爬虫实战2(下):爬取豆瓣影评
上篇笔记我详细讲诉了如何模拟登陆豆瓣,这次我们将记录模拟登陆+爬取影评(复仇者联盟4)实战。本文行文结构如下:
-
模拟登陆豆瓣展示
-
分析网址和源码爬取数据
-
进行面对对象重构
-
总结
一、模拟登陆豆瓣
模拟登陆在上文已经详细介绍如何利用post方式登陆,这里不再赘述,直接给出源码如下:
import requests
# 1.设置URL 和 headers
loginURL = "https://accounts.douban.com/j/mobile/login/basic"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"
}
# 2.分析表单
data = {
"ck": "",
"name": "你的账号",
"password": "你的密码",
"remember": "false",
"ticket": ""
}
# 3.创建session对象保存对话
session = requests.Session()
session.post(url=loginURL, headers=headers, data=data)
# 4.开始登陆豆瓣
# (测试)比如获取登陆后我的主页信息
personalURL = "https://www.douban.com/people/195562116/"
r = session.get(personalURL)
if r.status_code == 200:
print("登陆成功!\n")
else:
print("登陆失败!")
二、分析爬取数据
登陆豆瓣我们就可以爬取500条豆瓣影评(不登录200条),上文我们已经分析出每一页评论URL变化规律:
![]()
那么下文我们主要精力便在正则分析 & 数据保存这两块。
1.正则分析
审查元素我们可以发现:

-
作者信息在标签< div class=“avatar”>下,正则匹配为:
author = re.compile(' -
赞同数在标签< span class=“comment-vote”>下,正则匹配为:
votes = re.compile(' -
评论正文在< span class=“short”>下,正则匹配为:
content = re.compile('
将这些正则写在一起一一对应匹配:
# 5.正则匹配
pattern = re.compile('' + # 作者
'.*?(.*?) ' + # 赞同数
'.*?(.*?) ', # 内容
re.S) # re.S使得.也可以匹配空格
完成正则匹配后,开始将数据保存。
2.数据保存
数据保存,我们要import time库,每下载一页数据停止3S,否则可能会被断开连接/封IP。
-
设置路径
# 6.数据保存 path = "C:\\Users\\86151\\Desktop\\编程笔记\\爬虫实战2(下):爬取豆瓣数据\\复仇者联盟4影评.txt" -
循环下载数据(前10页)
for i in range(0, 10): index = i*20 commentsURL = "https://movie.douban.com/subject/26100958/comments? start="+str(index)+"&limit=20&sort=new_score&status=P" response = session.get(commentsURL) page_code = response.text commentsItems = re.findall(pattern, page_code) for item in commentsItems: with open(path, 'a', encoding='utf-8') as f: # 注意要重编码 f.write("\n作者:{0} 赞同数:{1}\n\n {2}".format(item[0], item[1], item[2])) f.write("\r\n-------------------------------------------------------------------------------------------\r\n") time.sleep(3) # 太快防止被检测爬虫 print("下载第{}页数据完毕!\n".format(i+1)) -
结果
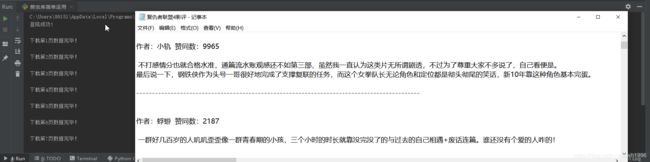
三、面对对象重构
代码重构成面对对象,方便代码复用,现附录代码如下:
import requests
import time
import re
class doubanSpider:
def __init__(self):
self.loginURL = "https://accounts.douban.com/j/mobile/login/basic"
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
self.data = {
"ck": "",
"name": "",
"password": "",
"remember": "false",
"ticket": ""
}
self.session = requests.Session()
self.savePath = "C:\\Users\\86151\\Desktop\\编程笔记\\爬虫实战2(下):爬取豆瓣数据\\复仇者联盟4影评.txt"
def login(self, userName, password):
self.data["name"] = userName
self.data["password"] = password
r = self.session.post(url=self.loginURL, headers=self.headers,data=self.data)
if r.status_code == 200: # 可能状态码是200但登录失败(比如弹出验证码),下篇博文解决
print("登录成功!")
else:
print("登录失败!")
def download(self, pages=10):
pattern = re.compile('' +
'.*?(.*?) ' +
'.*?(.*?) ',
re.S)
for i in range(0, pages):
index = i*20
commentsURL = "https://movie.douban.com/subject/26100958/comments?start="+str(index)+"&limit=20&sort=new_score&status=P"
response = self.session.get(commentsURL)
page_code = response.text
commentsItems = re.findall(pattern, page_code)
for item in commentsItems:
with open(self.savePath, 'a', encoding='utf-8') as f: # 注意要重编码
f.write("\n作者:{0} 赞同数:{1}\n\n {2}".format(item[0], item[1], item[2]))
f.write("\r\n---------------------------------------------------------------------------------\r\n")
time.sleep(3)
print("下载第{}页数据完毕!\n".format(i+1))
print("下载完成!")
if __name__ == '__main__':
spider = doubanSpider()
spider.login("你的账号", "你的密码")
spider.download(10) # 下载前十页评论
四、总结
爬虫到此已经可以登录一些简单反爬虫网站爬取数据了,但仍然有三个问题亟待解决:
- 验证码如何解决
- 由于网页异步加载等方式爬取到源码与审查元素不一致(如豆瓣搜索)
- FormDate数据被加密,如何模拟post方式登陆(如知乎登陆),
基于此,下次知乎实战,我们将用到python+Selenium+re模拟真实浏览器登陆爬取知乎帖子图片下载。