在Apache Spark 2.0中使用 DataFrames 和 SQL
作者:马小龙(Dr. Christoph Schubert),浙江财经大学数据分析和大数据计算客座教授。2006年在德国不来梅大学获得数学博士学位后,在多特蒙德大学软件工程研究所从事研究和教学工作直到2011年来到中国。他的研究方向重点在大数据技术和NoSQL数据库以及功能规划和随机计算模型与模态逻辑。他还是国际大数据分析大会主席。
责编:郭芮,关注大数据领域,技术投稿、文章纠错请发送邮件至[email protected]。
本文为《程序员》原创文章,未经允许请勿转载,更多精彩文章请订阅《程序员》
在Apache Spark 2.0中使用DataFrames和SQL的第一步
Spark 2.0开发的一个动机是让它可以触及更广泛的受众,特别是缺乏编程技能但可能非常熟悉SQL的数据分析师或业务分析师。因此,Spark 2.0现在比以往更易使用。在这部分,我将介绍如何使用Apache Spark 2.0。并将重点关注DataFrames作为新Dataset API的无类型版本。
到Spark 1.3,弹性分布式数据集(Resilient Distributed Dataset,RDD)一直是Spark中的主要抽象。RDD API是在Scala集合框架之后建模的,因此间接提供了Hadoop Map / Reduce熟悉的编程原语以及函数式编程(Map、Filter、Reduce)的常用编程原语。虽然RDD API比Map / Reduce范例更具表达性,但表达复杂查询仍然很繁琐,特别是对于来自典型数据分析背景的用户,他们可能熟悉SQL,或来自R/Python编程语言的数据框架。
Spark 1.3引入了DataFrames作为RDD顶部的一个新抽象。DataFrame是具有命名列的行集合,在R和Python相应包之后建模。
Spark 1.6看到了Dataset类作为DataFrame的类型化版本而引入。在Spark 2.0中,DataFrames实际上是Datasets的特殊版本,我们有type DataFrame = Dataset [Row],因此DataFrame和Dataset API是统一的。
表面上,DataFrame就像SQL表。Spark 2.0将这种关系提升到一个新水平:我们可以使用SQL来修改和查询DataSets和DataFrames。通过限制表达数量,有助于更好地优化。数据集也与Catalyst优化器良好集成,大大提高了Spark代码的执行速度。因此,新的开发应该利用DataFrames。
在本文中,我将重点介绍Spark 2.0中DataFrames的基本用法。我将尝试强调Dataset API和SQL间的相似性,以及如何使用SQL和Dataset API互换地查询数据。借由整个代码生成和Catalyst优化器,两个版本将编译相同高效的代码。
代码示例以Scala编程语言给出。我认为这样的代码最清晰,因为Spark本身就是用Scala编写的。
SparkSession
SparkSession类替换了Apache Spark 2.0中的SparkContext和SQLContext,并为Spark集群提供了唯一的入口点。
val spark = SparkSession
.builder()
.appName("SparkTwoExample")
.getOrCreate()为了向后兼容,SparkSession对象包含SparkContext和SQLContext对象,见下文。当我们使用交互式Spark shell时,为我们创建一个名为spark的SparkSession对象。
创建DataFrames
DataFrame是具有命名列的表。最简单的DataFrame是使用SparkSession的range方法来创建:
scala> val numbers = spark.range(1,50,10)
numbers:org.apache.spark.sql.Dataset [Long] = [id:bigint]使用show给我们一个DataFrame的表格表示,可以使用describe来获得数值属性概述。describe返回一个DataFrame:
scala> numbers.show()
id
---
1
11
21
31
41
scala> numbers.describe().show()
summary| id
-------+--------------------------
count| 5
mean| 21.0
stddev| 15.811388300841896
min| 1
max| 41观察到Spark为数据帧中唯一的列选择了名称id。 对于更有趣的示例,请考虑以下数据集:
val customerData = List(("Alex", "浙江", 39, 230.00), ("Bob", "北京", 18, 170.00),
("Chris", "江苏", 45, 529.95), ("Dave", "北京", 25, 99.99), ("Ellie", "浙江", 23, 1299.95), ("Fred", "北京", 21, 1099.00))
val customerDF = spark.createDataFrame(customerData)在这种情况下,customerDF对象将有名为_1、_2、_3、_4的列,它们以某种方式违反了命名列的目的。可以通过重命名列来恢复:
val customerDF = spark.createDataFrame(customerData).
