MySQL高性能索引(视频链接:https://pan.baidu.com/s/1_aGwTIs3hfmhC71e-zkhFg 提取码:j8dr)
文章目录
- 1.三和一万
- 2.索引原理
- 3.B-Tree索引
- 4.Hash索引
- 5.聚簇索引
- 5.1.数据存储结构
- 5.2.数据查询过程
- 5.3.二级索引的查询过程
- 6.基于索引的sql优化
1.三和一万
索引(在MYSQL中也叫做键),是存储引擎用于快速找到记录的一种数据结构。
索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点。考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储100条记录。
如果没有索引,查询将对整个表进行扫描,最坏的情况下,如果所有数据页都不在内存,需要读取104个页面,如果这104个页面在磁盘上随机分布,需要进行10^4次I/O,假设磁盘每次I/O时间为10ms(忽略数据传输时间),则总共需要100s(但实际上要好很多很多)。
如果对之建立B-Tree索引,则只需要进行log100(10^6)=3次页面读取,最坏情况下耗时30ms。这就是索引带来的效果,很多时候,当你的应用程序进行SQL查询速度很慢时,应该想想是否可以建索引。
2.索引原理

首先根据索引值,此处为id值,查询索引数据,找到对应id的表数据的逻辑地址;
Cpu将逻辑地址发给硬盘控制器,读取数据页。
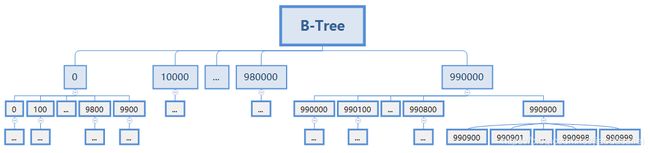
3.B-Tree索引
B-Tree索引:每一个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的范围遍历。B-Tree通常意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同,很适合查找范围数据。

4.Hash索引
哈希索引基于哈希表实现,只有精确索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希存储在索引中,同时在哈希表中保存指向每个数据的指针。
一次IO
5.聚簇索引
是一种B-Tree索引的数据存储方式,MySQL中的主键就是采用该索引。
5.1.数据存储结构

在有聚簇索引表情况(图左):
聚簇索引的叶子节点,存储的是实际的行数据,而不是行数据的地址;
非聚簇索引的叶子节点,存储的是主键值,不是行数据的地址。
在没有聚簇索引表情况(图右):
所有的B-Tree索引的叶子节点,存储的是行数据地址。
5.2.数据查询过程
根据主键值查询:根据B-Tree找到叶子节点,就找到了相应的行数据。
5.3.二级索引的查询过程
根据二级索引(非聚簇索引,外键字段上有二级索引):
首先,根据B-Tree找到叶子节点,获取主键值;
然后,根据其中的主键值再查询主键的聚簇索引获取数据。
6.基于索引的sql优化
Create table user (
Id,
First_name,
Last_name,
…
)
id为主键,具有聚簇索引;
在first_name和last_name上建立二级索引(create index name_index …)
| SQL | 索引使用情况 |
|---|---|
| Select * from user where id = ? | 使用主键的聚簇索引 |
| Select * from user where first_name = ? and … | 使用二级索引name_index |
| Select * from user where last_name = ? - X | 不能使用索引 |
| Select * from user where first_name = ? and last_anme = ? | 使用二级索引name_index |
| Select * from user where last_anme = ? and first_name = ? -X | 不能使用索引 |
| Select * from user where first_name like ‘%xxx’ - X | 不能使用索引 |
| Select * from user where last_name like ‘xxx%’ | 使用二级索引name_index |
| Select * from user where first_name = ? and last_name like ‘%YYY’ | 第一个字段可以使用二级索引name_index,第二个不能使用索引 |
| Select * from user where first_name = ? and last_name like ‘YYY%’ | 使用二级索引name_index |
Select id,first_name,last_name from user where first_name = ? and last_name = ?
在name_index中,其叶子节点中,存储的是:id值,first_name,last_name
所以,上述查询时,根据查询条件,使用B-Tree索引name_index找到叶子节点,之后因为已经包含了所有返回字段的数据,故不会再次根据id值去查询聚簇索引。
建立主键时,采用自增长id,还是uuid?
前者是顺序IO,后者是随机IO,所以前者性能好
Select * from t_goods where id in (1,4,8,6,5); - 随机IO
Select * from t_goods where id in (1,4,5,6,8); - 顺序IO