嵌入式数据库BERKELEY DB 之dubbo实战
berkeley db 时oracle旗下的一款嵌入式数据库。。。当然,在互联网业界,他并不火,但是它确实很省内存,,对于一些想要替换redis的解决方案--可以考虑。。想要学习它。甚至在一些主流的网站上看不到它的相关资料。。。此时我们可以结合官网来进行学习和实践。本文集合dubbo+berkeley 来阐述下小编的实战以及需要注意的问题。。。。
1.Berkeley DB简介
Berkeley DB是一个开源的文件数据库,介于关系数据库与内存数据库之间,使用方式与内存数据库类似,它提供的是一系列直接访问数据库的函数,而不是像关系数据库那样需要网络通讯、SQL解析等步骤。它是一个嵌入式数据库系统,其设计思想是简单、小巧、可靠、高性能。可以和Java, C++, Python..以及其他很多语言都有绑定。可以保存任意类型的键/值对,而且可以为一个键保存多个数据。Berkeley DB可以支持数千的并发线程同时操作数据库,支持最大256TB的数据
数据结构
Berkeley DB以拥有比SQLServer和Mysql等数据库系统而言更简单的体系结构。它是通过进程内的API访问数据库。不支持表结构和数据列。访问数据库的程序自主决定数据如果存储在记录里。每个记录只有两部分:键、值,所以通常用key/data pair指代一个记录。记录和它的键都可以达到4G字节的长度。
支持ACID数据库事务处理,细粒度锁,热备份以及同步复制。
支持HASH、Recno、QUEUE、B+Tree 4种算法
B+树算法
B+树是一个平衡树,关键字有序存储,并且其结构能随数据的插入和删除进行动态调整。为了代码的简单,DB没有实现对关键字的前缀码压缩。B+树支持对数据查询、插入、删除的常数级速度。关键字可以为任意的数据结构.
HASH算法
DB中实际使用的是扩展线性HASH算法(extended linear hashing),可以根据HASH表的增长进行适当的调整。关键字可以为任意的数据结构。要求每一个记录都有一个逻辑纪录号,逻辑纪录号由算法本身生成。
RECNO算法
Recno建立在B+树算法之上,提供了一个存储有序数据的接口。记录的长度可以为定长或不定长。
Queue算法
Queue算法只能存储定长的记录,在高的并发处理情况下,Queue算法效率较高;如果是其它情况,则选择Recno算法,Recno算法把数据存储为平面文件格式。和Recno方式接近, 只不过记录的长度为定长。数据以定长记录方式存储在队列中,插入操作把记录插入到队列的尾部,相比之下插入速度是最快的。
对算法的选择首先要看关键字的类型,如果为复杂类型,则只能选择B+树或HASH算法,如果关键字为逻辑记录号,则应该选择Recno或Queue算法。当工作集关键字有序时,B+树算法比较合适;如果工作集比较大且基本上关键字为随机分布时,选择HASH算法。
特点
访问速度快、省硬盘空间Berkeley DB可以轻松支持上千个线程同时访问数据库,支持多进程、事务等特性。Berkeley DB运行在大多数的操作系统中,例如大多数的UNIX系统, 和windows系统,以及实时操作系统。
Berkeley DB 还拥有对一些老的UNIX数据库,例如dbm, ndbm und hsearch的兼容接口.
对于在java系统中的使用,Berkeley DB提供了一个压缩成jar单个文件的java版本。 这个版本可以运行在java虚拟机上使用,并且拥有和C语言版本相同的所有操作和功能。
Berkeley DB只支持单一的数据结构,它的所有数据包括两个部分:key 和 data.
Berkeley DB原则上是为嵌入式数据库设计的。
2.JE - Java Edition
Berkeley DB Java Edition (JE)是一个完全用JAVA写的, 提供DB操作的API集合
Environment 相当于一个磁盘上的目录路径,你可以用nvironments找到所有的文件也可以用于管理资源,比如事务。当用一个Environment对象实例打开DB,你的环境实例也可以叫做环境句柄.每次访问、
每次存储、访问数据都需要打开environment, 在你使用完后需要关闭。
Database environments. Database environments provide a unit of encapsulation and management for one or more databases.
Environment myDbEnv;
EnvironmentConfig envConfig = new EnvironmentConfig();
envConfig.setAllowCreate(true);
myDbEnv = new Environment(new File("/export/dbEnv"), envConfig);
In-memory cache:
你需要谨慎的考虑设置多大的cahce. 如果你设置的太低,将会产生一些不必要的磁盘访问导致性能下降,如果你设置的太高,可能会浪费本地内存。
注意这个in-memory的最大size设置,在项目启动的时候,这个缓存将会非常小,一般是最大设置的7%被允许缓存数据。后面会根据你程序的操作增长。
这个缓存不是固定的存在内存中,它可能会被你的系统虚拟内存系统移出内存页。
CacheMode:
DEFAULT