withColumnRenamed("_1", "customer").
withColumnRenamed("_2", "province").
withColumnRenamed("_3", "age").
withColumnRenamed("_4", "total")使用printSchema和describe提供以下输出:
scala> customerDF.printSchema
root
|-- customer: string (nullable = true)
|-- province: string (nullable = true)
|-- age: integer (nullable = false)
|-- total: double (nullable = false)
scala> customerDF.describe().show
summary| age| total
-------+----------------+---------------------
count| 6| 6
mean| 28.5| 571.4816666666667
stev| 10.876580344942981| 512.0094204374238
min| 18| 99.99
max| 45| 1299.95一般来说我们会从文件加载数据。SparkSession类为提供了以下方法:
val customerDFFromJSON = spark.read.json("customer.json")
val customerDF = spark.read.option("header", "true").option("inferSchema", "true").csv("customer.csv")在这里我们让Spark从CSV文件的第一行提取头信息(通过设置header选项为true),并使用数字类型(age和total)将数字列转换为相应的数据类型 inferSchema选项。
其他可能的数据格式包括parquet文件和通过JDBC连接读取数据的可能性。
基本数据操作
我们现在将访问DataFrame中数据的基本功能,并将其与SQL进行比较。
沿袭,操作,动作和整个阶段的代码生成
相同的谱系概念,转换操作和行动操作之间的区别适用于Dataset和RDD。我们下面讨论的大多数DataFrame操作都会产生一个新的DataFrame,但实际上不执行任何计算。要触发计算,必须调用行动操作之一,例如show(将DataFrame的第一行作为表打印),collect(返回一个Row对象的Array),count(返回DataFrame中的行数),foreach(对每一行应用一个函数)。这是惰性求值(lazy evaluation)的常见概念。
下面Dataset类的所有方法实际上依赖于所有数据集的有向非循环图(Directed Acyclic Graph,DAG),从现有数据集中创建一个新的“数据集”。这被称为数据集的沿袭。仅使用调用操作时,Catalyst优化程序将分析沿袭中的所有转换,并生成实际代码。这被称为整阶段代码生成,并且负责Dataset对RDD的性能改进。
Row-行对象
Row类在DataFrame的一行不带类型数据值中充当容器。通常情况下我们不会自己创建Row对象,而是使用下面的语法:
import org.apache.spark.sql._
val row = Row(12.3, false, null, "Monday")Row对象元素通过位置(从0开始)或者使用apply进行访问:
row(1) // 产生 Any = false它会产生一个Any的对象类型。或者最好使用get,方法之一:
row.getBoolean(1) // 产生 Boolean = false
row.getString(3) // 产生 String = "Monday"因为这样就不会出现原始类型的开销。我们可以使用isNull方法检查行中的一个条目是否为’null’:
row.isNullAt(2) // 产生 true我们现在来看看DataFrame类最常用的转换操作:
select
我们将要看的第一个转换是“select”,它允许我们对一个DataFrame的列进行投影和变换。
引用列
通过它们的名称有两种方法来访问DataFrame列:可以将其引用为字符串;或者可以使用apply方法,col-方法或$以字符串作为参数并返回一个Column(列)对象。所以customerDF.col(“customer”)和customerDF(“customer”)都是customerDF的第一列。
选择和转换列
最简单的select转换形式允许我们将DataFrame投影到包含较少列的DataFrame中。下面的四个表达式返回一个只包含customer和province列的DataFrame:
customerDF.select("customer", "province")
customerDF.select($"customer", $"province")
customerDF.select(col("customer"), col("province"))
customerDF.select(customerDF("customer"), col("province"))不能在单个select方法中调用混合字符串和列参数:customerDF.select(“customer”, $”province”)导致错误。
使用Column类定义的运算符,可以构造复杂的列表达式:
customerDF.select($"customer", ($"age" * 2) + 10, $"province" === "浙江")应用show得到以下结果:
customer| ((age * 2) + 10)| (province = 浙江)
--------+------------------+--------------------
Alex| 88.0| true
Bob| 46.0| false
Chris| 100.0| false
Dave| 60.0| false
Ellie| 56.0| true
Fred| 52.0| false列别名
新数据集的列名称从用于创建的表达式中派生而来,我们可以使用alias或as将列名更改为其他助记符:
customerDF.select($"customer" as "name", ($"age" * 2) + 10 alias "newAge", $"province" === "浙江" as "isZJ")产生与前面相同内容的DataFrame,但使用名为name,newAge和isZJ的列。
Column类包含用于执行基本数据分析任务的各种有效方法。我们将参考读者文档的详细信息。
最后,我们可以使用lit函数添加一个具有常量值的列,并使用when和otherwise重新编码列值。 例如,我们添加一个新列“ageGroup”,如果“age <20”,则为1,如果“age <30”则为2,否则为3,以及总是为“false”的列“trusted”:
customerDF.select($"customer", $"age",
when($"age" < 20, 1).when($"age" < 30, 2).otherwise(3) as "ageGroup", lit(false) as "trusted")给出以下DataFrame:
customer| age| ageGroup| trusted
--------+------+-----------+----------
Alex| 39| 3| false
Bob| 18| 1| false
Chris| 45| 3| false
Dave| 25| 2| false
Ellie| 23| 2| false
Fred| 21| 2| falsedrop是select相对的转换操作;它返回一个DataFrame,其中删除了原始DataFrame的某些列。
最后可使用distinct方法返回原始DataFrame中唯一值的DataFrame:
customerDF.select($"province").distinct返回一个包含单个列的DataFrame和包含值的三行:“北京”、“江苏”、“浙江”。
filter
第二个DataFrame转换是Filter方法,它在DataFrame行中进行选择。有两个重载方法:一个接受一个Column,另一个接受一个SQL表达式(一个String)。例如,有以下两种等效方式来过滤年龄大于30岁的所有客户:
customerDF.filter($"age" > 30)
customerDF.filter("age > 30") //SQLFilter转换接受一般的布尔连接符and(和)和or(或):
customerDF.filter($"age" <= 30 and $"province" === "浙江")
customerDF.filter("age <= 30 and province = '浙江'") //SQL我们在SQL版本中使用单个等号,或者使用三等式“===”(Column类的一个方法)。在==运算符中使用Scala的等于符号会导致错误。我们再次引用Column类文档中的有用方法。
聚合(aggregation)
执行聚合是进行数据分析的最基本任务之一。例如,我们可能对每个订单的总金额感兴趣,或者更具体地,对每个省或年龄组的总金额或平均金额感兴趣。可能还有兴趣了解哪个客户的年龄组具有高于平均水平的总数。借用SQL,我们可以使用GROUP BY表达式来解决这些问题。DataFrames提供了类似的功能。可以根据一些列的值进行分组,同样,还可以使用字符串或“Column”对象来指定。
我们将使用以下DataFrame:
val customerAgeGroupDF = customerDF.withColumn("agegroup",
when($"age" < 20, 1).when($"age" < 30, 2).otherwise(3))withColumn方法添加一个新的列或替换一个现有的列。
聚合数据分两步进行:一个调用GroupBy方法将特定列中相等值的行组合在一起,然后调用聚合函数,如sum(求和值),max(最大值)或为原始DataFrame中每组行计算的“avg”(平均值)。从技术上来说,GroupBy会返回一个RelationalGroupedDataFrame类的对象。RelationalGroupedDataFrame包含max、min、avg、mean和sum方法,所有这些方法都对DataFrame的数字列执行指定操作,并且可以接受一个String-参数来限制所操作的数字列。此外,我们有一个count方法计算每个组中的行数,还有一个通用的agg方法允许我们指定更一般的聚合函数。所有这些方法都会返回一个DataFrame。
例如:
customerAgeGroupDF.
groupBy("agegroup", "province").
count().show()输出以下内容:
agegroup| province| count|
--------+------------+--------+
2| 北京| 2|
3| 浙江| 1|
3| 江苏| 1|
2| 浙江| 1|
1| 北京| 1|
--------+------------+--------+customerAgeGroupDF.groupBy(“agegroup”).max().show()输出:
agegroup| max(age)| max(total)| max(agegroup)
--------+------------+--------------+-----------------
1| 18| 170.0| 1
3| 45| 529.95| 3
2| 25| 1299.95| 2最后,customerAgeGroupDF.groupBy(“agegroup”).min(“age”, “total”).show()输出:
agegroup| min(age)| min(total)
--------+------------+-------------
1| 18| 170.0
3| 39| 230.0
2| 21| 99.99还有一个通用的agg方法,接受复杂的列表达式。agg在RelationalGroupedDataFrame和Dataset中都可用。后一种方法对整个数据集执行聚合。这两种方法都允许我们给出列表达式的列表:
customerAgeGroupDF.
