yolov3 详解和C源码分析
检测部分 函数为 test_detector 这里主要研究cpu操作,下一篇会记录gpu的实现和cuda编程
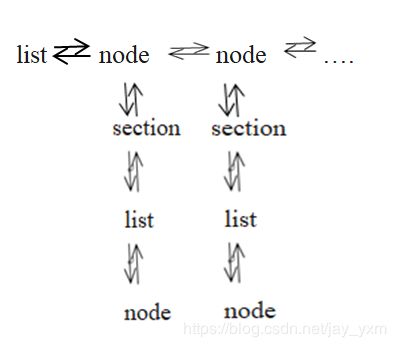
1、读取文件
list *options = read_data_cfg(datacfg);//读取coco.data文件内容,放入双向链表里面,
//逐行读取等号两边字符串放入kvp中,kvp存放在node中,list和node形成双向链表。
char *name_list = option_find_str(options, "names", "data/names.list");
//根据options ,返回names路径
char **names = get_labels_custom(name_list, &names_size);
//返回二维指针包含类名得字符串链表
image **alphabet = load_alphabet();//图例
2、初始化网络
network net = parse_network_cfg_custom(cfgfile, 1, 1);
//整个网络的初始化,分配内存空间
list *sections = read_cfg(filename);
//读取.cfg后缀的文件,形成双向链表
parse_net_options(options, &net);//根据文件内容,对net初始化
对cfg 文件部分参数理解:
https://blog.csdn.net/jay_yxm/article/details/102938222
load_weights(&net, weightfile);//加载权重文件
计算前向的BN层参数:
fuse_conv_batchnorm;//计算检测时batchnorm的
BN在每一层计算的 ![]() 与
与 ![]() 都是基于当前batch中的训练数据,但是这就带来了一个问题:在预测阶段,有可能只需要预测一个样本或很少的样本,没有像训练样本中那么多的数据,此时
都是基于当前batch中的训练数据,但是这就带来了一个问题:在预测阶段,有可能只需要预测一个样本或很少的样本,没有像训练样本中那么多的数据,此时 ![]() 与
与 ![]() 的计算一定是有偏估计,所以检测时的计算方法是:
的计算一定是有偏估计,所以检测时的计算方法是:
利用BN训练好模型后,我们保留了每组mini-batch训练数据在网络中每一层的 ![]() 与
与 ![]() 。此时我们使用整个样本的统计量来对Test数据进行归一化,具体来说使用均值与方差的无偏估计:
。此时我们使用整个样本的统计量来对Test数据进行归一化,具体来说使用均值与方差的无偏估计:

得到每个特征的均值与方差的无偏估计后,我们对test数据采用同样的normalization方法:
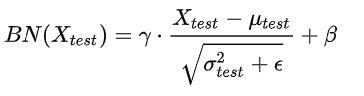
另外,除了采用整体样本的无偏估计外。吴恩达在Coursera上的Deep Learning课程指出可以对train阶段每个batch计算的mean/variance采用指数加权平均来得到test阶段mean/variance的估计。
3、predict 前向计算部分
convolution层
(1)im2co函数 卷积计算用到了im2col函数(https://github.com/BVLC/caffe/blob/master/src/caffe/util/im2col.cpp),im2col将滑动窗口内的数据别为列向量,重组为一个矩阵。这个算法主要考虑cpu或者gpu访问内存的速度,访问相近内存的速度最快,可以加速矩阵乘法计算。(https://mp.csdn.net/postedit/102956491)。
(2)参数dilation 在程序里值为1相当于并没有使用,这个参数可以设为其他值使用膨胀卷积,比如让卷积核从3*3变为5*5空余位置填0,这样的好处就是可以增大感受野,增大感受野一般使用maxpooling,但maxpooling会丢失信息,详细可以参考(https://www.cnblogs.com/pinking/p/9192546.html)
(3)gemm矩阵乘法 这里的卷积运算为了加速使用了Intel AVX指令集。cpuid()这里主要用来判断CPU支持的指令集。这里是intel指令集介绍和使用的官方文档(https://software.intel.com/en-us/articles/introduction-to-intel-advanced-vector-extensions/)。这里主要是在cpu情况下运行的用到的
shorcut层
就是实现残差组件,输出层与往上第三层相加(from=-3),解决梯度发散同时也是特征重用
[shortcut]
from=-3 //往上第三个层相加
activation=linear //什么也不做
//尺度相同可以直接相加
for(i = 0; i < size; ++i)
l.output[i] = state.input[i] + state.net.layers[l.index].output[i];
//尺度不同需要做个缩放再相加
int out_index = i*sample + w2*(j*sample + h2*(k + c2*b));
int add_index = i*stride + w1*(j*stride + h1*(k + c1*b));
out[out_index] += add[add_index];-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
route 层
也叫路由层 就是将几个不同层拼接在一起,yolov3采用多尺度特征检测的方式,分别在79层、91层、106层的特征图进行对象检测,对原图进行32被下采样得到79层特征图,然后第79层做上采样与第61层特征图融合得到91层,相对于原图是16倍的下采样。之后第91层做上采样并于第36层特征图融合得到第106层,相当于原图的8倍下采样。分别对应的感受野由大到小,感受野大的特征图可以检测尺寸较大的对象,感受野小的尺寸用来检测尺寸较小的对象。route层也就是用来不同层做特征融合的。
[route]
layers = -1, 79
void forward_route_layer(const route_layer l, network_state state)
{
int i, j;
int offset = 0;
for(i = 0; i < l.n; ++i){
int index = l.input_layers[i];
float *input = state.net.layers[index].output;
int input_size = l.input_sizes[i];
for(j = 0; j < l.batch; ++j){
copy_cpu(input_size, input + j*input_size, 1, l.output + offset + j*l.outputs, 1);
}
offset += input_size;
}
}
在 resize_route_layer(route_layer *l, network *net)函数里面
if(next.out_w == first.out_w && next.out_h == first.out_h){
l->out_c += next.out_c;
}else{
printf("%d %d, %d %d\n", next.out_w, next.out_h, first.out_w, first.out_h);
l->out_h = l->out_w = l->out_c = 0;
}从resize_route_layer函数里面可以看到如果两个输入层的宽高分别对应相等,直接连接在一起,不同的话认为有错误令w,h,c为0,丢弃routelayer层。如果输入层为64*64*256 和64*64*128 则route layer输出为:64*64*(484).