The record's hotness is changed to "most recently used" by the operation where this cache mode is specified.
EVICT_BIN
The record LN (leaf node) and its parent BIN (bottom internal node) are evicted as soon as possible after the operation where this cache mode is specified.
EVICT_LN
The record LN (leaf node) is evicted as soon as possible after the operation where this cache mode is specified.
KEEP_HOT
The record is assigned "maximum hotness" by the operation where this cache mode is specified.
MAKE_COLD
The record is assigned "maximum coldness" by the operation where this cache mode is specified.
UNCHANGED
The record's hotness or coldness is unchanged by the operation where this cache mode is specified.
两种API用来提供操作数据库:
DPL - Direct Persistence Layer (DPL)API 提供JAVA原始的数据类型直接存入DB, 也可以序列化复杂的JAVA对象
lower-level JE APIs 可以提供put, get方法。用来获取数据。
数据存储结构:
Key-Data Pairs
DB默认不允许重复的数据,当同样的KEY+value插入的时候,会用新插入的这条替换原来存在的那条数据。
重复的KEY可以通过配置实现,
如果多条数据的key, 默认值会取第一次插入的那条,除非用游标把这个key下面的全部数据都取出来。
Secondary Keys:
提供一个选择去定位信息。通常是引用超过一条数据的case,你可以在存储汽车的DB中用SK来表示车的颜色或其他。
3.BDB环境配置参数
环境配置
{
"envHome":"/opt/data/bdb",
"databaseName":"cache",
"permissibleLag":"1",
"electableGroupSize":"1",
"permissibleTimeout":"3600",
"ackTimeout":"5",
"maxMemoryPercent":"60",
"maxDiskGB":"140",
"TTLHour":"72",
"groups":[
{
"groupName":"pg1",
"port":"5000",
"nodes":[
{
"nodeName":"n183",
"ip":"10.1.10.1",
"helperHostPort":"10.1.10.1:5000"
},
{
"nodeName":"n183s",
"ip":"10.1.10.2",
"helperHostPort":"10.1.10.1:5000"
}
]
}
]
}
envHome:Environment目录地址
databaseName:数据库名
permissibleLag:定义master-slave同步时间
permissibleTimeout:定义同步超时时间
electableGroupSize: 可选举的组内节点数
ackTimeout:从节点确认超时时间
maxMemoryPercent:使用内存的最大百分比
maxDiskGB:最大磁盘存储容量GB
TTLHour:数据过期时间
Groups:集群组
groupName:集群组名
port: 默认端口
nodes: 集群内的节点
nodeName:节点名称
ip: 节点IP
helperHostPort:主从节点通信的IP和端口
4.bdb基于虚拟机高可用方案
- 服务发现&治理
dubbo现有的服务发现框架,集合虚拟机上部署的全部机器,包括机器的IP、端口、状态。可以对单台BDB虚拟机进行拉入拉出。同时对2个IDC的机器进行一对一分组。默认先发布的为master。
监听服务在BDB服务发布后开始分别对每个cluster进行监听,任何的BDB机器被拉出或者挂掉重启,都自动更新机器的主从状态到服务列表中。
- 服务路由
对两个机房所有机器可见
- 负载均衡,
对请求的key进行MD5加密后取HashCode, 使其命中服务列表中的某一个cluster。获取cluster内机器的状态,写请求只读取master机器,读请求会根据2:8的权重规则随机命中master和slaver节点
- 主从同步策略
写入主机器后,会在1S内复制分发到从机器。同时一致率控制在cluster集群内一半机器成功,则认为此次插入成功。
- 集群容错
写入master节点使用Failfast, 写请求只会执行一次,失败后立即抛出异常。
读取采用Failfast ,读请求只会执行一次,失败后立即抛出异常。
集群环境如下:

5 berkeley db 服务监控
第三方监控服务:
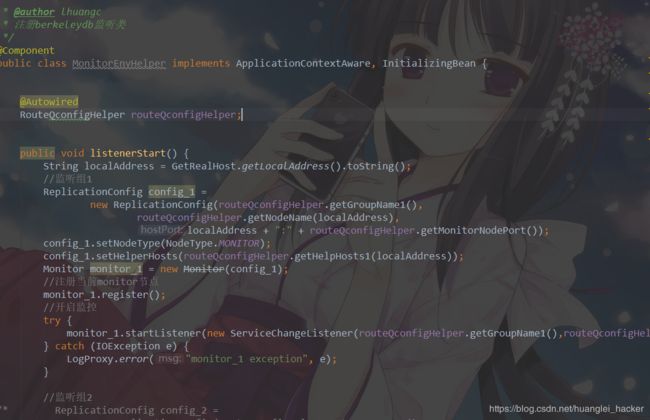
新启动一个app ,名为route。根据下面代码来启动一个监听程序。根据监听的结果来对集群内的所有机器的状态进行动态维护。维护好的节点数据需要存储起来以提供给客户端使用。
// 监控配置
MonitorConfig monConfig = new MonitorConfig();
// 监控节点名
monConfig.setNodeName(repConfig.getNodeName());
// 集群组名
monConfig.setGroupName(repConfig.getGroupName());
// 监控节点的IP+端口
monConfig.setNodeHostPort(repConfig.getNodeHostPort());
// 需要监控的服务IP+端口
monConfig.setHelperHosts(repConfig.getHelperHosts());
Monitor monitor = new Monitor(monConfig);
// 获取集群内的master节点信息
ReplicationNode master = monitor.register();
// 注册服务状态变更监听类
monitor.startListener(new RouterChangeListener());
// 监听类
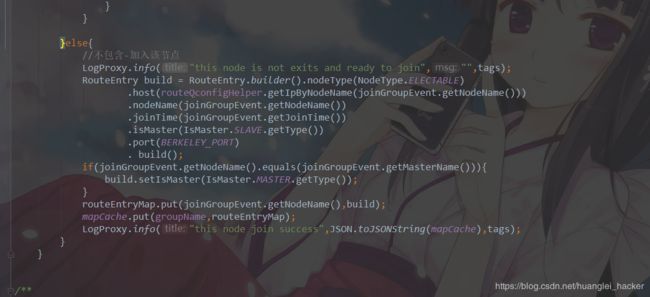
class RouterChangeListener implements MonitorChangeListener {
// 新主节点通知public void notify(NewMasterEvent newMasterEvent)
// group信息变更通知public void notify(GroupChangeEvent groupChangeEvent)
// 新节点加入group通知public void notify(JoinGroupEvent event)
// 离开group通知public void notify(LeaveGroupEvent event)
}
6.异常分类
场景
我们的缓存在生产环境中会遇到网络故障,或者机器宕机等情况,当发生上述现象的时候程序依然要可以正常提供服务。高可用就是在这种场景下发挥作用。使得服务不受单边机房或者单台机器的影响。
主从切换:
一般的缓存场景下,高可用可以使用一主一从。配置好helperHost后可以指定某一个IP+端口来用于主从数据流同步。主和从分别部署到OY\RB两个不同的机房,在第一次启动某一个机房的一个节点后,会自动成为主。另外一个机房的节点则变为从。当你下次发布或者网络异常的时候。会根据environment.state的状态来决定当前节点是否主从。
异常情况:
从节点出现异常
当group中的从节点出现异常的时候,我们的客户端在发起读请求的时候,如果命中的是这个读节点,会报出healthcheck failure. 从而集群中的主节点会继续提供20%的读功能。当从节点回复后。会继续同步主节点的数据到从节点。从而继续提供服务。
主节点出现异常
当主节点出现异常。客户端发起写请求会失败,同时服务监控程序会动态修改主节点的IP地址,这个时候写入请求会自动迁移到新的主节点上。当老主节点起来后,会自动变为从节点。而客户端也会刷新读/写节点的IP地址。下次发起请求的时候根据新的节点状态来请求IP上的服务。
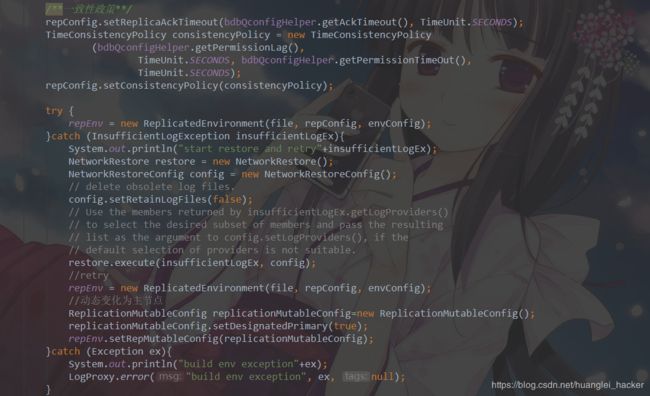
从节点出现异常比较久,数据checkpoint已经远落后master节点
这种情况会抛出一个InsufficientLogException, 这时需要采用一个机制让slave节点的数据与master保持一致。不能使用正常的数据流自动同步。使用NetworkRestore.execute()会让slave节点从master上复制缺失的logfile. 一旦slave节点同步好了必须的log文件,它会自动的重新恢复原来的同步流。
try {
node = new ReplicatedEnvironment(envDir, repConfig, envConfig);
} catch (InsufficientLogException insufficientLogEx) {
NetworkRestore restore = new NetworkRestore();
NetworkRestoreConfig config = new NetworkRestoreConfig();
config.setRetainLogFiles(false); // delete obsolete log files.
// Use the members returned by insufficientLogEx.getLogProviders()
// to select the desired subset of members and pass the resulting
// list as the argument to config.setLogProviders(), if the
// default selection of providers is not suitable.
restore.execute(insufficientLogEx, config);
// retry
node = new ReplicatedEnvironment(envDir, repConfig, envConfig);
} ...
7 日志文件
启动BDB环境后,会在对应目录下出现这几种文件。
je.stat.csv: 环境状态文件
je.config.csv: 环境配置文件,每一次更新配置都会产生一条新的纪录
je.lck: 锁文件,当设置写/读访问权限到JE环境目录的时候,会创建lck文件同时写入一些标记到其中。
00000001.jdb: 数据文件,是一个8位的16进制数字,从1开始增长。可以通过配置je.log.fileMax属性来设置一个文件的最大容量
8 基于dubbo实现berkeley db代码实现
需要注意的是,客户端需要扩展dubbo的cluster,将dubbo自带的负载均衡打破,扩展cluster 实现自己的负载策略。。。
服务端代码:
1.引入je jar包