groupBy("agegroup").
agg(sum($"total"), min($"total")).
show()输出:
agegroup| sum(total)| min(total)
--------+-------------+--------------
1| 170.0| 170.0
3| 759.95| 230.0
2| 2498.94| 99.99可用的聚合函数在org.apache.spark.sql.functions中定义。类RelationalGroupedDataset在Apache Spark 1.x中被称为“GroupedData”。 RelationalGroupedDataset的另一个特点是可以对某些列值进行透视。例如,以下内容允许我们列出每个年龄组的总数:
customerAgeGroupDF.
groupBy("province").
pivot("agegroup").
sum("total").
show()给出以下输出:
province| 1| 2| 3
--------+-------+---------+---------
江苏| null| null| 529.95
北京| 170.0| 1198.99| null
浙江| null| 1299.95| 230.0其中null值表示没有省/年龄组的组合。Pivot的重载版本接受一个值列表以进行透视。这一方面允许我们限制列数,另一方面更加有效,因为Spark不需要计算枢轴列中的所有值。例如:
customerAgeGroupDF.
groupBy("province").
pivot("agegroup", Seq(1, 2)).
agg("total").
show()给出以下输出:
province| 1| 2
--------+--------+-----------
江苏| null| null
北京| 170.0| 1198.99
浙江| null| 1299.95最后,使用枢纽数据也可以进行复杂聚合:
customerAgeGroupDF.
groupBy("province").
pivot("agegroup", Seq(2, 3)).
agg(sum($"total"), min($"total")).
filter($"province" =!= "北京").
show()输出:
province|2_sum(`total`)|2_min(`total`)|3_sum(`total`)|3_min(`total`)
--------+--------------+--------------+---------------+-------------
江苏| null| null| 529.95| 529.95
浙江| 1299.95| 1299.95| 230.0| 230.0这里=!=是Column类的“不等于”方法。
排序和限制
OrderBy方法允许我们根据一些列对数据集的内容进行排序。和以前一样,我们可以使用Strings或Column对象来指定列:customerDF.orderBy(”age”)和 customerDF.orderBy($”age”)给出相同的结果。默认排序顺序为升序。如果要降序排序,可以使用Column类的desc方法或者desc函数:
customerDF.orderBy($"province", desc("age")).show()
customer| province| age| total
--------+------------+------+---------
Dave| 北京| 25| 99.99
Fred| 北京| 21| 1099.00
Bob| 北京| 18| 170.00
Chris| 江苏| 45| 529.95
Alex| 浙江| 39| 230.00
Ellie| 浙江| 23| 1299.95观察到desc函数返回了一个Column-object,任何其他列也需要被指定为Column-对象。
最后,limit方法返回一个包含原始DataFrame中第一个n行的DataFrame。
DataFrame方法与SQL对比
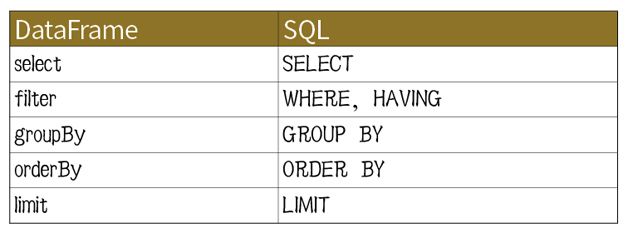
我们已经发现,DataFrame类的基本方法与SQLselect语句的部分密切相关。下表总结了这一对应关系:
到目前为止连接(join)在我们的讨论中已经缺失。Spark的DataFrame支持连接,我们将在文章的下一部分讨论它们。
下面将讨论完全类型化的DataSets API,连接和用户定义的函数(UDF)。
使用SQL来处理DataFrames
我们还在Apache Spark 2.0中直接执行SQL语句。SparkSession的SQL方法返回一个DataFrame。此外,DataFrame的selectExp方法也允许我们为单列指定SQL表达式,如下所示。为了能够引用SQL表达式中的DataFrame,首先有必要将DataFrame注册为临时表,在Spark 2中称为临时视图(temporary view,简称为tempview)。DataFrame为我们提供了以下两种方法:
- createTempView创建一个新视图,如果具有该名称的视图已存在,则抛出一个异常;
- createOrReplaceTempView创建一个用来替换的临时视图。
两种方法都将视图名称作为唯一参数。
customerDF.createTempView("customer") //register a table called 'customer'注册表后,可以使用SparkSession的SQL方法来执行SQL语句:
spark.sql("SELECT customer, age FROM customer WHERE province = '北京'")返回具有以下内容的DataFrame:
customer| age
--------+------
Bob| 18
Dave| 25
Fred| 21SparkSession类的catalog字段是Catalog类的一个对象,具有多种处理会话注册表和视图的方法。例如,Catalog的ListTables方法返回一个包含所有已注册表信息的Dataset:
scala> spark.catalog.listTables().show()
+----------+------------+--------------+---------------+----------------+
| name| database| description| tableType| isTemporary|
+----------+------------+--------------+---------------+----------------+
|customer | null| null| TEMPORARY| true|
+----------+------------+--------------+---------------+----------------+会返回一个包含有关注册表“tableName”中列信息的Dataset,例如:
spark.catalog.listColumns("customer")此外,可以使用DataSet的SelectExpr方法执行某些产生单列的SQL表达式,例如:
customerDF.selectExpr("sum(total)")
customerDF.selectExpr("sum(total)", "avg(age)")这两者都产生DataFrame对象。
第一步结束语
我们希望让读者相信,Apache Spark 2.0的统一性能够为熟悉SQL的分析师们提供Spark的学习曲线。下一部分将进一步介绍类型化Dataset API的使用、用户定义的函数以及Datasets间的连接。此外,我们将讨论新Dataset API的使用缺陷。
在Apache Spark 2.0中使用DataFrames和SQL的第二步
本文第一部分使用了无类型的DataFrame API,其中每行都表示一个Row对象。在下面的内容中,我们将使用更新的DatasetAPI。Dataset是在Apache Spark 1.6中引入的,并已在Spark 2.0中使用DataFrames进行了统一,我们现在有了type DataFrame = Dataset [Row],其中方括号([和] Scala中的泛型类型,因此类似于Java的<和>)。因此,上面讨论的所有诸如select、filter、groupBy、agg、orderBy、limit等方法都以相同的方式使用。
Datasets:返回类型信息
Spark 2.0以前的DataFrame API本质上是一个无类型的API,这也就意味着在编译期间很可能会因为某些编译器错误,导致无法访问类型信息。
和之前一样,我们将在示例中使用Scala,因为我相信Scala最为简洁。可能涉及的例子:spark将表示SparkSession对象,代表我们的Spark集群。
例子:分析Apache访问日志
我们将使用Apache访问日志格式数据。先一起回顾Apache日志中的典型行,如下所示:
127.0.0.1 - - [01/Aug/1995:00:00:01 -0400] "GET /images/launch-logo.gif HTTP/1.0" 200 1839此行包含以下部分:
- 127.0.0.1是向服务器发出请求的客户端(远程主机)IP地址(或主机名,如果可用);
- 输出中的第一个-表示所请求的信息(来自远程机器的用户身份)不可用;
- 输出中的第二个-表示所请求的信息(来自本地登录的用户身份)不可用;
- [01 / Aug / 1995:00:00:01 -0400]表示服务器完成处理请求的时间,格式为:[日/月/年:小时:分:秒 时区],有三个部件:”GET /images/launch-logo.gif HTTP / 1.0”;
- 请求方法(例如,GET,POST等);
- 端点(统一资源标识符);
- 和客户端协议版本(’HTTP / 1.0’)。
1.200这是服务器返回客户端的状态代码。这些信息非常有价值:成功回复(从2开始的代码),重定向(从3开始的代码),客户端导致的错误(以4开头的代码),服务器错误(代码从5开始)。最后一个条目表示返回给客户端的对象大小。如果没有返回任何内容则是-或0。
首要任务是创建适当的类型来保存日志行信息,因此我们使用Scala的case类,具体如下:
case class ApacheLog(
host: String,
user: String,
password: String,
timestamp: String,
method: String,
endpoint: String,
protocol: String,
code: Integer,
size: Integer
)默认情况下,case类对象不可变。通过它们的值来比较相等性,而不是通过比较对象引用。
为日志条目定义了合适的数据结构后,现在需要将表示日志条目的String转换为ApacheLog对象。我们将使用正则表达式来达到这一点,参考如下:
^(\S+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(\S+) (\S+)\s*(\S*)" (\d{3}) (\S+)可以看到正则表达式包含9个捕获组,用于表示ApacheLog类的字段。
使用正则表达式解析访问日志时,会面临以下问题:
- 一些日志行的内容大小以-表示,我们想将它转换为0;
- 一些日志行不符合所选正则表达式给出的格式。
