手把手教你用Python分析电影 | 以《蚁人2》为例


作者: 唐绍祖
本文为 CDA 数据分析师原创作品,转载需授权
《蚁人2》自8月24日在中国大陆上映以来,已经有将近一个月。作为《复仇者联盟3》之后漫威出品的首部电影,《蚁人2》对漫威宇宙电影的剧情承转起着关键作用。9月20日当天在猫眼已经获得31.6万个评价,累计票房8.29亿,评分高达8.8分,不得不说这在漫威宇宙电影中已经是相当高的评分。
但是作者作为漫威的死忠粉,看过《蚁人2》之后觉得剧情平平,反派角色也不够突出,作为漫威喜剧流的电影,笑点也不是非常密集。但是其他观众如何看待呢?今天就跟着老司机一起来揭秘。
我们将使用Python抓取猫眼10万多条评论数据,从8月24日到9月20日,上映之前的评论量我们暂不做分析。
整个数据分析的过程分为四步:
获取数据
处理数据
存储数据
数据可视化
上面的过程并不是固定的,在数据可视化的步骤也会遇见很多报错,这时候就还需要根据报错信息返回去对数据进行进一步处理。
一、获取数据
简介
获取网页版本的猫眼评论有数量限制,因此我们选择猫眼app端的评论。
首先用浏览器打开猫眼电影的蚁人2电影网址:
http://maoyan.com/films/343208
然后按F12,在进入app窗口模式之后,点击查看app端的所有评论。
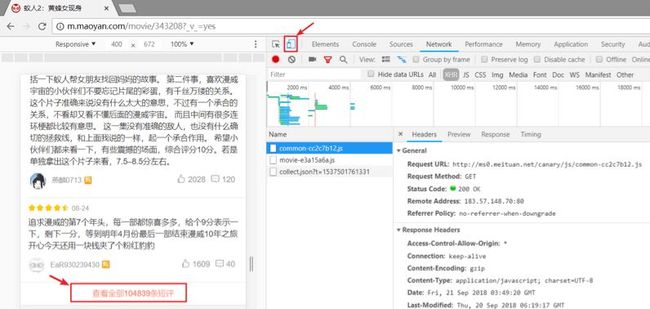
我们想要获取完整的数据评论接口,需要进入查看所有短评之后,往下再刷一些评论,然后点击左边的json文件,可以看到完整的url。

