【论文系列】论文《Fully Convolutional Networks for Semantic Segmentation》
转载自 博客园 亦轩Dhc 论文笔记《Fully Convolutional Networks for Semantic Segmentation》
最近想着做分割来提取全局特征,有提到两篇 一篇是FCN,一篇是Learning to generate chairs with convolutional neural
这里转载 博主 亦轩Dhc 的博文 包括他对FCN的一些理解
论文笔记《Fully Convolutional Networks for Semantic Segmentation》
一、Abstract
提出了一种end-to-end的做semantic segmentation的方法,也就是FCN,是我个人觉得非常厉害的一个方法。
二、亮点
1、提出了全卷积网络的概念,将Alexnet这种的最后的全连接层转换为卷积层,好处就是可以输入任意的scale。
只不过在输出的scale不同的时候,feature map的大小也不同,因为这里的目的是最piexl的语义分割,所以其实不重要。
在Alexnet基础上, 最后的channel=4096的feature map经过一个1x1的卷积层, 变为channel=21的feature map, 然后经过上采样和crop, 变为与输入图像同样大小的channel=21的feature map, 也就是图中的pixel-wise prediction。 在Longjon的试验中一共有20个语义类别, 加上背景类别每个像素应该有21个softmax预测类, 因此pixel-wise prediction中channel=21。
2、如何做上采样的?
对CNN的输出结果进行upsampling,上采样的参数是可学习的,这里采用的方法是反卷积,其实跟BP的求卷积层的梯度是一样的算法,最后得到一个和原图一样大小的输出,输出结果为对每个像素的分类。
3、如何把全连接层转换为卷积层?
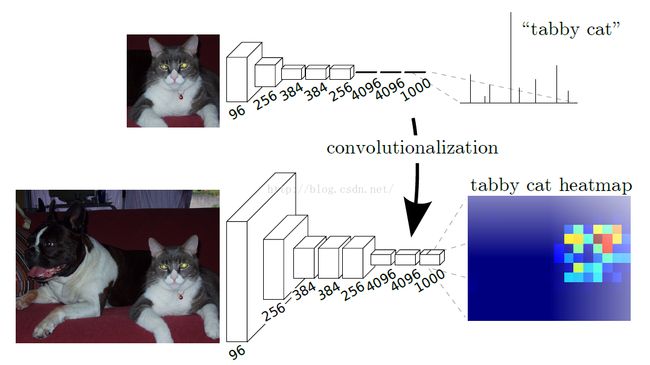
这篇博文写的很好http://blog.csdn.net/u010668083/article/details/46650877,这里有一个概念我之前一直模糊了,把全连接层转换为卷积层,实际上是用一个和输入的图像一样大小的卷积核去做这个操作。对于一个7*7*512的cov输出,连接到一个1*1*4096的全连接层,转换的方法也就是:用4096组滤波器,每组滤波器有512组,每组的大小是7*7的(所以我的理解就是..这个滤波器的大小实际上是7*7*512),这样的话,参数数量一致,最后的输出也是一致的。在输出变大的时候,因为是都是卷积层,最后当然可以得到一个上面那张图的输出。
4.refinement
作者发现,直接这样做效果并不是很好,于是拿出了祖传trick来解决问题了。
如下图所示,在最后upsampling的时候,不只用最后一层,还要结合前面几层一起来做一个fusion,这个很好理解,前面几层的感受野是比较小的,所以在局部的输出结果上是不错的,而后面的输出感受野是越来越大的,可以说准确率会高一点,进行融合以后,效果好的飞起..
三、结论
语义分割方面FCN可以说是开了一个山头了,我觉得这个想法很好,对于之后的instance segmentation也有很大的帮助。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
另有一篇博文的解释也可以参考
网址 http://blog.csdn.net/happyer88/article/details/47205839 博主 July_Zh1
非常给力的!全文中文翻译!(但是还是建议大家读好英文论文)
网址 http://www.cnblogs.com/xuanxufeng/p/6249834.html 博主 一生不可自决
END