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
upsample layer 上采样层
将32倍下采样的特征图分别上采样到相当于原图下采样的16倍和8倍。
[upsample]
stride=2 //步长
void upsample_cpu(float *in, int w, int h, int c, int batch, int stride, int forward, float scale, float *out)
{
int i, j, k, b;
for (b = 0; b < batch; ++b) {
for (k = 0; k < c; ++k) {
for (j = 0; j < h*stride; ++j) {
for (i = 0; i < w*stride; ++i) {
int in_index = b*w*h*c + k*w*h + (j / stride)*w + i / stride;
int out_index = b*w*h*c*stride*stride + k*w*h*stride*stride + j*w*stride + i;
if (forward) out[out_index] = scale*in[in_index];
else in[in_index] += scale*out[out_index];
}
}
}
}
}代码里上采样的方式直接采用最近邻插值,赋值就行
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
yolo层
前面主干网络也就是darknet网络得到了三种尺度的特征图(13*13,26*26,52*52),之后yolo层负责计算回归框预测类别;yolov3和yolov2一样采用了k-means聚类的方法获得先验框,yolov3采用三种尺度特征检测,每种尺度给出三个尺寸先验框总共9个。具有较大感受野的特征图使用较大的尺寸,较小的感受野就是用较小的尺寸。
看参数列表
[yolo]
mask = 0,1,2 // 该层预测哪个规模的框,0,1,2表示预测小物体
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
//9种先验框尺寸
//这里具有较大感受野的特征图使用较大的尺寸,较小的感受野就是用较小的尺寸
classes=20 //分类数目
num=9
jitter=.3 //数据增强
//利用数据抖动产生更多数据,YOLOv2中使用的是crop,filp,以及net层的angle,flip是随机的,
//jitter就是crop的参数,tiny-yolo-voc.cfg中jitter=.3,就是在0~0.3中进行crop
ignore_thresh = .5 //正样本阈值
//决定是否需要计算IOU误差的参数,大于thresh,IOU误差不会夹在cost function中
truth_thresh = 1 //完全预测正确样本
random=1 //如果为1,每次迭代图片大小随机从320到608,步长为32,如果为0,每次训练大小与输入大小一致yolo层的主要函数
layer make_yolo_layer //yolo层的初始化
box get_yolo_box //得到预测的边界框
float delta_yolo_box //计算预测边界框的误差
void delta_yolo_class //计算类别误差
static int entry_index //计算指针偏移量,即入口需要的索引
void forward_yolo_layer //前向传播
void correct_yolo_boxes //调整预测 box 中心和大小
int yolo_num_detections //预测输出中置信度超过阈值的 box 个数box get_yolo_box(float *x, float *biases, int n, int index, int i,
int j, int lw, int lh, int w, int h, int stride)float *x 是前一个卷积层的输出,也是yolo层的输入,对于13*13的特征图输出的大小是 13*13*3*(classes+4+1),biases里保存的是聚类得到的预选框的尺寸,lw和lh是特征图大小,w和h是原图尺寸。get_yolo_box从结果里提取目标框bx,by,bw,bh并且做了归一化,是的4个值位于【0,1】之间。因为x里面包括了4个坐标和1个边框置信度以及80个类别概率,概率当然是0到1之间的,左右这里将坐标值归一化,使得训练更容易收敛。yolo层整个还是比较复杂的,后面会写个详细的分析。这里的有个博客说的很详细,但是也有些觉得不是很准确的地方(https://blog.csdn.net/qq_34199326/article/details/84109828)。
void delta_yolo_class 函数计算分类误差 这里面有focal loss参数,设置为1可以使用focal loss方法计算交叉熵损失函数,这个方法用来解决正负样本不平衡的问题,focalloss算法认为one stage精度低于twostage方法的主要原因是正负样本的不平衡,也就是会有大量的背景样本,会产生许多的易分类样本(easy example),这些样本主导了梯度更新的方向进而难以准确的对目标进行分类,two stage中的rpn可以解决这个问题,focal loss在原损失函数公式的基础上做了改进
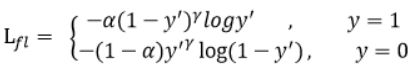
添加了alpha和gamma两个因子,gamma减少易分类样本的损失,alpha来平衡正负样本间的比列问题。总得来说就是通过在交叉熵损失函数上的改进,减少负样本在损失函数的比重,解决正负样本不平衡的问题。
float delta_yolo_box 函数计算回归框误差 源码中给了两种方法,一个就是MSE(均方误差),也就是真实值与预测值差值平方的期望这个比较简单,另一个称作GIOU(Generalized Intersection over Union),主要弥补在两个边界框没有重叠的情况下,IOU不能作为损失函数,因为IOU为0梯度也为0,无法反向计算去优化模型参数,另外IOU并不能知道两个边框的重叠方式,仅仅知道重叠面积。但事实上相同重叠面积两个边界框也可以有不同的排列方式。所以GIOU就可以知道两个回归框的重叠方式。(https://arxiv.org/abs/1902.09630v2)可以参考文章。