《利用Python进行数据分析》学习笔记 第2章 Python语法基础,IPython和Jupyter Notebooks
第2章 Python语法基础,IPython和Jupyter Notebooks
2.1 Python解释器
Python是解释性语言。Python解释器同一时间只能运行一个程序的一条语句。
要退出Python解释器返回终端,可以输入exit()或按Ctrl-D。
2.2 IPython基础
- 运行IPython Shell
可以通过输入代码并按Return(或Enter),运行任意Python语句。IPython还支持执行任意代码块(通过复制-粘贴方法)和整段Python脚本的功能。
- 运行Jupyter Notebook
notebook是Jupyter项目的重要组件之一,它是一个代码、文本(有标记或无标记)、数据可视化或其它输出的交互式文档。Jupyter Notebook需要与内核互动,内核是Jupyter与其它编程语言的交互编程协议。Python的Jupyter内核是使用IPython。要启动Jupyter,在命令行中输入jupyter notebook:
- Tab补全
从外观上,IPython shell和标准的Python解释器只是看起来不同。IPython shell的进步之一是具备其它IDE和交互计算分析环境都有的tab补全功能。在shell中输入表达式,按下Tab,会搜索已输入变量(对象、函数等等)的命名空间。
默认情况下,IPython会隐藏下划线开头的方法和属性,这些也可以tab补全,但是你必须首先键入一个下划线才能看到它们。
除了补全命名、对象和模块属性,Tab还可以补全其它的。当输入看似文件路径时(即使是Python字符串),按下Tab也可以补全电脑上对应的文件信息。
- 自省
在变量前后使用问号?,可以显示对象的信息。
如果对象是一个函数或实例方法,定义过的文档字符串,也会显示出信息。假设我们写了一个如下的函数:
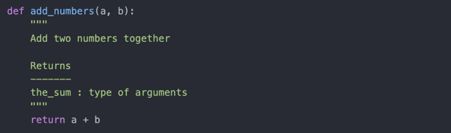
然后使用?符号,就可以显示如下的文档字符串:
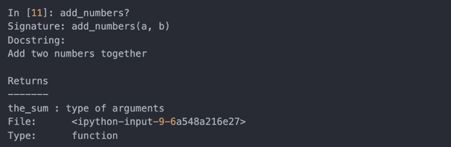
使用??会显示函数的源码:
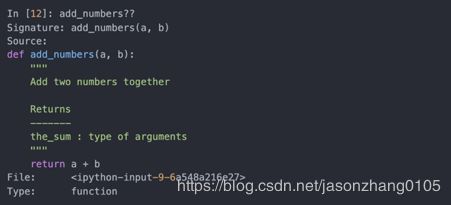
?还有一个用途,就是像Unix或Windows命令行一样搜索IPython的命名空间。字符与通配符结合可以匹配所有的名字。例如,我们可以获得所有包含load的顶级NumPy命名空间:

- %run命令
可以用%run命令运行所有的Python程序。
如果一个Python脚本需要命令行参数(在sys。argv中查找),可以在文件路径之后传递,就像在命令行上运行一样。
如果想让一个脚本访问IPython已经定义过的变量,可以使用%run -i。
在Jupyter notebook中,你也可以使用%load,它将脚本导入到一个代码格中:

- 中断运行的代码
代码运行时按Ctrl-C,无论是%run或长时间运行命令,都会导致KeyboardInterrupt。这会导致几乎所有Python程序立即停止,除非一些特殊情况。
警告:当Python代码调用了一些编译的扩展模块,按Ctrl-C不一定将执行的程序立即停止。在这种情况下,你必须等待,直到控制返回Python解释器,或者更糟糕的情况下强制终止Python进程。
- 从剪切板执行程序
若使用Jupyter notebook,可以将代码复制粘贴到任意代码格执行。在IPython shell中也可以从剪贴板执行。假设在其它应用中复制了如下代码:

最简单的方法是使用%paste和%cpaste函数。%paste可以直接运行剪贴板中的代码:

%cpaste功能类似,但会给出一条提示:
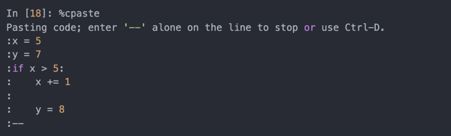
使用%cpaste可以粘贴任意多的代码再运行。若粘贴了错误代码,可以用Ctrl-C中断。
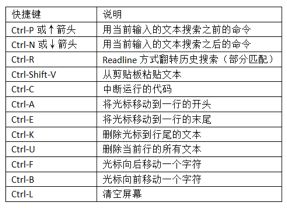
- 键盘快捷键
IPython有许多键盘快捷键进行导航提示(类似Emacs文本编辑器或UNIX bash Shell)和交互shell的历史命令。

