高并发解决方案:如何设计一个秒杀系统,一致性hash解读(三)
什么是秒杀
秒杀场景一般会在电商网站举行一些活动或者节假日在12306网站上抢票时遇到。对于电商网站中一些稀缺或者特价商品,电商网站一般会在约定时间点对其进行限量销售,因为这些商品的特殊性,会吸引大量用户前来抢购,并且会在约定的时间点同时在秒杀页面进行抢购。
秒杀系统场景特点
- 秒杀时大量用户会在同一时间同时进行抢购,网站瞬时访问流量激增。
- 秒杀一般是访问请求数量远远大于库存数量,只有少部分用户能够秒杀成功。
- 秒杀业务流程比较简单,一般就是下订单减库存。
秒杀架构设计理念
限流: 鉴于只有少部分用户能够秒杀成功,所以要限制大部分流量,只允许少部分流量进入服务后端。
削峰:对于秒杀系统瞬时会有大量用户涌入,所以在抢购一开始会有很高的瞬间峰值。高峰值流量是压垮系统很重要的原因,所以如何把瞬间的高流量变成一段时间平稳的流量也是设计秒杀系统很重要的思路。实现削峰的常用的方法有利用缓存和消息中间件等技术。
异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。
内存缓存:秒杀系统最大的瓶颈一般都是数据库读写,由于数据库读写属于磁盘IO,性能很低,如果能够把部分数据或业务逻辑转移到内存缓存,效率会有极大地提升。
可拓展:当然如果我们想支持更多用户,更大的并发,最好就将系统设计成弹性可拓展的,如果流量来了,拓展机器就好了。像淘宝、京东等双十一活动时会增加大量机器应对交易高峰。
架构方案
一般秒杀系统架构
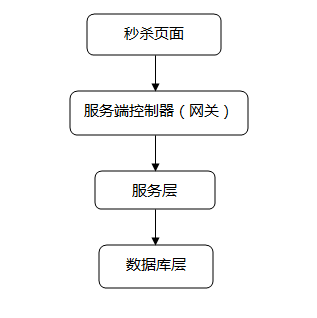
设计思路
将请求拦截在系统上游,降低下游压力:秒杀系统特点是并发量极大,但实际秒杀成功的请求数量却很少,所以如果不在前端拦截很可能造成数据库读写锁冲突,甚至导致死锁,最终请求超时。
充分利用缓存:利用缓存可极大提高系统读写速度。
消息队列:消息队列可以削峰,将拦截大量并发请求,这也是一个异步处理过程,后台业务根据自己的处理能力,从消息队列中主动的拉取请求消息进行业务处理。
前端方案
浏览器端(js):
页面静态化:将活动页面上的所有可以静态的元素全部静态化,并尽量减少动态元素。通过CDN来抗峰值。
禁止重复提交:用户提交之后按钮置灰,禁止重复提交
用户限流:在某一时间段内只允许用户提交一次请求,比如可以采取IP限流
后端方案
服务端控制器层(网关层)
限制uid(UserID)访问频率:我们上面拦截了浏览器访问的请求,但针对某些恶意攻击或其它插件,在服务端控制层需要针对同一个访问uid,限制访问频率。
服务层
上面只拦截了一部分访问请求,当秒杀的用户量很大时,即使每个用户只有一个请求,到服务层的请求数量还是很大。比如我们有100W用户同时抢100台手机,服务层并发请求压力至少为100W。
-
采用消息队列缓存请求:既然服务层知道库存只有100台手机,那完全没有必要把100W个请求都传递到数据库啊,那么可以先把这些请求都写到消息队列缓存一下,数据库层订阅消息减库存,减库存成功的请求返回秒杀成功,失败的返回秒杀结束。
-
利用缓存应对读请求:对类似于12306等购票业务,是典型的读多写少业务,大部分请求是查询请求,所以可以利用缓存分担数据库压力。
- 利用缓存应对写请求:缓存也是可以应对写请求的,比如我们就可以把数据库中的库存数据转移到Redis缓存中,所有减库存操作都在Redis中进行,然后再通过后台进程把Redis中的用户秒杀请求同步到数据库中。
数据库层
数据库层是最脆弱的一层,一般在应用设计时在上游就需要把请求拦截掉,数据库层只承担“能力范围内”的访问请求。所以,上面通过在服务层引入队列和缓存,让最底层的数据库高枕无忧。
案例:利用消息中间件和缓存实现简单的秒杀系统
Redis是一个分布式缓存系统,支持多种数据结构,我们可以利用Redis轻松实现一个强大的秒杀系统。
我们可以采用Redis 最简单的key-value数据结构,用一个原子类型的变量值(AtomicInteger)作为key,把用户id作为value,库存数量便是原子变量的最大值。对于每个用户的秒杀,我们使用 RPUSH key value插入秒杀请求, 当插入的秒杀请求数达到上限时,停止所有后续插入。
然后我们可以在台启动多个工作线程,使用 LPOP key 读取秒杀成功者的用户id,然后再操作数据库做最终的下订单减库存操作。
当然,上面Redis也可以替换成消息中间件如ActiveMQ、RabbitMQ等,也可以将缓存和消息中间件 组合起来,缓存系统负责接收记录用户请求,消息中间件负责将缓存中的请求同步到数据库。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简 单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
在分布式集群中,对机器的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。如果采用常用的hash(object)%N算法,那么在有机器添加或者删除后,很多原有的数据就无法找到了,这样严重的违反了单调性原则。
关于一致性hash,这里有一篇更详细的文章:http://www.zsythink.net/archives/1182
虚拟节点(一下完全引自:http://my.oschina.net/jsan/blog/49702)
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。

图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache时的映射关系如图 7 所示。
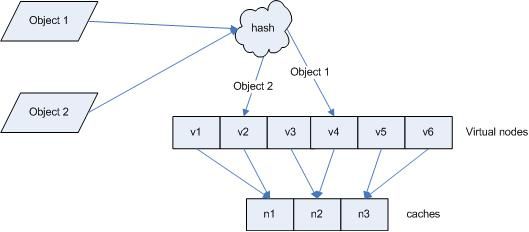
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2