ConcurrentHashMap&HashMap&TableMap
首先HashMap的初始容量设置为16,其实必须是2的幂。
问一个问题:
Hashmap中的链表大小超过八个时会自动转化为红黑树,
当删除小于六时重新变为链表,为啥呢?
在源码中,有一个叫做_Factor,默认是0.75,根据泊松分布,也即是说单个hash桶内元素个数为8的概率小于百万分之一。所以以7为转折点,大于等于8的时候才进行转换为树,小于等于6的时候就化为链表。
在多线程情况下,为保证线程安全,怎样使用HashMap?
- 使用Collections.synchronizedMap(Map)创建线程安全的map集合;
- Hashtable
- ConcurrentHashMap
但是在一般情况下,处于线程并发度原因,只使用ConcurrentHashMap。
1 HashTable与HashMap区别:
- 在多线程情况下使用HashTable,对get方法进行synchoried枷锁,保证安全机制。
- HashMap允许键值为空:
HashTable不允许键值为空,一下源码
//HashMap 看出当键值为空,则返回第一个桶进行插值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashTable
采用安全失败机制:即当前获取的数据可能不是最新的数据,如果为空值,则无法判断是为空还是不存在。
//看下面抛出异常信息。
public V put(K key, V value) {
Segment s;
if (value == null)
throw new NullPointerException();//这就是为啥他不可以put null值的原因
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
HashMap线程不安全,为什么使用使用CourrentHashMap?1.7版本
HashMap的底层参考我的另一篇文章,桶原则:https://blog.csdn.net/huifeidezhu521/article/details/105451427
在ConcrrentHashMap中的数组采用Segment 数组,理论上讲采用分段锁机制,继承ReentrantLock,就是访问当前Segment,并不会影响其他的。
put操作,做到线程安全
1.7版本
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry
//这一步是计算方式
HashEntry node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry first = entryAt(tab, index);
for (HashEntry e = first;;) {
if (e != null) {
K k;
// 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
if (node != null)
node.setNext(first);
else
node = new HashEntry(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
1.8版本:
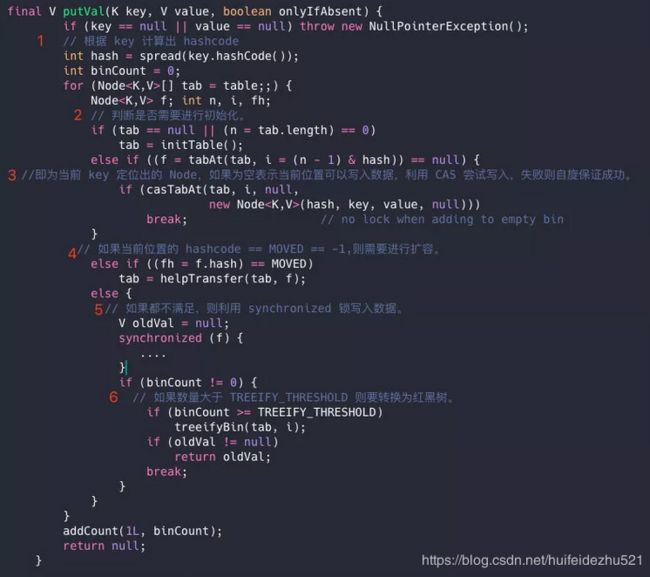
用语言描述就是:
根据 key 计算出 hashcode 。
判断是否需要进行初始化。
即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
如果都不满足,则利用 synchronized 锁写入数据。
如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
get操作
需要通过key值Hsah之后定位到Segement,再一次Hash定位到具体元素。每次获取都是最新值,并不需要加锁。
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
但是在1.8版本中采用CAS + synchronized 来保证并发安全性。同时引入红黑树。
ConcurrentHashMap的get操作
根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
如果是红黑树那就按照树的方式获取值。
就不满足那就按照链表的方式遍历获取值。

小结:1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率,甚至取消了 ReentrantLock 改为了 synchronized。
///站在巨人的肩膀上,也是第一次写这么深奥的东西,谅解。