- 魔术命令
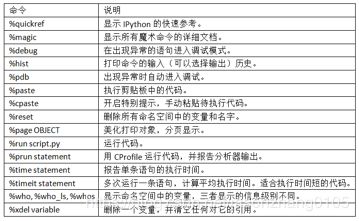
IPython中特殊的命令(Python中没有)被称作“魔术”命令。这些命令可以使普通人物更便捷,更容易控制IPython系统。魔术命令是在指令前添加百分号%前缀。例如,可以用%timeit测量任何Python语句,例如矩阵乘法的执行时间:

魔术命令可以被看做IPython中运行的命令行。许多魔术命令有“命令行”选项,可以通过?查看。
魔术函数默认可以不用百分号,只要没有变量和函数名相同。这个特点被称为“自动魔术”,可以用%automagic打开或关闭。
一些魔术函数与Python函数很像,它的结果可以赋值给一个变量:
- 集成Matplotlib
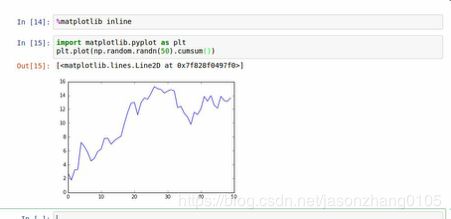
在IPython shell中,运行%matplotlib可以进行设置,可以创建多个绘图窗口,而不会干扰控制台session:
![]()
在JUpyter中,命令有所不同:
2.3 Python语法基础
- 语言的语义
Python的语言设计强调的是可读性、简洁和清晰。有些人称Python为“可执行的伪代码”。
- 使用缩进,而不是括号
Python使用空白字符(tab和空格)来组织代码,而不是像其他语言,比如R、C++、JAVA和Perl那样使用括号。看一个排序算法的for循环:

冒号标志着缩进代码块的开始,冒号之后的所有代码的缩进量必须相同,直到代码块结束。
Python的语句不需要用分号结尾。但是分号却可以用来给同在一行的语句切分:
![]()
- 函数和对象方法调用
可以用圆括号调用函数,传递零个或几个参数,或者将返回值给一个变量:
![]()
几乎Python中的每个对象都有附加的函数,称作方法,可以用来访问对象的内容。可以用下面的语句调用:
![]()
函数可以使用位置和关键词参数:
![]()
- 变量和参数传递
当在Python中创建变量(或名字),你就在等号右边创建了一个对这个变量的引用。考虑一个整数列表:
![]()
假设将a赋值给一个新变量b:
![]()
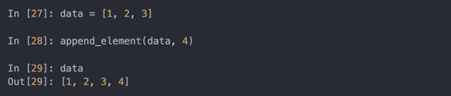
在a中添加一个元素,然后检查b:

当你将对象作为参数传递给函数时,新的局域变量创建了对原始对象的引用,而不是复制。如果在函数里绑定一个新对象到一个变量,这个变动不会反映到上一层。因此可以改变可变参数的内容。假设有以下函数:
![]()
然后有:
- 动态引用,强类型
与许多编译语言(如JAVA和C++)对比,Python中的对象引用不包含附属的类型。下面的代码是没有问题的:

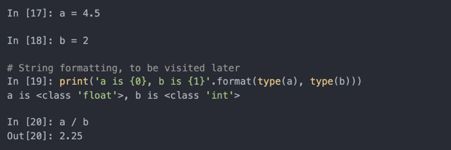
变量是在特殊命名空间中的对象的名字,类型信息保存在对象自身中。一些人可能会说Python不是“类型化语言”。这是不正确的,看下面的例子:

在某些语言中,例如Visual Basic,字符串’5’可能被默许转换(或投影)为整数,因此会产生10。但在其它语言中,例如JavaScript,整数5会被投射成字符串,结果是联结字符串’55’。在这个方面,Python被认为是强类型化语言,意味着每个对象都有明确的类型(或类),默许转换只会发生在特定的情况下,例如:
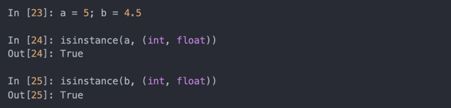
知道对象的类型很重要,最好能让函数可以处理多种类型的输入。可以用isinstance函数检查对象是某个类型的实例:

isinstance可以用类型元组,检查对象的类型是否在元组中:
- 属性和方法
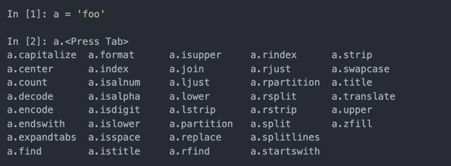
Python的对象通常都有属性(其它存储在对象内部的Python对象)和方法(对象的附属函数可以访问对象的内部数据)。可以用obj.attribute_name访问属性和方法:
也可以用getattr函数,通过名字访问属性和方法:
![]()
在其它语言中,访问对象的名字通常称作“反射”。本书不会大量使用getattr函数和相关的hasattr和setattr函数,使用这些函数可以高效编写原生的、可重复使用的代码。
- 鸭子类型
经常地,你可能不关心对象的类型,只关心对象是否有某些方法或用途。这通常被称为“鸭子类型”,来自:走起来像鸭子、叫起来像鸭子,那么它就是鸭子”的说法。例如,你可以通过验证一个对象是否遵循迭代协议,判断它是可迭代的。对于许多对象,这意味着它有一个__iter__魔术方法,其它更好的判断方法是使用iter函数:

这个函数会返回字符串以及大多数Python集合类型为True:
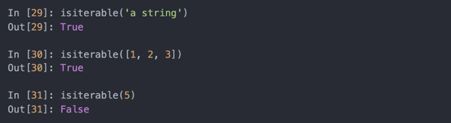
可以用这个功能编写可以接受多种输入类型的函数。常见的例子是编写一个函数可以接受任意类型的序列(list、tuple、ndarray)或是迭代器。你可先检验对象是否是列表(或是NumPy数组),如果不是的话,将其转变成列表:
![]()
- 引入
在Python中,模块就是一个有.py扩展名、包含Python代码的文件。假设有一下模块:

如果想从同目录下的另一个文件访问some_module.py中定义的变量和函数,可以:

或者:
![]()
使用as关键词,可以给引入起不同的变量名:

- 二元运算符和比较运算符
大多数二元数学运算和比较都不难想到:

要判断两个引用是否指向同一个对象,可以使用is方法,is not可以判断两个对象是否不同的:

因为list总是创建一个新的Python列表(即复制),可以断定c是不同于a的。使用is比较与==运算符不同,如下:
![]()
is和is not常用来判断一个变量是否为None,因为只有一个None的实例:

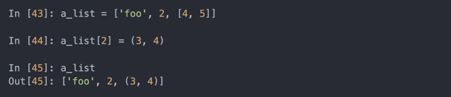
- 可变与不可变对象
Python中的大多数对象,比如列表、字典、NumPy数组,和用户定义的类型(类),都是可变的。意味着这些对象或包含的值可以被修改:
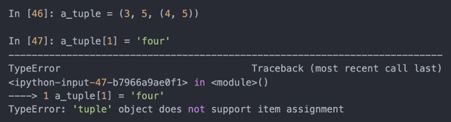
其它的,例如字符串和元组,是不可变的:
记住,可以修改一个对象并不意味就要修改它。这被称为副作用。例如,当写一个函数,任何副作用都要在文档或注释中写明。一般推荐避免副作用,采用不可变的方式,即使要用到可变对象。
- 标量类型
Python的标准库中有一些内建的类型,用于处理数值数据、字符串、布尔值,和日期时间。这些单值类型被称为标量类型,本书中称其为标量。下表列出了主要的标量。

- 数值类型
Python的主要数值类型是int和float。int可以存储任意大的数:

浮点数使用Python的float类型。每个数都是双精度(64位)的值。也可以用科学计数法表示:

不能得到整数的除法会得到浮点数:
![]()
要获得C-风格的整除(去掉小数部分),可以使用底除运算符//:

- 字符串
可以用单引号或双引号来写字符串:
![]()
对于有换行符的字符串,可以使用三引号,’’’或“”“都行:

字符串c实际包含四行文本,“”“后面和lines后面的换行符。可以用count方法计算c中的新的行:
![]()
Python的字符串是不可变的,不能修改字符串:
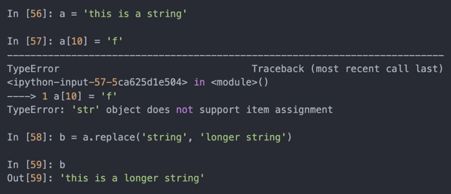
经过以上的操作,变量a并没有被修改:
![]()
许多Python对象使用str函数可以被转化为字符串:

字符串是一个序列的Unicode字符,因此可以像其它序列,比如列表和元组一样处理:
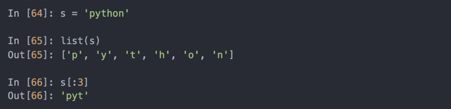
反斜杠是转义字符,意思是它被用来表示特殊字符,比如换行符\n或Unicode字符。要写一个包含反斜杠的字符串,需要进行转义:

若字符串中包含许多反斜杠,但没有特殊字符,这样做就很麻烦。幸好,可以在字符串前面加一个r,表明字符就是它自身:

r表示raw。
将两个字符串合并,会产生一个新的字符串:
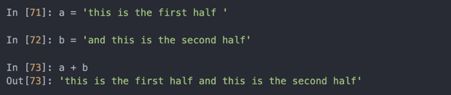
字符串的模板化或格式化,是另一个重要的主题。字符串对象有format方法,可以替换格式化的参数为字符串,产生一个新的字符串:
![]()
在这个字符串中,
- {0:.2f}表示格式化第一个参数为带有两位小数的浮点数。
- {1:s}表示格式化第二个参数为字符串。
- {2:d}表示格式化第三个参数为一个整数。
要替换参数为这些格式化的参数,我们传递format方法一个序列:
![]()
- 字节和Unicode
在Python 3及以上版本中,Unicode是一级的字符串类型,这样可以更一致的处理ASCll和Non-ASCll文本。在老的Python版本中,字符串都是字节,不使用Unicode编码。假如知道字符编码,可以将其转化为Unicode。一个例子:

可以用encode将这个Unicode字符串编码为UTF-8:
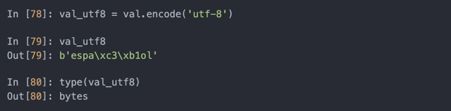
若知道一个字节对象的Unicode编码,用decode方法可以解码:
![]()
虽然UTF-8编码已经变成主流,但因为历史的原因,仍然可能碰到其它编码的数据:
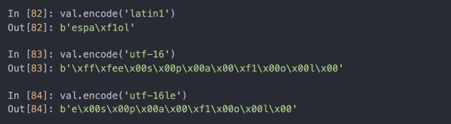
工作中碰到的文件很多都是字节对象,盲目地将所有数据编码为Unicode是不可取的。虽然用的不多,但是可以在字节文本的前面加上一个b:
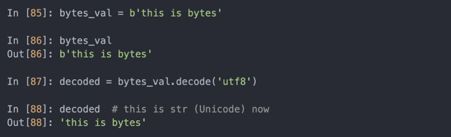
- 布尔值
Python中的布尔值有两个,True和False。比较和其它条件表达式可以用True和False判断。布尔值可以与and和or结合使用:

- 类型转换
str、bool、int和float也是函数、可以用来转换类型:
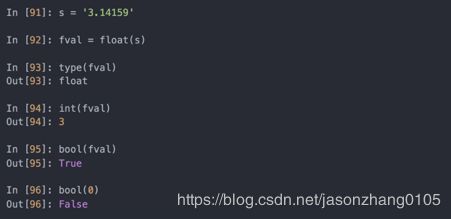
- None
None是Python的空值类型。如果一个函数没有明确的返回值,就会默认返回None:

None也常常作为函数的默认参数:
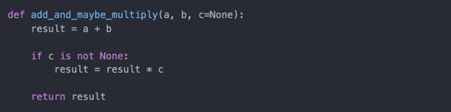
另外,None不仅是一个保留字,还是唯一的NoneType的实例:
![]()
- 日期和时间
Python内建的datetime模块提供了datetime、date和time类型。datetime类型结合了date和time,是最常使用的:
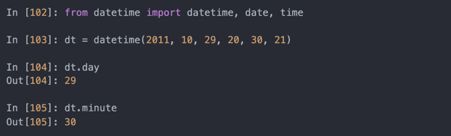
根据datetime实例,可以用date和time提取出各自的对象:

