高性能计算系统——大数据/快速数据分析中的高性能技术
大数据/快速数据分析中的高性能技术
高性能计算的目的是为了数据密集型以及处理密集型的工作实现少费而多用的目标。计算机、存储设备和网络解决方案也相应变得高性能和可扩展。
高通量计算(HTC)同高性能计算(HPC)存在很多不同之处。HPC任务的特点是在较短的时间内需要大量计算能力,而HTC任务也需要大量的计算,但可以在更长的时间内完成。HPC环境通常通过每秒浮点操作次数(FLOP)来衡量。而HTC更关注在较长的一段时间内能够完成多少任务。
适合HPC的领域有很多,例如气象模拟、金融服务、科学计算、大数据分析(BDA)、电子设计自动化(EDA)、计算机辅助工程(CAE)、油气勘探、新药研制、DNA测序与同源性搜索、蒙特卡洛模拟、计算流体力学(CFD)、结构分析等。
大数据科学
错综复杂的大数据范型
- 数据量变得更大,范围涵盖TB、PB和EB级
- 数据生成、获取、处理频度大幅度增加(速度从批处理到实时处理)
- 数据结构变得多样性,包括poly-structured(多数据)数据。
大数据的主要驱动力
- 通过前沿技术实现数字化
- 分布与联合
- 消费级(手机及穿戴设备)
- 集中化、商品化、产业化(云计算)
- 泛在网、自治网、同一通信网和自组网
- 服务范型(服务支持RESTful API)
- 社交计算以及无处不在的传感、视觉、感知。
- 知识工程
- 物联网
大数据分析的挑战
由于大数据的规模性、变化性、多样性、粘性、真实性、对IT带来了巨大的挑战。大数据要求高质量的IT基础设施、平台、数据库、中间件解决方案、文件系统、工具等。
基础设施面临的挑战
- 用于数据捕获、传输、提取、清洗、存储、预处理、管理、知识传播的计算、存储、网络单元。
- 集群、网络、云、大型机、设备、并行及超级计算机等。
- 为高效满足大数据需求而专门设计、巧妙集成的系统。
平台面临的挑战
- 可分析、分布式、可扩展、并行的数据库
- 企业数据仓库(EDW)
- in-memory系统和网格(SAP HANA、VoltDB等)
- in-database系统(SAS、IBM Netezza等)
- 高性能Hadoop实现(Cloudera、MapR、HortonWorks等)
文件系统及数据库面临的挑战
在意识到传统数据库用于大数据的缺点之后,产品供应商推出一些可分析、可扩展、并行的SQL数据库来处理高度复杂的大数据。此外,还有NoSQL和NewSQL数据库,它们更适合处理大数据。新型的并行及分布式文件系统,如NetApp的Lustre等。为大数据增加了很多新的功能,
高性能计算范型
应用程序直接在云环境中构建和部署、以便消除开发环境和运行环境之间标准上的冲突,用这种方式编写的应用程序天然适合云环境。
有一些方法可是使应用程序的性能大幅提升,包括自动容量规划、成熟的提升性能的工程和增强机制、自动扩展、增强性能的架构模式、动态负载均衡与存储缓存、CPU突发等。高性能计算是指能够每秒处理超过 1 0 12 10^{12} 1012次浮点操作的系统。
通过并行实现高性能的方法
使用额外的硬件完成并行工作的主要方法:
- 共享内存
- 共享磁盘
- 无共享
共享内存
对称多处理计算机是广泛使用的共享内存计算机。所有的CPU共享一个内存以及一组磁盘,这里面临的复杂问题是分布式锁。由于锁管理以及内存池都是内存系统中,因此不需要任何提交协议,所有处理器都能以受控的方式访问内存。
共享内存多处理器要求复杂的、定制的硬件,以确保它们的L2数据缓存的一致性。因此,共享内存对各种不同的需要难以进行扩展。
共享磁盘