点击几个json文件之后,大家也会发现相应的变化规律。
网页返回的是json格式数据。
343208表示电影的专属id;offset表示偏移量;startTime表示获取评论的起始时间,从该时间向前取数据,即获取最新的评论。
cmts表示评论,每次获取15条,offset偏移量是指每次获取评论时的起始索引,向后取15条。
hcmts表示热门评论前10条。
total表示总评论数。
代码实现
这里先定义一个函数,用来根据指定url获取数据,且只能获取到指定的日期向前获取到15条评论数据。
# coding=utf-8
from urllib import request
import json
import time
from datetime import datetime
from datetime import timedelta
import random
# 获取数据,根据url获取
def get_data(url):
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36’
}
req = request.Request(url, headers=headers)
response = request.urlopen(req)
if response.getcode() == 200:
return response.read()
return None
if __name__ == ‘__main__’:
html = get_data(‘http://m.maoyan.com/mmdb/comments/movie/343208.json?_v_=yes&offset=0&startTime=2018-09-20%2022%3A25%3A03’)
print(html)
二、处理数据
对获取的数据进行处理,转换为json:
def parse_data(html):
data = json.loads(html)[‘cmts’] # 将str转换为json
comments = []
for item in data:
comment = {
‘id’: item[‘id’],
‘nickName’: item[‘nickName’],
‘cityName’: item[‘cityName’] if ‘cityName’ in item else ‘’, # 处理cityName不存在的情况
‘content’: item[‘content’].replace(‘\n’, ‘ ‘, 10), # 处理评论内容换行的情况
‘score’: item[‘score’],
‘startTime’: item[‘startTime’]
}
comments.append(comment)
return comments
if __name__ == ‘__main__’:
html = get_data(‘http://m.maoyan.com/mmdb/comments/movie/343208.json?_v_=yes&offset=0&startTime=2018-09-20%2022%3A25%3A03’)
comments = parse_data(html)
print(comments)
三、存储数据
为了能够获取到上映后所有评论数据,方法是:从‘2018-09-20 22:00:0’开始(爬取数据的当天),向前获取数据,根据url每次获取15条,然后得到末尾评论的时间,从该时间继续向前获取数据,直到影片上映日期(2018-08-24)为止,获取这之间的所有数据。
# 存储数据,存储到文本文件
def save_to_txt():
start_time = ‘2018-09-20 22:00:0’
end_time = ‘2018-08-23 00:00:00’
while start_time > end_time:
url = ‘http://m.maoyan.com/mmdb/comments/movie/343208.json?_v_=yes&offset=0&startTime=‘ + start_time.replace(‘ ‘, ‘%20’)
html = None
try:
html = get_data(url)
except Exception as e:
time.sleep(1 + float(random.randint(1, 50)) / 20)
html = get_data(url)
else:
time.sleep(0.8)
comments = parse_data(html)
print(comments)
start_time = comments[14][‘startTime’] # 获得末尾评论的时间
start_time = datetime.strptime(start_time, ‘%Y-%m-%d %H:%M:%S’) + timedelta(seconds=-1) # 转换为datetime类型,减1秒,避免获取到重复数据
start_time = datetime.strftime(start_time, ‘%Y-%m-%d %H:%M:%S’) # 转换为str
for item in comments:
with open(‘ant-man2.txt’, ‘a’, encoding=‘utf-8’) as f:
f.write(str(item[‘id’])+’,’+item[‘nickName’] + ‘,’ + item[‘cityName’] + ‘,’ + item[‘content’] + ‘,’ + str(item[‘score’])+ ‘,’ + item[‘startTime’] + ‘\n’)
if __name__ == ‘__main__’:
html = get_data(‘http://m.maoyan.com/mmdb/comments/movie/343208.json?_v_=yes&offset=0&startTime=2018-09-20%2022%3A25%3A03’)
comments = parse_data(html)
print(comments)
save_to_txt()
最终我们得的到txt格式的文本数据,编码格式为utf-8,一共102698条:
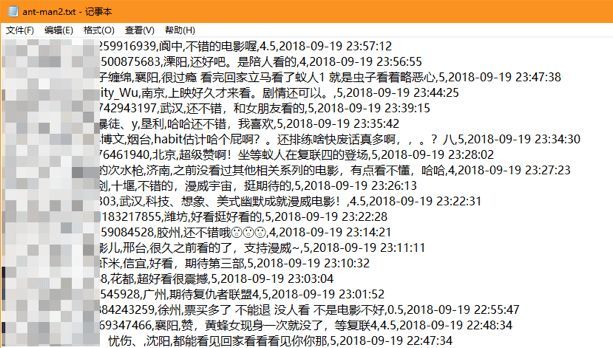
用下面的计算代码可以看到一共102698条记录:
count = 0
for index, line in enumerate(open(r’C:\Users\Administrator\.PyCharmCE2018.2\config\scratches\ant-man2.txt’,encoding=‘utf-8’)):
count += 1
print(count)
四、数据可视化
数据可视化过程中,我们主要使用到的可视化工具库是pyecharts。
Pyecharts是一个用于生成Echarts图表的类库,而Echarts是百度开源的一个数据可视化JS库,主要用于数据可视化。
我们接下来要安装的库和包,主要有以下:
pyecharts
echarts-china-provinces-pypkg
echarts-china-cities-pypkg
echarts-china-counties-pypkg
echarts-china-misc-pypkg
echarts-countries-pypkg
echarts-united-kingdom-pypkg
如果各位读者使用的是pycharm,安装起来也比较方便。
粉丝位置分布
下面代码中有一点需要注意的是“city_coordinates.json”这个文件是在项目对应的文件夹内,可以参考下面city_coordinates.json的路径找到自己对应的json文件:
# coding=utf-8
# 导入Style类,用于定义样式风格
from pyecharts import Style
# 导入Geo组件,用于生成地理坐标类图
from pyecharts import Geo
import json
# 导入Geo组件,用于生成柱状图
from pyecharts import Bar
# 导入Counter类,用于统计值出现的次数
from collections import Counter
# 处理地名数据,解决坐标文件中找不到地名的问题
def handle(cities):
# print(len(cities), len(set(cities)))
# 获取坐标文件中所有地名
data = None
with open(
‘C:/Users/Administrator/PycharmProjects/zhilianzhaopin/venv/lib/site-packages/pyecharts/datasets/city_coordinates.json’,
mode=‘r’, encoding=‘utf-8’) as f:
data = json.loads(f.read()) # 将str转换为json
# 循环判断处理
data_new = data.copy() # 拷贝所有地名数据
for city in set(cities): # 使用set去重
# 处理地名为空的数据
if city == ‘’:
while city in cities:
cities.remove(city)
count = 0
for k in data.keys():
count += 1
if k == city:
break
if k.startswith(city): # 处理简写的地名,如 达州市 简写为 达州
# print(k, city)
data_new[city] = data[k]
break
if k.startswith(city[0:-1]) and len(city) >= 3: # 处理行政变更的地名,如县改区 或 县改市等
data_new[city] = data[k]
break
# 处理不存在的地名
if count == len(data):
while city in cities:
cities.remove(city)
# 写入覆盖坐标文件
with open(
‘C:/Users/Administrator/PycharmProjects/zhilianzhaopin/venv/lib/site-packages/pyecharts/datasets/city_coordinates.json’,
mode=‘w’, encoding=‘utf-8’) as f:
f.write(json.dumps(data_new, ensure_ascii=False)) # 将json转换为str
在覆盖完坐标文件之后,我们就可以开始数据可视化,在此之前需要对城市名为空的值去除:
# 数据可视化
def render():
# 获取评论中所有城市
cities = []
with open(‘ant-man2.txt’, mode=‘r’, encoding=‘utf-8’) as f:
rows = f.readlines()
for row in rows:
print(row)
city = row.split(‘,’)[2]
If city != ‘’: # 去掉城市名为空的值
cities.append(city)
# 定义样式
style = Style(
title_color=‘#fff',
title_pos='c‘nter',’ width=1200,
height=600,
background_color='‘404a59'
’ )
# 根据城市数据生成地理坐标图
geoGeoGeo('《蚁‘2》粉丝位置分布', ’数据‘源:猫眼电影-老司机采集', ’*style.init_style)
attr, value = geo.cast(data)
geo.add('',‘’ttr, value, visual_range=[0, 3500],
visual_text_color='#‘ff', symbol_size=15,
is_visualmap=True, is_piecewise=True, visual_split_number=10)
geo.render('粉丝‘置分布-地理坐标图.html')
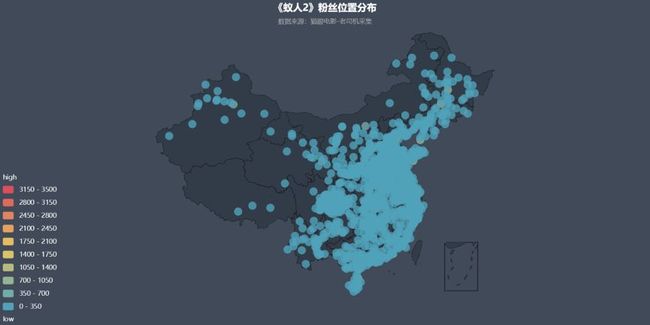
从上图我们可以看到粉丝在全国城市都有分布,当我们从上图左下角取消显示700评论量的时候会有下图显示:

可以发现粉丝数量多的城市主要分布在珠三角、长三角等东部城市,内陆省份里传说中很会“享受”的城市——成都,粉丝量也是非常可观。
我们继续对粉丝数量做柱状图TOP20排名:
# 根据城市数据生成柱状图
data_top20 = Counter(cities).most_common(20) # 返回出现次数最多的20条
bar = Bar('《蚁‘2》粉丝来源排行TOP20', ’数据‘源:猫眼电影-老司机采集', ’itle_pos='ce‘ter', ’idth=1200, height=600)
attr, value = bar.cast(data_top20)
bar.add('',‘attr, value, is_visualmap=True, visual_range=[0, 3500], visual_text_color='#fff', is_more_utils=True,
is_label_show=True)
bar.render('粉丝‘源排行-柱状图.html')
’if __name__ == '__‘ain__':
’ render()
我们可以通过拖动下图左下角的热度范围来显示相应城市粉丝数量范围,也可以在右边换成折线图显示:

我们从上图就更能明显地看到粉丝量在各城市分布情况,主要分布在中国比较富裕的城市。看来仓廪实不但能知礼节,而且能知漫威电影。
尤其是深圳,粉丝量排名第一,这部以量子科学为理论基础的科幻电影看来在“中国科技之城”非常受欢迎。
2.评分星级比例分析
作评分星级比例分析,用到的只有pyecharts里面的Pie组间,但是这里需要注意的是我们在获取评论的过程中,很可能会有以下报错:
![]()
这很可能是由于在爬虫的时候,由于中断造成爬下来的文本中有空行导致,因此我们在获取评论时就需要跳过这类报错。
实现代码:
# coding=utf-8
# 导入Pie组件,用于生成饼图
from pyecharts import Pie
# 获取评论中所有评分
rates = []
with open('an‘-man2.txt', ’ode='r'‘ ’ncoding='ut‘-8') ’s f:
rows = f.readlines()
for row in rows:
try:
rate = row.split(','‘[’]
except IndexError: #遇到报错则跳过
continue
if rate!= '':‘’ rates.append(rate)
# print(rates)
# 定义星级,并统计各星级评分数量
attAttr['五星‘, ’四星‘, ’三星‘, ’二星‘, ’一星‘]
’alue = [
rates.count('5'‘ ’ rates.count('4.‘'),’ rates.count('4'‘ ’ rates.count('3.‘'),’ rates.count('3'‘ ’ rates.count('2.‘'),’ rates.count('2'‘ ’ rates.count('1.‘'),’ rates.count('1'‘ ’ rates.count('0.‘')
’
# print(value)
pie = Pie('《蚁‘2》评分星级比例', ’itle_pos='ce‘ter', ’idth=900)
pie.add('7-‘7', ’ttr, value, center=[75, 50], is_random=True,
radius=[30, 75], rosetype='ar‘a',
’ is_legend_show=False, is_label_show=True)
pie.render('《蚁‘2》评分.html')
最后生成以下饼状图:
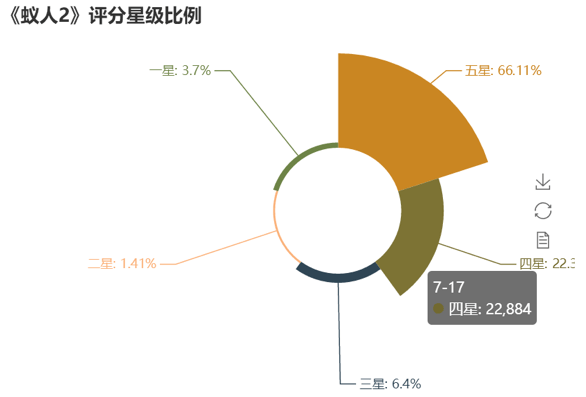
我们从上图可以看到,超过66%的观众给了5星好评,加上4星好评的话,就将近90%。可以说口碑非常好,这样的评分不但在中国电影比较难得,在漫威同系列电影也比较少见。
词云图
在做词云图方面,我们用到的工具库包括:jieba(用作中文分词)、Matplotlib(2D绘图库)、wordcloud(用作生成词云图)。
# coding=utf-8
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 获取所有评论
comments = []
with open('an‘-man2.txt', ’ode='r'‘ ’ncoding='ut‘-8') ’s f:
rows = f.readlines()
for row in rows:
try:
comment = row.split(','‘[’]
except IndexError: #跳过报错
continue
if comment != '':‘’ comments.append(comment)
print(comments)
# 设置分词
comment_after_split = jieba.cut(str(comments), cut_all=False) # 非全模式分词,cut_all=false
words = ' '‘j‘in(comment_after_split) # 以空格进行拼接
print(words)
# 设置屏蔽词
stopwords = STOPWORDS.copy()
stopwords.add('电影‘)
’topwords.add('一部‘)
’topwords.add('一个‘)
’topwords.add('没有‘)
’topwords.add('什么‘)
’topwords.add('有点‘)
’topwords.add('这部‘)
’topwords.add('这个‘)
’topwords.add('不是‘)
’topwords.add('真的‘)
’topwords.add('感觉‘)
’topwords.add('觉得‘)
’topwords.add('还是‘)
’topwords.add('但是‘)
’topwords.add('就是‘)
’topwords.add('蚁人‘)
’# 导入背景图
bg_image = plt.imread('an‘-man2.jpg')
’# 设置词云参数,参数分别表示:画布宽高、背景颜色、背景图形状、字体、屏蔽词、最大词的字体大小
wc = WordCloud(width=2024, height=1400, background_color='wh‘te', ’ask=bg_image, font_path='ST‘AITI.TTF',
’ stopwords=stopwords, max_font_size=400, random_state=50)
# 将分词后数据传入云图
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('of‘') ’# 不显示坐标轴
plt.show()
# 保存结果到本地
wc.to_file('蚁人‘词云图2.jpg')
景图上,作者使用蚁人的一个威猛形象:

最终生成以下词云图:

我们从词云图看出:
观众对电影的赞美是主流,“好看”、“可以”、“不错”、“很棒”等热词,说明观众对电影认可度高。
而观众提及最多的是电影里面的彩蛋,“彩蛋”、“最后”等词语自然也成为了“热词”。尤其是对漫威宇宙电影剧情发展至关重要的第二个彩蛋,更是让观众拍手叫好。
剧情方面“搞笑”、“幽默”等词语,反映了这部电影延续了老少咸宜的喜剧风格。
对于评论中的“一般般”、“不过”、“失望”、“还好”等词语,相信很多粉丝和我的感觉一样,电影在角色塑造方面不够丰满,笑点密集度也不及第一部。这可能也是大多数粉丝被第一部蚁人作品惊艳了之后,与期待有所落差产生的失落吧。

从以上分析可见,《蚁人2》作为一部老少咸宜的喜剧科幻电影,虽然在剧情上有所不足,但是总体来讲算是一部广受欢迎的高分之作,可以说是一家老小周末欢聚时可选的佳作。
更多精彩文章
Python数据分析实战之北京二手房房价分析
Python能用来做什么?以下是Python的三大主要用途
我是如何通过Web爬虫找工作的
用Python告诉你深圳房租有多高?
用Python分析深圳程序员工资有多高?
Python爬虫实战(批量采集Stock数据,并保存到Excel中)

扫一扫关注我们,
更多文章早知道!