strftime方法可以将datetime格式化为字符串:
![]()
strptime可以将字符串转换成datetime对象:
![]()
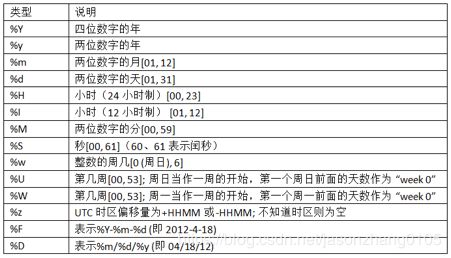
下表列出了所有的格式化命令:
当聚类或对时间序列进行分组,替换datetimes的time字段有时会很有用。例如,用0替换分和秒:
![]()
因为datetime.datetime是不可变类型,上面的方法会产生新的对象。
两个datetime对象的差会产生一个datetime.timedelta类型:
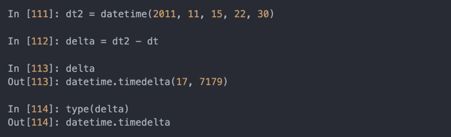
结果timedelta(17,7179)指明了timedelta将17天、7179秒的编码方式。
将timedelta添加到datetime,会产生一个新的偏移datetime:

- 控制流
Python有若干内建的关键字进行条件逻辑、循环和其它控制流操作。
- if、elif和else
if是最广为人知的控制流语句。它检查一个条件,如果为True,就执行后面的语句:
![]()
if后面可以跟一个或多个elif,所有条件都是False时,还可以添加一个else:
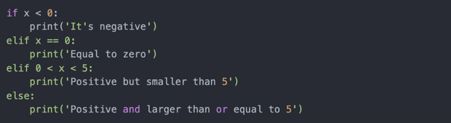
若某个条件为True,后面的elif就不会被执行。当使用and和or时,复合条件语句是从左到右执行:
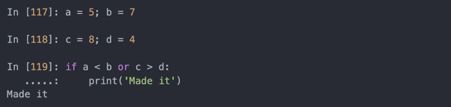
在这个例子中,c>d不会被执行,因为第一个比较是True。
也可以把比较式串在一起:
![]()
- for循环
for循环是在一个集合(列表或元组)中进行迭代,或者就是一个迭代器。for循环的标准语法是:
![]()
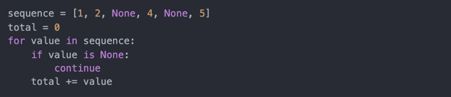
可以用continue使for循环提前,跳过剩下的部分。下面这个例子将一个列表中的整数相加,跳过None:
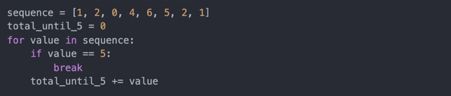
可以用break跳出for循环。下面的代码将各元素相加,直到遇到5:
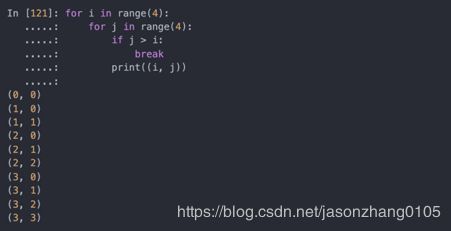
break只中断for循环的最内层,其余的for循环仍会运行:
若集合或迭代器中的元素序列(元组或列表),可以用for循环将其方便地拆分成变量:
![]()
- While循环
while循环指定了条件和代码,当条件为False或用break退出循环,代码才会退出:

- pass
pass是Python中的非操作语句。代码块不需要任何动作时可以使用(作为未执行代码的占位符);因为Python需要使用空白字符划定代码块,所以需要pass:
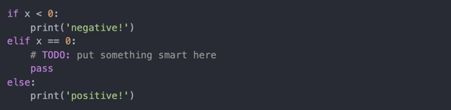
- range
range函数返回一个迭代器,它产生一个均匀分布的整数序列:

range的三个参数是(起点,终点,步进):

可以看到,range产生的整数不包括终点。range的常见用法是用序号迭代序列:

可以使用list来存储range在其他数据结构中生成的所有整数,默认的迭代器形式通常是你想要的。下面的代码对0到99999中3或5的倍数求和:

虽然range可以产生任意大的数,但任意时刻耗用的内存却很小。
- 三元表达式
Python中的三元表达式可以将if-else语句放在一行里。语法如下:
![]()
true-expr或false-expr可以是任何Python代码。它和下面的代码效果相同:

下面是一个更具体的例子:

和if-else一样,只有一个表达式会被执行。因此,三元表达式中的if和else可以包含大量的计算,但只有True的分支会被执行。
虽然使用三元表达式可以压缩代码,但会降低代码可读性。