python-web客户端工具
浏览器只是 Web 客户端的一种。任何一个向 Web 服务器端发送请求来获得数据的应用程序都是“客户端”。也可以创建其他的客户端,来在因特网上检索出文档和数据。客户端程序可以完成更多的工作,不仅可以下载数据,还可以存储、操作数据,甚至可以将其传送到另外一个地方或者传给另外一个应用。
使用 urllib 模块下载或者访问 Web 上信息的应用程序(使用 urllib.urlopen()或者 urllib.urlretrieve())就是简单的 Web 客户端。
一、统一资源定位符
简单的网页浏览需要用到名为 URL(统一资源定位符)的 Web 地址。这个地址用来在 Web上定位一个文档,或者调用一个 CGI 程序来为客户端生成一个文档。 URL 是多种统一资源标识符(Uniform Resource Identifier, URI) 的一部分。
一个 URL 是一个简单的 URI,它使用已有的协议或方案(即 http、 ftp 等),作为地址的一部分。为了更完整地描述,还要介绍非 URL 的 URI,有时它们称为统一资源名称(Uniform Resource Name, URN),但是现在唯一使用的 URI 只有 URL
prot_sch://net_loc/path;params?query#frag
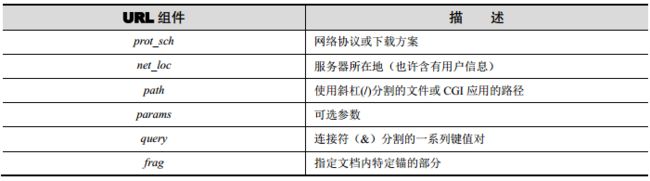
net_loc 可以进一步拆分成多个组件,一些是必备的,另一些是可选的。 net_loc 字符串如下。
user:passwd@host:port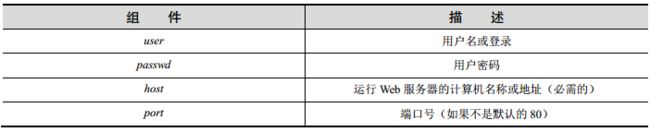
在这 4 个组件中, host 名是最重要的。 port 号只有在 Web 服务器运行其他非默认端口号上时才会使用.用户名和密码只有在使用 FTP 连接时候才有可能用到,而即便使用 FTP,大多数的连接都是匿名的,这时不需要用户名和密码。
Python 支持两种不同的模块,两者分别以不同的功能和兼容性来处理 URL。一种是urlparse,另一种是 urllib。
二、urlparse 模块
urlpasrse 模块提供了一些基本功能,用于处理 URL 字符串。这些功能包括 urlparse()、urlunparse()和 urljoin()。urlparse()将 URL 字符串拆分成前面描述的一些主要组件。其语法结构如下。
urlparse (urlstr, defProtSch=None, allowFrag=None)
urlparse()将 urlstr 解析成一个 6 元组(prot_sch, net_loc, path, params, query, frag)。如果 urlstr 中没有提供默认的网络协议或下载方案, defProtSch 会指定一个默认的网络协议。allowFrag 标识一个 URL 是否允许使用片段。
urlunparse()的功能与 urlpase()完全相反,其将经 urlparse()处理的 URL 生成 urltup 这个 6元组(prot_sch, net_loc, path, params, query, frag),拼接成 URL 并返回。
urlunparse(urlparse(urlstr)) ≡ urlstr
在需要处理多个相关的 URL 时我们就需要使用 urljoin()的功能了,例如,一个 Web 页中可能会产生一系列页面 URL。 urljoin()的语法是如下。
urljoin (baseurl, newurl, allowFrag=None)
urljoin()取得根域名,并将其根路径(net_loc 及其前面的完整路径,但是不包括末端的文件)与 newurl 连接起来。
>>> urlparse.urljoin('http://www.python.org/doc/FAQ.html',
... 'current/lib/lib.htm')
'http://www.python.org/doc/current/lib/lib.html'
三、urllib模块和包
urllib提供了一个高级的 Web 通信库,支持基本的 Web 协议,如 HTTP、 FTP 和 Gopher 协议,同时也支持对本地文件的访问。具体来说, urllib 模块的功能是利用前面介绍的协议来从因特网、局域网、本地主机上下载数据。在 Python 3 中,所有这些相关
模块都整合进了一个名为 urllib 的单一包中。 urlib 和 urlib2 中的内容整合进了 urlib.request模块中, urlparse 整合进了 urllib.parse 中。 Python 3 中的 urlib 包还包括 response、 error 和robotparse 这些子模块。
