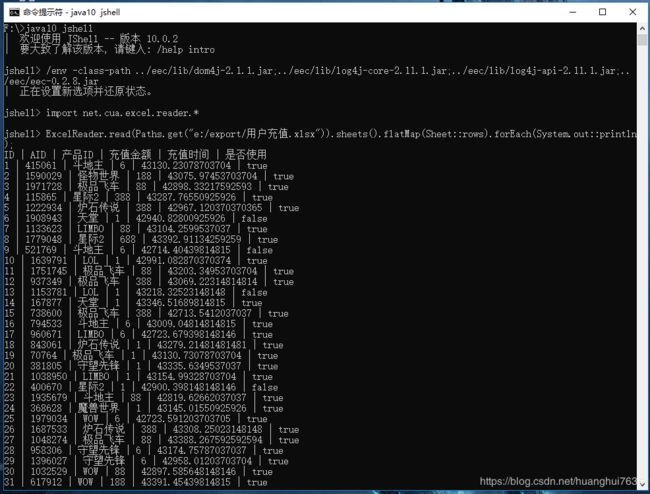
只需要一条语句就实现了Excel内容读取,图上的日期是一个double值,因为我们直接println出来的,并没有将其转为Timestamp。 -
读取多个Worksheet试试,正好我们上面的<库存&物料.xlsx>有两个Worksheet
ExcelReader.read(Paths.get("e:/export/库存&物料.xlsx")).sheets().flatMap(Sheet::rows).forEach(System.out::println)
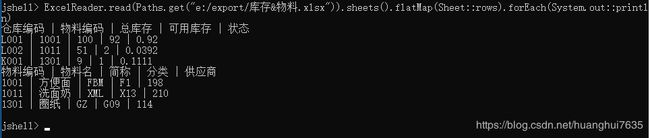
两个Worksheet数据均被读取出来了,当然还可以只读取某个Sheet页,使用下标或Sheet名指定,比如只读取“库存” ExcelReader.read(Paths.get("e:/export/库存&物料.xlsx")).sheet("库存").rows().forEach(System.out::println)
- 由于使用Stream所以就可以使用java8的所有lambda功能。下面展示只读取状态为正常的仓库信息,为了方便操作我们将行数据转为对象,先做准备工作编写Stock类
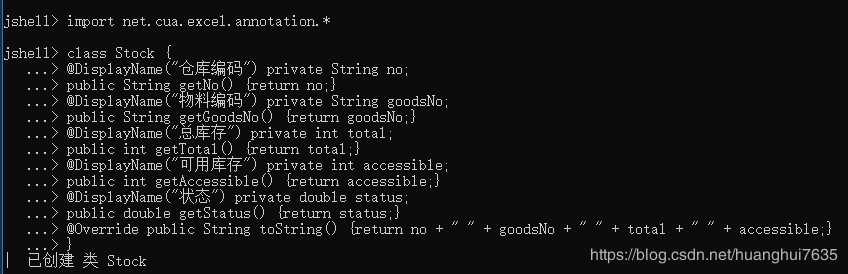
完成准备工作我们就写代码了,将一页数据进行过滤并转为对象数组
List list = ExcelReader.read(Paths.get("e:/export/库存&物料.xlsx"))
.sheet("库存")
.dataRows() // 所有数据列,会过滤掉表头
.map(row -> row.to(Stock.class)) // 列数据转Stock对象
.filter(s -> s.getStatus() > 0.10001) // 过滤掉库存小于10%的
.collect(Collectors.toList());// 转为对象数组

我们可以看到结果只有L001和K001两个货架,而L002是低库存所以被过滤了。
下面来一些刺激的例子:
我们将<库存&物料.xlsx>进行分裂处理如下
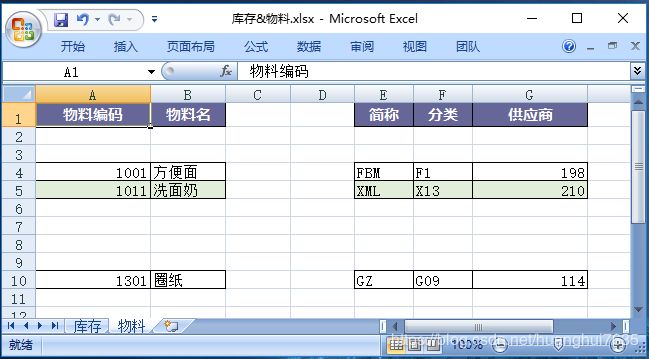
现在这个Excel文件被我们分裂成乱七八糟的,我们来试试ExcelReader能否正确读取行数据

奈斯!!!完全不影响
EEC的读取功能真的很强大,有兴趣可以去github上找作者写的更多例子。
性能
终于到最最关键的时刻了,EEC的性能到底怎么样,我测试时数据库在本地,大致的表格如下:
写性能(包含读库时间)
| 数据量 | 时间(Deflater) | 时间(7z) | 未压缩(MB) | 压缩后(MB) |
|---|---|---|---|---|
| 1W | 0.3s | 0.3s | 3.53 | 0.4 |
| 5W | 1s(±0.5) | 1s(±0.5) | 18.1 | 1.98 |
| 10W | 2s(±1) | 2s(±1) | 36.3 | 3.95 |
| 50W | 9s(±1) | 6s(±1) | 186 | 19.8 |
| 100W | 16s(±2) | 14s(±2) | 374 | 39.7 |
| 200W | 32s(±2) | 25s(±2) | 752 | 79.0 |
| 1000W | 1m40s(±5) | 1m8s(±2) | 2572.3 | 351 |
读性能(读上面写的文件,使用too方法转对象)
| 数据量 | 时间 |
|---|---|
| 1W | 0.5s(-) |
| 5W | 0.5s |
| 10W | 1s(-) |
| 50W | 3s(±1) |
| 100W | 5s(±1) |
| 200W | 10s(±1) |
| 1000W | 34s(±1) |
有木有很强大,1千万数据导出仅1分多钟,原来使用POI导出要几个小时。。。几个小时到1分钟这是个巨大飞跃,这也是我们现在项目中大量使用EEC做为Excel操作工具的原因。
最后
EEC目前还是个人开发者提供,最新版本0.2.8更新于2018年11月,虽然不是很稳定但是很多设计理念还是很强大的,尤其是导出时的值转换和样式转换,读取时的流式处理,发展潜力还是非常巨大的。