在这种架构下,会有多个独立处理器节点,每个节点有其专有内存。但是这些节点都访问同一个磁盘集合,通常以SAN(存储区域网络)系统或NAS(网络附属存储)系统的形式存在。同共享内存类似,共享磁盘结构也面临严重的可扩展问题。将各个CPU连接到共享磁盘的网络可能会成为I/O瓶颈。为了设置锁,锁管理模块必须集中到一个处理器或使用一套复杂的分布式锁协议。该协议必须使用消息来实现缓存一致性协议,这类似于共性内存多处理器用硬件实现的协议。
这样的机制非常适合于在线事务处理(OLTP),但是对于数据仓库、联机分析处理(OLAP),这种设置就不要好了。
无共享
每个处理器都有自己的磁盘组,相互之间不共享任何关键计算资源,对于大数据而言,数据被水平分布到多个节点上,使得每个节点都有来自数据库中每个表的子集,然后每个节点只负责位于它自身磁盘当中的行。每个节点都维护自身的锁表和缓存池,因此完全不需要复杂的加锁操作以及软件或硬件的一致性机制。
集群计算
集群越来越普及,因为它不仅能够实现高性能的目标,还具有可扩展性、可用性、可持续性。除了提供成本效益外,集群易于搭建也是值得注意的一点。
集群通常遵从MPP模型,其主要的缺点就是集群中每个结点都有自己的内存空间,其他节点需要通过系统互连才能访问它们。结果就是增加了软件开发的复杂性,也就是需要将应用程序的数据进行分割,然后分布到集群中,在通过节点间消息传递来对计算进行协调。
SMP平台实现了共享内存模型,系统中所有处理器对整个地址空间进行统一访问。这是通过使用支持NUMA的通信架构来将多个处理及其相应内存聚合到一个节点访问来实现的,这意味着不需要切分应用程序并协调分布式计算。系统只需要一个OS实例及软件环境,从而简化了系统升级和补丁。
大数据集群的优点包括:
- 集群具有较低的购置成本,并且还可以重用已有硬件
- 易于对集群进行扩展,可以混合使用高端硬件作为管理节点,商用硬件作为工作节点。
- 能够快速改变硬件的配置,以便符合工作负载的特殊要求
虚拟SMP代替方案
将SMP的独立能力嵌入集群中,同时对SMP的不足也加以高度重视,如果SMP也能够运行为分布式内存架构构件的MPI应用程序,同时不需要传统集群的管理开销,这对于SMP而言也非常有利的。ScaleMP推出了一款新的产品,该产品反映了ScaleMP的价值主张,其vSMP Foundation(Versatile SMP)产品将传统的x86集群转换为一个共享内存的平台。当前的vSMP Foundation 产品能够将多达128个节点、32768个CPU以及256TB内存聚合在一个系统中。
vSMP Foundation为分布式基础设施创建了一个虚拟共享内存系统,这即适用于大数据、也适合分析问题。它允许通过增加节点的方式来进行扩展,同时保留了共享内存的OPEX优点。
Hadoop集群的提高
Hadoop集群是一个开源的框架,用来在由多个异构商用服务器组成的计算集群中运行数据密集型应用程序。Hadoop传感器采用了很多先进进制,用于提高扩展性、可用性、安全性、容错性等。通过额外的和外部引入的技术,自动扩和收缩正在实现。
Hadoop可以有效分布大量数据处理任务,范围从几台到2000多台服务器,一个小规模的Hadoop集群可以轻易的处理TB级别乃至PB级别的数据。
Hadoop高效进行数据分析的步骤如下
- 数据加载及分发:输入数据保存在多个文件中,因此一个Hadoop作业的并行规模是同输入文件的数量相关的。Hadoop调度器将作业指定到节点上来处理文件。当作业结束后,调度器会指派另一个作业以及相应的数据到节点上,作业的数据可以存储到本地存储中,或者位于网络上的另一个节点。节点会处于空闲中,直到收到待处理的数据为止。对数据集进行分发以及高速数据中心网络都会对Hadoop处理集群的性能有贡献。