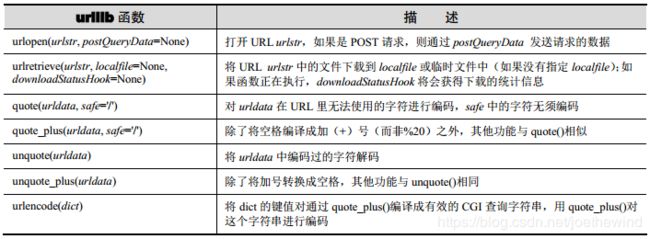
1)urlopen()
urlopen()打开一个给定 URL 字符串表示的 Web 连接,并返回文件类型的对象。语法结构如下。
urlopen (urlstr, postQueryData=None)
对于所有的 HTTP 请求,常见的请求类型是“GET”。在这些情况中,向 Web 服务器发送的请求字符串(编码过的键值对,如 urlencode()函数返回的字符串)应该是 urlstr 的一部分。如果使用“POST”请求方法,请求的字符串(编码过的)应该放到 postQueryData 变量中。
在python3中,表示如下
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
其中,data默认是None,此时以GET方式发送请求;当用户给出data参数的时候,改为POST方式发送请求。timeout:设置网站的访问超时时间。直接用urllib.request模块的urlopen()获取页面,page的数据格式为bytes类型,需要decode()解码,转换成str类型。
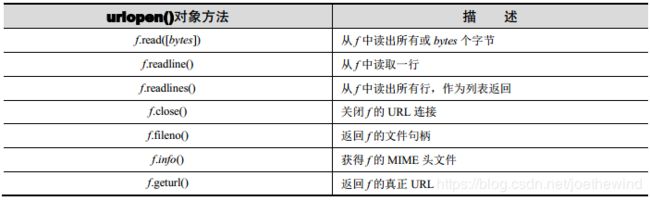
一旦连接成功, urlopen()将会返回一个文件类型对象,就像在目标路径下打开了一个可读文件。例如,如果文件对象是 f,那么“句柄”会支持一些读取内容的方法,如 f.read()、f.readline()、 f.readlines()、 f.close()和 f.fileno()。
此外, f.info()方法可以返回 MIME(Multipurpose Internet Mail Extension,多目标因特网邮件扩展)头文件。这个头文件通知浏览器返回的文件类型,以及可以用哪类应用程序打开。例如,浏览器本身可以查看 HTML、纯文本文件、渲染 PNG(Portable Network Graphics)文件、 JPEG(Joint Photographic Experts Group)或者 GIF(Graphics Interchange Format)文件。而其他如多媒体或特殊类型文件需要通过其他应用程序才能打开。
2)urlretrieve()
urlretrieve()不是用来以文件的形式访问并打开 URL,而是用于下载完整的 HTML,把另存为文件, 其语法如下。
urlretrieve(url, filename=None, reporthook=None, data=None)
urlretrieve()可以方便地将 urlstr中的整个 HTML文件下载到本地硬盘上。下载后的数据可以存成一个 localfile 或者一个临时文件。如果该文件已经复制到本地或者 url 指向的文件就是本地文件,就不会发生后面的下载动作。如果提供了 downloadStatusHook,则在每块数据下载或传输完成后会调用这个函数。调用时使用以下 3 个参数:目前读入的块数、块的字节数和文件的总字节数。
urlretrieve()返回一个二元组(filename, mime_hdrs)。 filename 是含有下载数据的本地文件名, mime_hdrs 是 Web 服务器响应后返回的一系列 MIME 文件头。要获得更多的信息,可以查看 mimetools 模块的 Message 类。对本地文件来说, mime_hdrs 是空的。
3)urllib.quote()和 urllib.quote_plus()
quote*()函数用来获取 URL 数据,并将其编码,使其可以用于 URL 字符串中。必须对某些不能打印的或者不被 Web 服务器作为有效 URL 接收的特殊字符串进行转换。这就是 quote*()函数的功能。 quote*()函数的语法如下。
quote(urldata, safe='/')
逗号、下划线、句号、斜线和字母数字这类符号不需要转化,其他的则均需要转换。另外,那些 URL 不能使用的字符前边会被加上百分号(%)同时转换成十六进制,例如,“%xx”,其中,“xx”表示这个字母的 ASCII 码的十六进制值。当调用 quote*()时, urldata 字符串转换成一个可在 URL 字符串中使用的等价字符串。 safe 字符串可以包含一系列不能转换的字符,默认字符是斜线(/)。
quote_plus()与 quote()很像,只是它还可以将空格编码成“+”号。
4)urllib.urlencode()
urlopen()函数接收字典的键值对,并将其编译成字符串,作为 CGI 请求的 URL 字符串的一部分。键值对的格式是“键=值”,以连接符(&)划分。另外,键及其对应的值会传到quote_plus()函数中进行适当的编码。