2.初始化环境



3. 提供接口

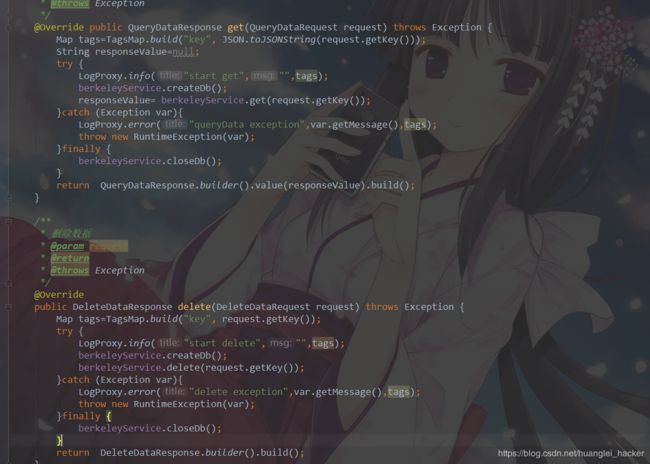
路由端代码:
1.监控部分:



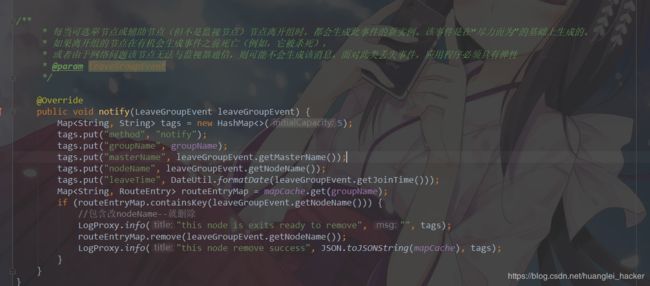
2.dubbo SPI 部分扩展



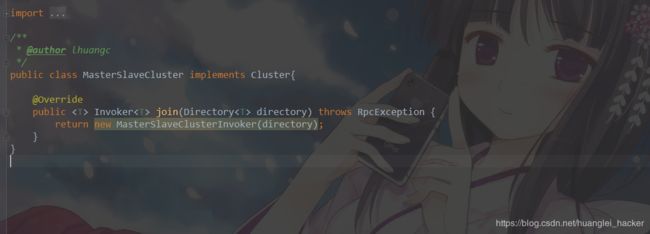

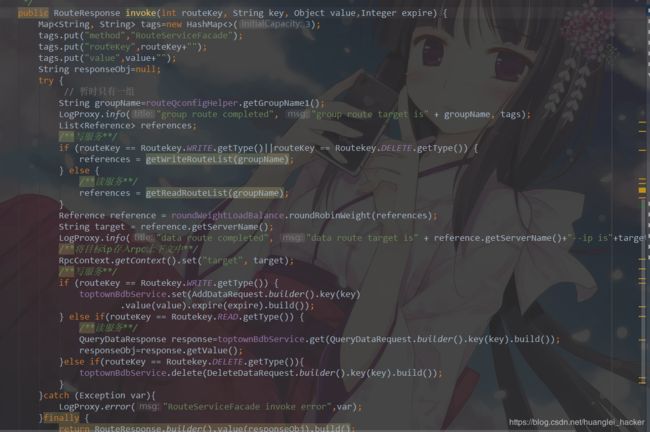
3.路由负载部分

高能注意:
1.不管是monitor node还是data node,名称一定不要带特殊符号例如 : xxmonitor-1 ,这种会报错,小编踩过很多坑 ,,,最好xxmonitor1 这种就好了。。。
2.基于docker的存储不能存储文件,需要用虚拟机或者物理机