决策树(一):分类树原理和python实现
决策树原理
决策树(decision tree)是机器学习中常用的一种分类和回归方法。决策树学习通常包含三个步骤:特征选择、决策树生成、决策树修剪。在本文中主要讨论分类决策树。
分类决策树的模型是一个树形结构,由结点(node)和有向边(directed edge)组成,其中结点又分为:内部结点和叶结点。内部结点表示一个特征(图中的黑色圆),而叶结点表示一个类(黑色方框)。
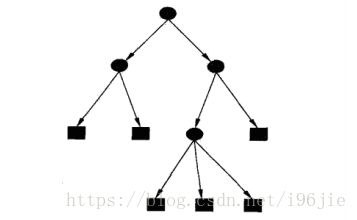
其中根结点包含了整个数据集,通过在数据集中找到一个最优特征,也就是最优划分属性,通过最优划分属性,将数据集分为若干子集,划分到子节点中。很明显,决策树的生成是一个递归过程,而要使递归返回,则需要:
- 当前结点样本属于同一类
- 当前结点样本为空
- 当前属性为空,或是所有样本在所有属性集上取值相同
所以,分类决策树的大致流程如下所示:

其中,最关键的就是如何去寻找这个最优特征。
信息增益、信息增益比
信息熵
在信息论和概率统计中,熵(entropy)是表示随机变量不确定的度量。
假设X是一个有限个值的随机离散变量,概率分布是:
![]()
![]()
则将其熵定义为:
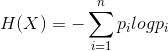
其中若![]() ,则定义
,则定义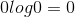 。可以看出,熵只与X的分布有关,所以也可写为:
。可以看出,熵只与X的分布有关,所以也可写为:
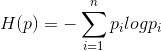
熵越大,随机变量的不确定性也就越大,举个栗子:
当随机变量只有两个值时,熵为:
![]()
作熵随概率变化的曲线图:

可以看出,当概率为0或者1时,熵为0,变量完全没有不确定性,而当p为0.5时,熵最大,随机变量不确定性最大。
条件熵
设随机变量(X,Y),其联合概率分布为:
![]()
![]()
条件熵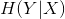 表示在已知条件X下Y的不确定度。
表示在已知条件X下Y的不确定度。
在数学上定义为X给定条件下,Y的条件概率分布的熵对X的数学期望:

![]()
当熵和条件熵的中的概率是由数据估计得到时,称为经验熵和经验条件熵。
信息增益
特征A对训练集D的信息增益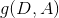 ,定义为D的经验熵和特征A下的经验条件熵的差:
,定义为D的经验熵和特征A下的经验条件熵的差:
![]()
显然,对于D而言,决定信息增益的只有特征A,信息增益大的特征具有更强的分类能力。
举个栗子:
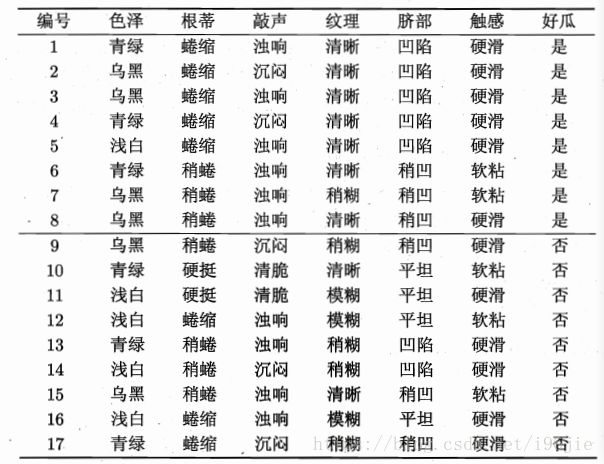
(数据来自西瓜书)
数据集中的经验熵:
![]()
经验条件熵以纹理为例:

信息增益:
![]()
同样,我们也可以将其他特征的信息增益都计算出来,最后得到的最大的是纹理。
于是将数据集按纹理划分成三个子集,对子集再次运用决策树算法进一步划分。
信息增益比
实际上,信息增益对可取值数目较多的特征有所偏好,也就是当经验熵偏大时,信息增益也会偏大,反之亦然。使用信息增益比可以使这问题进一步修正。
信息增益比定义为信息增益与数据集经验熵之比:
![]()
决策树生成
ID3
ID3就是运用信息增益来选择特征,递归构建决策树。
输入:数据集D,特征集A,阈值
输出:决策树T
- D中所有实例属于同一类,则T为单节点树,返回T。
- 若A为空集,则T为单节点树,D中占比最大的类作为该结点的类标记,返回T。
- 计算A中各特征的信息增益,选择最大的特征
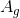 。
。 - 的信息增益小于,则T为单节点树,D中占比最大的类作为该结点的类标记,返回T。
- 否则,对的每一个可能值,将D划分若干子集
 ,构建子节点,构成树T,返回T。
,构建子节点,构成树T,返回T。 - 以为数据集,A-为特征集,递归调用1~5步,返回T。
C4.5
与ID3相似,C4.5就是运用信息增益比来选择特征,递归构建决策树。
输入:数据集D,特征集A,阈值
输出:决策树T
- D中所有实例属于同一类,则T为单节点树,返回T。
- 若A为空集,则T为单节点树,D中占比最大的类作为该结点的类标记,返回T。
- 计算A中各特征的信息增益比,选择最大的特征。
- 的信息增益小于,则T为单节点树,D中占比最大的类作为该结点的类标记,返回T。
- 否则,对的每一个可能值,将D划分若干子集,构建子节点,构成树T,返回T。
- 以为数据集,A-为特征集,递归调用1~5步,返回T。
python实现
# -*- coding: utf-8 -*-
"""
Created on Sat Aug 4 10:37:10 2018
@author: 96jie
"""
import numpy as np
from math import log
label = []
feature = np.zeros([32561,124])
f = open(r'D:\python_test\test\test\样本\train.txt')
line = f.readline()
a = 0
while line:
data = []
for i in line.split( ):
data.append(i);
for i in data[1:]:
j = i.split(":")
feature[a][int(j[0]) - 1] = int(j[1])
if data[0] in '+1':
feature[a][123] = 1
else:
feature[a][123] = 0
line = f.readline()
a += 1
f.close
#构建训练集和测试集
feature1 = feature[5000:32561]
feature = feature[0:5000]
#每个特征中存在的取值
def classnums(data):
cla = []
for i in data:
if i not in cla:
cla.append(i)
return cla
#计算经验熵
def calentropy(data):
names = locals()
n = len(data)
p = []
H = 0
cla = classnums(data)
for i in cla:
names['class%s' %i] = data.count(i)
p.append(data.count(i)/n)
for i in p:
H -= i*log(i,2)
return H
#计算经验条件熵
def calentropy2(data1,data2):
h = 0
n = len(data1)
names = locals()
dic = {}
cla = classnums(data1)
cla1 = classnums(data2)
for i in cla1:
names['class%s' %i] = []
for i in range(n):
a = data1[i]
b = data2[i]
dic[b] = names['class%s' %b]
names['class%s' %b].append(a)
for i in dic:
H = calentropy(dic[i])
m = len(dic[i])
H = (m / n) * H
h = h + H
return h
#切割数据集
def spiltdata(data,axis,value):
newdata = []
for i in data:
if i[axis] == value:
onedata = np.delete(i,axis,axis=0)
newdata.append(onedata)
newdata = np.array(newdata,dtype = float)
return newdata
#计算信息增益或者信息增益比
def chooseBestFeature(feature,c):
feature_nums = len(feature[0]) - 1
label = feature[:,-1]
label = label.tolist()
feature = feature[:,0:feature_nums]
h = calentropy(label)
hbest = 0
global feature_idx
for i in range(feature_nums):
a = feature[:,i]
H = calentropy2(label,a)
if c == 'id3':
h1 = h - H
if c == 'c4.5':
h1 = (h-H)/h
if hbest < h1:
hbest = h1
feature_idx = i
#print(feature_idx)
return feature_idx,hbest
#占比最大的类作为该结点的类标记
def maxkey(feature):
cla = classnums(feature)
max = 0
for i in cla:
feature1 = feature.tolist()
a = feature1.count(i)
if a > max:
max = a
maxkey = i
return maxkey
#生成树
def createtree(feature,thre,c):
if len(feature[0]) == 1:
return maxkey(feature)
label = feature[:,-1]
cla = classnums(label)
if len(cla) == 1:
return cla[0]
bestfeature,hbest = chooseBestFeature(feature,c)
#print(hbest)
if hbest < thre:
return maxkey(feature[:,bestfeature])
tree = {bestfeature:{}}
bestfeatureclass = classnums(feature[:,bestfeature])
for i in bestfeatureclass:
tree[bestfeature][i] = createtree(spiltdata(feature,bestfeature,i),thre,c)
return tree
#分类
def classify(data,tree):
a = list(tree.keys())[0]
lasta = tree[a]
key = data[a]
vof = lasta[key]
if type(vof) == dict:
classlabel = classify(data,vof)
else:
classlabel = vof
return classlabel
#计算正确率
def acc(feature,a):
n = len(feature)
t = 0
for i in range(n):
data = feature[i,0:122]
b = classify(data,a)
c = feature[i,-1]
if b == c:
t += 1
return t/n
Tree = createtree(feature,0.04,'id3')
print(Tree)
print(acc(feature,Tree))
print(acc(feature1,Tree))
最后的输出结果:

由于没有标记数据的属性,就用特征的下标来作为结点。
数据用的依旧是之前在逻辑回归中用的数据,可以看出整个决策树较为复杂,但泛化能力还可以,但在某些数据集中,直接使用上述算法可能会导致过拟合,这就需要对决策树进行剪枝,这在以后的博客中详细介绍。
代码和数据