- Map/Reduce:第一个数据处理步骤将map函数应用到步骤1中加载数据上,之后,map函数的中间输出使用一些键(key)来进行划分,具有相同键的数据被移动到相同的reducer节点。最后的步骤是讲一个reduce函数应用到中间数据上,而且reduce函数的输出会存回到磁盘中。在两个关键步骤之间,可会还会有很多其他任务,例如shuffling、filtering、tunnelling、funnelling等。
- 合并:当数据进行map和reduce处理之后,必须合并处理后进行数据和提供报表。
网格计算
网格计算被定义为一种非常强大的HPC范型,网格遵从了分布式计算的理念,真正的优点不是服务器的分布式部署,而是集中式的监视、度量和管理。计算网格使得你可以在分布式计算机的处理器、存储器、内存之间无缝建立连接,以提高它们的利用率,以便更快速地解决大规模问题。
网格计算是一种可扩展的计算环境,可以用低成本高效益的方式确保可扩展性、高可用性和快速处理。网格计算利用分而治之的方法,从而出色满足HPC的需求。各种可并行的工作负载以及数据都可以通过该计算范型而受益。
明显的优点是:
- 可扩展性:大数据集可以被精确地分割成数据子集,这些都可以同时执行,从而加快执行过程。
- 用户增长:多个用户可以访问虚拟资源池,目的是通过对计算资源的最大化利用来提供最短的响应时间。
- 节约成本:利用网络中未使用或没有充分使用的计算机。
- 业务敏捷性:网络计算显著增加了IT敏捷性,从而提高了业务敏捷性。
- 高度自动化:随着网格环境中实现和集成了强大的算法,管理网络程序与平台的自动化程序被提升到一个新的水平。
网络提供了典型的工作负载管理,作业调度与优先级、分析作业的细分、以获得更高的生产率。网格计算可以解析和划分大型分析作业,将其分为更小的任务,这些任务可以并行运行在小的、低成本的高收益的服务器上,而不是高端和昂贵的对称多处理器(SMP)系统上。
in-memory 数据网格(IMDG)
尽管Hadoop并行架构可以加速大数据分析,但是当应对快速变化的数据是,Hadoop的批处理和磁盘开销过大。我们可以将IMDG和一个集成独立的MapReduce执行引擎结合。实现实时且高性能的分析。IMDG提供了低延迟、可扩展能力、高吞吐量以及集成的高可用性。IMDG自动存储并将数据进行负载均衡,分布到弹性的服务器集群中。IMDG也将数据在多个服务器上进行冗余存储,以便在服务器或网络连接失败的时候保证高可用。
IMDG需要灵活的存储机制来处理它们存储的数据上的各种不用的要求。IMDG可以保存有着丰富语义的复杂对象,从而支持类似面向属性的查询、依赖、超时、悲观锁、远程IMDG同步访问等特性。将MapReduce引擎集中到IMDG中,大幅降低了分析和响应时间,因为能够咋处理中避免数据的移动。先进的IMDG示范并行计算能力,能够克服MapReduce引入的很多限制,而且能够对MapReduce的语义进行仿真和优化。
将IMDG用于实时分析
第一个步骤就是消除Hadoop标准批处理调度器的批处理调度开销,IMDG可以所有网格服务器上预设基于Java的执行环境,用于各种分析中。这个执行环境包含一组Java虚拟机(JVM)。集群中每个节点上部署一台虚拟机和一个网格服务进程。这些JVM构成了IMDG的MapReduce引擎。IMDG可以自动部署所有必须的可执行程序和库,从而支持这些JVM间执行MapReduce,将启动时间大幅度降低到几毫秒。
下一个减少MapReduce分析时间步骤是尽可能消除数据移动。由于IMDG将快速变化的数据放在内存中,MapReduce应用程序可以直接从网格中获取数据,然后将结果放回到网格中,IMDG中的键/值可以高效读取到执行引擎中,从而减低访问时间。
in-memory数据网络非常流行,解决了两个相关的挑战
- 为实时用途访问大数据
- 应用程序性能与规模
一个巧妙的解决方案
- 确保数据已经位于易于访问的内存中,in-memory数据网格提升了极快的、可扩展的读写性能。