为了克服第二个问题,我们使用Scala的“Option”类型来丢弃不对的格式并进行确认。Option也是一个泛型类型,类型Option[ApacheLog]的对象可以有以下形式:
- None,表示不存在一个值(在其他语言中,可能使用null);
- Some(log)for a ApacheLog-objectlog。
以下为一行函数解析,并为不可解析的日志条目返回None:
def parse_logline(line: String) : Option[ApacheLog] = {
val apache_pattern = """^(\S+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(\S+) (\S+)\s*(\S*)" (\d{3}) (\S+)""".r
line match {
case apache_pattern(a, b, c, t, f, g, h, x, y) => {
val size = if (y == "-") 0 else y.toInt
Some(ApacheLog(a, b, c, t, f, g, h, x.toInt, size))
}
case _ => None
}
}最好的方法是修改正则表达式以捕获所有日志条目,但Option是处理一般错误或不可解析条目的常用技术。
综合起来,现在来剖析一个真正的数据集。我们将使用著名的NASA Apache访问日志数据集,它可以在ftp://ita.ee.lbl.gov/traces/NASA_access_log_Jul95.gz下载。
下载和解压缩文件后,首先将其打开为String的Dataset,然后使用正则表达式解析:
import spark.implicits._
val filename = "NASA_access_log_Jul95"
val rawData = spark.read.text(filename).as[String].cache用spark.read.text方法打开文本文件并返回一个DataFrame,是textfile的行。使用Dataset的as方法将其转换为包含Strings的Dataset对象(而不是Rows包含字符串),并导入spark.implicits._以允许创建一个包含字符串或其他原始类型的Dataset。
现在可以解析数据集:
val apacheLogs = rawData.flatMap(parse_logline)flatMap将parse_logline函数应用于rawData的每一行,并将Some(ApacheLog)形式的所有结果收集到apacheLogs中,同时丢弃所有不可解析的日志行(所有结果的形式None)。
我们现在可以对“数据集”执行分析,就像在“DataFrame”上一样。Dataset中的列名称只是ApacheLog case类的字段名称。
例如,以下代码打印生成最多404个响应的10个端点:
apacheLogs.filter($"code" === 404).
groupBy($"endpoint").
count.
orderBy($"count".desc).
limit(10).show如前所述,可以将Dataset注册为临时视图,然后使用SQL执行查询:
apacheLogs.createOrReplaceTempView("apacheLogs")
spark.sql("select endpoint, count(*) as c
from apacheLogs
where code = 404
group by endpoint
order by c desc
limit 10").show上面的SQL查询具有与上面的Scala代码相同的结果。
用户定义的函数(user defined function, UDF)
在Spark SQL中,我们可以使用范围广泛的函数,包括处理日期、基本统计和其他数学函数的函数。Spark在函数中的构建是在org.apache.spark.sql.functions对象中定义的。
作为示例,我们使用以下函数提取主机名的顶级域:
def extractTLD(host : String) : String = {
host.substring(host.lastIndexOf('.') + 1)
}如果想在SQL查询中使用这个函数,首先需要注册。这是通过SparkSession的udf对象实现的:
val extractTLD_UDF =spark.udf.register("extractTLD", extractTLD _)函数名后的最后一个下划线将extractTLD转换为部分应用函数(partially applied function),这是必要的,如果省略它会导致错误。register方法返回一个UserDefinedFunction对象,可以应用于列表达式。
一旦注册,我们可以在SQL查询中使用extractTLD:
spark.sql("select extractTLD(host) from apacheLogs")要获得注册的用户定义函数概述,可以使用spark.catalog对象的listFunctions方法,该对象返回SparkSession定义的所有函数DataFrame:
spark.catalog.listFunctions.show注意Spark SQL遵循通常的SQL约定,即不区分大小写。也就是说,以下SQL表达式都是有效的并且彼此等价:select extractTLD(host)from apacheLogs,select extracttld(host)from apacheLogs,”select EXTRACTTLD(host) from apacheLogs”。spark.catalog.listFunctions返回的函数名将总是小写字母。