- 自动将未使用的数据保存到文件系统中,维护冗余in-memory节点以确保高可用性和容错性。
- 弹性地维护分布式节点上下线
- 自动在整个集群中分布信息,当扩展或需要改变性能需求时,网格能够增长。
GridGain是基于JVM的应用中间件、可以容易地构建高可扩展的实时、数据密集分布应用程序,这些程序可以在各种基础设施上运行,从小的本地集群到大型混合云。
GridGain提供了一个中间件解决方案
- 计算网格
- in-memory数据网格
计算网格
计算网格为处理逻辑的分布提供了方法,它支持计算在多个计算机上进行并行化。计算网格或MapReduce类型的处理定义了将最初的计算机任务分割成多个子任务的方法,然后在基础设施上并行执行这些子任务,并将子结果聚合得到一个最终的结果。
云计算
云范型是不断增加的实用技术和技巧的集合,例如整合、集中化、虚拟化、自动化、共享各种IT资源(计算机、存储设备、网络解决方案),从而获得良好组织和优化的IT环境。
最近引入的API支持的硬件可编程性,目的是能够在任何网络上激活硬件元素,意味着硬件元素的远程可发现性、可访问性、可操作性、可管理性、可维护性正在推动,从而提高他们的可用性和利用水平。
云环境中的可扩展性
当云作为一种技术开始改变IT行业时,其核心就是IT基础设施,按需启动虚拟机就像社会公共事业(天然气、电力、水)那样。
垂直扩展需要向相同的计算池中增加更多的资源、例如更多的RAM、磁盘或者虚拟CPU来处理增加的应用负载。水平扩展需要为计算平台提供更多的计算机或设备来处理增加的需求。
云中的大数据分析
随着数据变成大数据,洞见也必然变得更多,所以未来的任务应用都必由大数据来驱动。考虑到处理的数据十分的庞大,企业渴望具有并行分析处理能力以及可扩展的基础设施,该基础设施能够快速适应计算机或存储需求的增加或减少。
高性能云环境
云环境的真正优点在于自动扩展,除了向上和向下的扩展之外,向外和向内的扩展才是云的关键。自动增加新的资源或撤销已分配资源以满足变化的需求的能力,使得云称为最合适低成本高收益的HPC的选择。任何并行工作负载都能够在云中有效解决。
并行文件系统、scale-out存储、SQL、NoSQL、NewSQL数据库等使得云基础设施成为下一代的HPC解决方案。通过应用成熟的云计算来建立HPC和分析基础设施,能够避免各自为战,可以利用共享资源来使用现有集群的运行效率最大化。
用于HPC的云平台
实时并行计算并行平台主要有IBM Netezza、SAP HANA、SAS High-Performance Analysis。
IBM Netezza的一个实例被放在公有云环境中,目的是通过测试来了解它如何在云环境中发挥功能。
异构计算
异构计算是一种实现加速计算的目标的可行机制,是指系统使用多种不同计算单元、例如通过处理器和专门处理器(数字信号处理器DSP、图形处理单元GPU、现场可编程门阵列FPGA实现的专用电路)。GPU是众核架构,有多个SIMD多处理器(SM),可以并发运行上千个线程。专用集成电路(ASIC)是另一种专用电路。
设计GPU集群
由于单核CPU性能停滞不前,目前已经进入了多核计算的时代。最近人们开始逐步采用GPU,GPU的价值和激增,各种各样的应用在性能和性价比方面体现出了数量级的收益。GPU尤其擅长面向吞吐量的工作负载,这些工作负载都是数据密集或计算密集特征的应用。
目前利用GPU集群来解决大规模问题的还不多,同MapReduce一样,GPU在并行处理数据方面表现比较哈,但是目前的GPU MapReduce仅针对单个GPU,而且仅能采用in-core算法。主要的挑战为
- 多GPU通信非常难,因为GPU无法发起或汇集网络I/O,因此支持多个GPU的动态高效通信非常困难
- GPU没有内在核外支持以及虚拟内存
- 简单GPU MapReduce 实现抽象了GPU计算资源和可能的优化
- MapReduce模型不显示支持GPU固有的系统架构。
用于大数据分析的异构计算
通过高效利用CPU核、GPU核、多GPU来改进MapReduce性能。但是这些新的MapReduce的目的并不是有效利用异构处理器,例如一组CPU和GPU。
Moim
多GPUMapReduce框架:MapReduce运行时会以透明的方式处理数据分析、调度、容错等问题。但是MapReduce也有一些局限性。但是它的设计中并没有利用异构并行处理器提供的节点内运行。例如多核CPU和GPU。还有其他问题,在MapReduce中,作业的中间结果对要根据基于键的哈希机制移动到一个或多个reducer中,但是这种方法可能会导致作业的reducer之间严重的负载失衡。
为此作者1设置了一个新的MapReduce框架,命名为Moim,他主要克服上面的缺点的同时,还提供了很多新的功能。
- Moim有效利用多核CPU和GPU提供的并行性
- 尽可能多的重叠CPU和GPU计算,以便降低端到端的延迟
- 支持MapReduce作业的reducer和mapper间的高效负载均衡
- 整个系统被设计为可以处理固定大小的数据,可以处理变动大小的数据
云中的异构计算
如今由于完全符合异构计算规范的芯片组和其他加速方案进入市场,异构计算与云计算的结合正在成为一种强大的新范型,它能够满足HPC需求的重要一步。Intel Xeon Phi协处理器是异构计算的突破口,提供卓越的吞吐量和能效。
通过Nimbix Cloud 实现基于云的异构计算
Nimbix推出了世界上第一个Accelerated Compute Cloud 基础设施。之后,又推出JARVICE(Just Applications Running Vigorously in a Cloud Environment),这是一个集中式平台技术,开发目的是以最低成本更快运行应用程序。
IBM发起的OpenPOWER基本会联盟已经有很多的组织参数与,目的是使得POWER架构得以普及并更具有影响力。
用于高性能计算的大型机
操作系统使用符号名,使得用户能够动态部署或重新部署虚拟机、磁盘卷以及其他资源,使得常见硬件资源在多个项目中共享使用变得非常简单。多个这样的系统可以混合成一起。
Veristrom2为大型机发布了Hadoop的商业版本,这一版本的Hadoop再加上最先进的数据连接器技术,使得z/OS数据可以使用Hadoop范型进行处理,同时数据不需要离开大型机。由于整个解决方案运行在System z的Linux中,因此可以部署到低成本的、专用的大型机Linux处理器上。vStrom Enterprise 包含zDoop,这是完全支持开源Apache Hadoop的实现,zDoop为具备SQL背景的开发人员提供了Hive,为采用过程式方法构建应用程序的开发人员提供了Pig。
在大型机环境中,用户可以将Hadoop中的数据同各种NoSQL、DB2和IMS数据库整合到通用环境中,并使用大型机分析软件对数据进行分析,例如IBM Cognos、SPSS、ILOG、IBM infoSphere Warehouse。大型机用户可以利用这种厂家集成的能力。
- 用于z/OS的IBM DB2 Analytics Accelerator是基于IBM,Netezza技术,通过透明地将一些查询卸载到Acceleretor设备的大规模并行架构,大大加快了查询的速度。
- 用于Hadoop的IBM PureData System是一个专用的、基于标准的系统,它将IBM InfoSphere BigInsights基于Hadoop的软件、服务器、存储系统集成到一个独立的系统中。