除了在SQL查询中使用UDF,我们还可以直接将它们应用到列表达式。以下表达式返回.net域中的所有请求:
apacheLogs.filter(extractTLD_UDF($"host") === "net")值得注意的是,与Spark在诸如filter,select等方法中的构建相反,用户定义的函数只采用列表达式作为参数。写extractTLD_UDF(“host”)会导致错误。
除了在目录中注册UDF并用于Column表达式和SQL中,我们还可以使用org.apache.spark.sql.functions对象中的udf函数注册一个UDF:
import org.apache.spark.sql.functions.udf
def request_failed(code : Integer) : Boolean = { code >= 400 }
val request_failed_udf = udf(request_failed _)注册UDF后,可以将它应用到Column表达式(例如filter里面),如下所示:
apacheLogs.filter(request_failed_udf($"code")).show但是不能在SQL查询中使用它,因为还没有通过名称注册它。
UDF和Catalyst优化器
Spark中用Catalyst优化器来优化所有涉及数据集的查询,会将用户定义的函数视作黑盒。值得注意的是,当过滤器操作涉及UDF时,在连接之前可能不会“下推”过滤器操作。我们通过下面的例子来说明。
通常来说,不依赖UDF而是从内置的“Column”表达式进行组合操作可能效果更好。
加盟
最后,我们将讨论如何使用以下两个Dataset方法连接数据集:
- join返回一个DataFrame
- joinWith返回一对Datasets
以下示例连接两个表1、表2(来自维基百科):
")
表1 员工(Employee)
")
表2 部门(Department)
定义两个case类,将两个表编码为case类对象的序列(由于空间原因不显示),最后创建两个Dataset对象:
case class Department (depID : Integer, depName: String)
case class Employee (lastname : String, depID: Integer)
val depData = Seq(Department(31, "Sales"),
... )
val empData = Seq(Employee("Rafferty", 31),
...,
Employee("Williams",null))
val employees = spark.createDataset(empData)
val departments = spark.createDataset(depData)为了执行内部等连接,只需提供要作为“String”连接的列名称:
val joined = employees.join(departments, "depID")Spark会自动删除双列,joined.show给出以下输出:

表3 输出
在上面,joined是一个DataFrame,不再是Dataset。连接数据集的行可以作为Seq列名称给出,或者可以指定要执行的equi-join(inner,outer,left_outer,right_outer或leftsemi)类型。想要指定连接类型的话,需要使用Seq表示法来指定要连接的列。请注意,如果执行内部联接(例如,获取在同一部门中工作的所有员工的对):employees.join(employees,Seq(“depID”)),我们没有办法访问连接的DataFrame列:employees.join(employees, Seq(“depID”)).select(“lastname”)会因为重复的列名而失败。处理这种情况的方法是重命名部分列:
employees.withColumnRenamed("lastname", "lname").
join(employees, Seq("depID")).show除了等连接之外,我们还可以给出更复杂的连接表达式,例如以下查询,它将所有部门连接到不知道部门ID且不在本部门工作的员工:
departments.join(employees, departments("depID") =!= employees("depID"))然后可以不指定任何连接条件,在两个Datasets间执行笛卡尔联接: departments.join(employees).show。
与joinWith类型保存连接
最后,Dataset的joinWith方法返回一个Dataset,包含原始数据集中匹配行的Scala元组。
departments.
joinWith(employees,
departments("depID") === employees("depID")
).show
表4 返回Dataset
这可以用于自连接后想要规避上述不可访问列的问题情况。
加入和优化器
Catalyst优化器尝试通过将“过滤器”操作向“下推”,以尽可能多地优化连接,因此它们在实际连接之前执行。
为了这个工作,用户定义的函数(UDF),不应该在连接条件内使用用因为这些被Catalyst处理为黑盒子。
结论
我们已经讨论了在Apache Spark 2.0中使用类型化的DatasetAPI,如何在Apache Spark中定义和使用用户定义的函数,以及这样做的危险。使用UDF可能产生的主要困难是它们会被Catalyst优化器视作黑盒。
另有CSDN Spark用户微信群,请添加微信guorui_1118并备注公司+实名+职位申请入群。
更多精彩,欢迎关注CSDN大数据公众号!