- IBM zEnterprise Analytics System(ISAS)9700/9710 是基于大型机的高性能软硬件集成平台。
用于大数据分析的设备
捆绑已经成为IT领域很酷的概念,而且最近的容器化技术将所有相关的概念都捆绑在一起,从而实现自动化并加速IT,该技术通过Docker所引入的简化引擎得到了扎实的推进。
用于大规模数据分析的数据仓库设备
IBM PureData System for Analytics 目的是让企业能够将R作为其大数据分析的主要组成部分。利用Netezza技术,在架构上将数据库、服务器、存储集成为一个专用的、易于管理的系统,将数据移动减少到最小,从而加速数据分析,分析建模和数据评分的过程。
EMC Greenplum设备是下一代数据仓库和大规模分析处理的代表。EMC为大规模分析提供了新的经济模型,允许用户通过低成本商用服务器、存储、网络构建数据仓库。以较小的代价扩展到PB级数据。Greenplum使得企业可以很容易地扩展并利用不断增长的计算机池中成百上千的内核的并行性。Greenplum的大规模并行以及无共享架构充分利用每个核,具有线性可扩展性以及无与伦比的处理性能。支持SQL和MapReduce并行处理。
Hitachi统一计算平台(UCP) 将数据存储在内存中的能力是通过大数据将企业从传统商业智能转变为商业优势的关键。SAP High-performance Analytic Application(HANA)是一个in-memory分析和实时分析的优秀平台。
Oracle SuperCluster 它是一个集成了服务、存储、网络和软件的系统,提供了极大的端到端的数据库及应用程序性能,减少一开始及持续使用中的支持和维护工作量及复杂性,使拥有的成本降至最低。
还有SAS High-Performance Analystics(HPA)和Aster Big Analytics Appliance
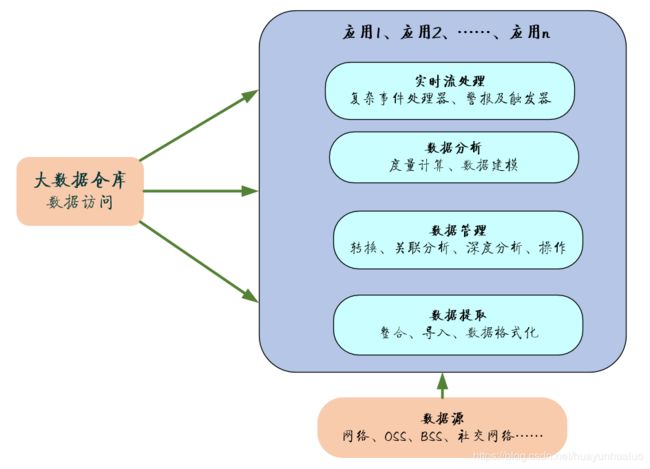
in-memory大数据分析
Salient MPP(http://www.salient.com/)是一个超级可扩展、in-memory、多维分析数据平台,克服了速度、粒度、简单性、使用灵活性方面的传统限制。
GridGain In–Memory Data Fabric是一个成熟的软件解决方案,它提供了前所未有的速度以及不受限制的规模,目前是加速提取及时洞见的过程。它支持高性能十五分析,实时分析、更快的分析。GridGain In-Memory Data Fabric 提供了统一的API,涵盖主要应用程序类型(Java,.Net,C++)并将它们用多个数据存储相连接。这些数据存储中可以包含结构化、半结构化数据(SQL、NoSQL、Hadoop)
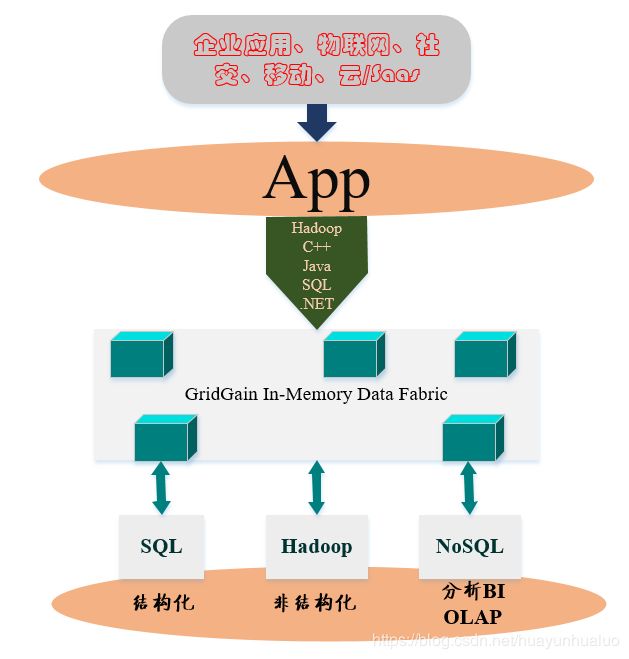
in-memory 流处理
流处理适合具有以下特点的应用程序,即应用程序不始于传统处理方法和基于磁盘存储。这些应用程序都以非常高的速度产生大量数据,要求相应的基础设施能够无瓶颈的实时处理这些数据。Apache Strom 主要聚焦于不需要关注滑动窗口或数据查询能力的前提下,提供事件工作流及导流功能。
Birst in-memory 数据库使用列式(columnar)数据存储。为了快速查找和聚合,每一列都进行了完全索引。高度并行框架意味着增加更多处理器内核、性能也应该得到扩展,Birst 基于上下文(join、filter和sort)进行动态索引。因此能够最大限度的提升性能并降低内存占用。Birst在处理任意的,稀疏的数据时使用哈希映射,使用位图来处理更加结构化、更密集的数据。
大数据的in-database处理
这是指主流数据的数据库管理系统中执行分析的能力,而不是在应用程序服务器或桌面程序中,它加速了企业分析的性能,数据可管理性、可扩展性。in-database处理对大数据分析非常理想,因为涉及到的数据量非常大,使得经过网络重复复制数据不切实际。
基于Hadoop的大数据设备
Hadoop是用于大数据处理的开源软件框架,由多个模块组成。其中关键模块是MapReduce(大规模数据处理框架)和Hadoop分布式文件系统(HDFS)(数据存储框架)。该框架将计算引擎放置在保存数据的物理节点上。
粗粒度搜索、索引、清理等任务会分配给Hadoop模块,而细粒度分析则通过成熟稳定的数据管理解决方案来完成。除了预处理,Hadoop可以方便地清除各种冗余、重复和常规数据最终得到真正的价值。第二个主要的任务将所有多结构数据转换成结构化数据,使得传统数据仓库和数据库能够对转换后的数据进行处理,向用户提供实用的信息。
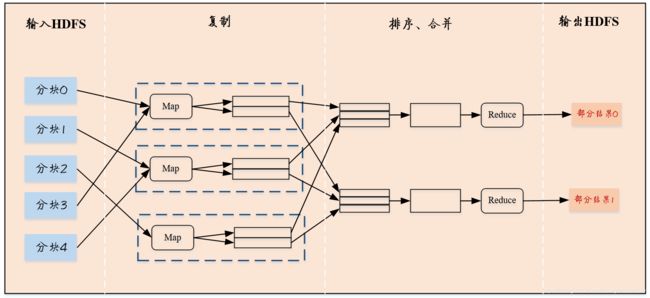
Hadoop主要采用的无共享模式,所有Hadoop数据保存在每个节点的本地存储中,而不是保存在网络存储器中。该系统是智能的,MapReduce调度器会对处理进行优化,令处理发生在保存相关数据的相同节点或者位于以太网交换的相同的叶子节点中。
Hadoop天性具有容错性,通过数据复制和投机处理(speculative processing)能够减缓预期的硬件故障。Hadoop的一个好处就是能够上传非结构化文件不需要首先对它们进行规范化。
Gartner将大数据设备定义为一个集成系统,包括预集成的服务器、存储、网络设备的组合,再加上同Hadoop这样的大数据分布式处理框架。主要的优点
- 标准化配置
- 融合硬件和软件
- 统一的监视与管理工具
缺点:
- 昂贵的购置以及增量扩张成本
- 刚性配置
- 规模化运营
Oracle Big Data Application 是一个高性能且安全的平台,用来运行Hadoop和NoSQL工作负载。可以无缝将Hadoop和NoSQL中的数据同Oracle数据库中的数据集成到一起。
高性能大数据存储设备
HDFS是一个高度可扩展的分布式文件系统,为整个Hadoop集群提供了单独的全局命名空间,HDFS包含了支持直连式存储(DAS)的DataNode,它存储64MB或128MB的数据块,从而利用磁盘的顺序I/O的能力,尽量减少随机读写造成的延迟。
但是HDFS在扩展性和性能方面有一定的限制,因为它采用单一的命名空间服务器。文件系统是存储、组织、提取、更新数据的标准化机制。文件系统解决方案给大多数商业组织带来了额外的负担,需要技术资源、时间以及经济投入。考虑到这些约束,类似Lustre这样的并行文件系统(PFS)开始流行起来,其是面对大数据带来的严格要求。PFS使得节点或文件服务器能够同时为多个客户端提供服务。使得名为文件条带化(file striping)的技术,PFS通过支持多个客户并发读写大幅度提高I/O性能,从而增加可用I/O带宽。
ActiveStor
ActiveStor是下一代存储设备,通过企业级SATA硬盘的成本收益提供闪存技术在高性能方面带来的好处。
主要的优点:
- 高并行性能
- 企业级可靠性和灵活性
- 易于管理
Mengjun Xie, Kyong-Don Kang, Can Basaran (2013) Moin: a multi-GPU MapReduce framework ↩︎
The Elephan on the Mainframe, a white paper by IBM and Veristorm, 2014. http://www.veristrom.com/sites/g/files/g9600391/f/collateral/ZSW03260-USEN01.pdf ↩︎