【AlexeyAB DarkNet框架解析】十,池化层代码详解(maxpool_layer.c)
已经将所有的注释代码以及包含中文版README的AlexeyAB DarkNet总结在了这个网址上,需要自取:https://github.com/BBuf/Darknet
前言
继续阅读DarkNet的源码,今天主要来讲一下池化层的构造,前向传播,和反向传播。池化层的实现在src/maxpool_layer.c中。
原理
为了图文并茂的解释这个层,我们首先来说一下池化层的原理,池化层分为最大池化以及平均池化。最大池化可以用下图表示:
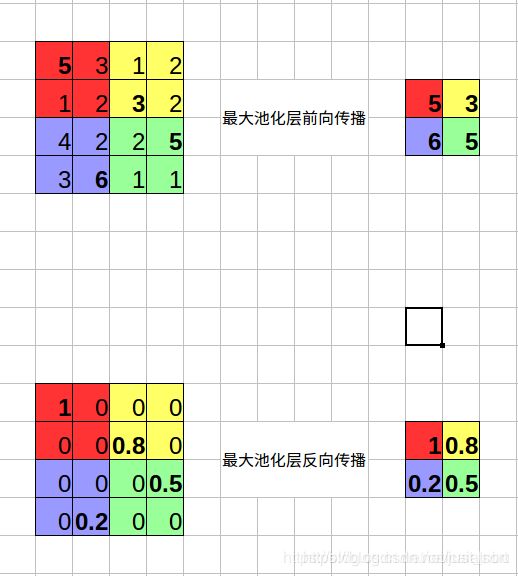
可以看到最大池化层需要记录池化输出特征图的每个值是由原始特征图中哪个值得来的,也就是需要额外记录一个最大值在原图的中的索引。而平均池化只需要将上面的求最大值的操作换成求平均的操作即可,因为是平均操作所以就没必要记录索引了。
池化层的构造
池化层的构造由make_maxpool_layer函数实现,虽然名字是构造maxpool_layer,但其实现也考虑了平均池化,也就是说通过参数设置可以将池化层变成平均池化。这一函数的详细讲解请看如下代码,为了美观,我去掉了一些无关代码,完整代码请到github查看。
/*
** 构建最大/平均池化层
** batch: 该层输入中一个batch所含有的图片张数,等于net.batch
** h,w,c: 该层输入图片的高度,宽度与通道数
** size: 池化核的大小
** stride: 滑动步长
** padding: 四周补0长度
返回: 最大/平均池化层l
*/
maxpool_layer make_maxpool_layer(int batch, int h, int w, int c, int size, int stride_x, int stride_y, int padding, int maxpool_depth, int out_channels, int antialiasing, int avgpool, int train)
{
maxpool_layer l = { (LAYER_TYPE)0 };
//层类别
l.avgpool = avgpool;
if (avgpool) l.type = LOCAL_AVGPOOL;
else l.type = MAXPOOL;
l.train = train;
const int blur_stride_x = stride_x;
const int blur_stride_y = stride_y;
l.antialiasing = antialiasing;
if (antialiasing) {
stride_x = stride_y = l.stride = l.stride_x = l.stride_y = 1; // use stride=1 in host-layer
}
l.batch = batch;//一个batch中包含的图片数
l.h = h; //输入图片的高度
l.w = w; //输入图片的宽度
l.c = c; //输入图片的通道数
l.pad = padding; // 补0的个数
l.maxpool_depth = maxpool_depth; //池化层每隔l.maxpool_depth执行一次pool操作
l.out_channels = out_channels; //输出图片的通道数
if (maxpool_depth) {
l.out_c = out_channels;
l.out_w = l.w;
l.out_h = l.h;
}
else {
l.out_w = (w + padding - size) / stride_x + 1; //输出图片的宽度
l.out_h = (h + padding - size) / stride_y + 1; //输出图片的高度
l.out_c = c; //输出图片的通道数
}
//
l.outputs = l.out_h * l.out_w * l.out_c; //池化化层对应一张输入图片的输出元素个数
l.inputs = h*w*c; //池化层
l.size = size; //池化层池化窗口大小
l.stride = stride_x; //池化层步幅
l.stride_x = stride_x; //在x方向上的池化层步幅
l.stride_y = stride_y; //在y方向上的池化层步幅
int output_size = l.out_h * l.out_w * l.out_c * batch; // 池化层所有输出的元素个数(包含整个batch的)
if (train) {
// 训练的时候,用于保存每个最大池化窗口内的最大值对应的索引,方便之后的反向传播
// 如果是平均池化层就不用了
if (!avgpool) l.indexes = (int*)xcalloc(output_size, sizeof(int));
//池化层的误差项
l.delta = (float*)xcalloc(output_size, sizeof(float));
}
//池化层的所有输出(包含整个batch的)
l.output = (float*)xcalloc(output_size, sizeof(float));
if (avgpool) {
//平均池化层的前向传播和反向传播
l.forward = forward_local_avgpool_layer;
l.backward = backward_local_avgpool_layer;
}
else {
//最大池化层的前向传播和反向传播
l.forward = forward_maxpool_layer;
l.backward = backward_maxpool_layer;
}
// GPU上和CPU上的操作类似
#ifdef GPU
if (avgpool) {
l.forward_gpu = forward_local_avgpool_layer_gpu;
l.backward_gpu = backward_local_avgpool_layer_gpu;
}
else {
l.forward_gpu = forward_maxpool_layer_gpu;
l.backward_gpu = backward_maxpool_layer_gpu;
}
if (train) {
if (!avgpool) l.indexes_gpu = cuda_make_int_array(output_size);
l.delta_gpu = cuda_make_array(l.delta, output_size);
}
l.output_gpu = cuda_make_array(l.output, output_size);
create_maxpool_cudnn_tensors(&l);
if (avgpool) cudnn_local_avgpool_setup(&l);
else cudnn_maxpool_setup(&l);
#endif // GPU
//计算池化层的参数量,以BFLOPs为单位,这是AlexeyAB DarkNet新增的
l.bflops = (l.size*l.size*l.c * l.out_h*l.out_w) / 1000000000.;
return l;
}
最大池化层的前向传播
AlexeyAB DarkNet的池化层和原始的DarkNet的池化层最大的不同在于新增了一个l.maxpool_depth参数,如果这个参数不为0,那么池化层需要每隔l.out_channels个特征图执行最大池化,注意这个参数只对最大池化有效。池化层的前向传播函数为forward_maxpool_layer,详细解释如下:
/*
** 池化层的前向传播函数
** l: 当前层(最大池化层/平均池化层)
** net: 整个网络结构
** 最大池化层处理图像的方式与卷积层类似,也是将最大池化核在图像
** 平面上按照指定的跨度移动,并取对应池化核区域中最大元素值为对应输出元素。
** 最大池化层没有训练参数(没有权重以及偏置),因此,相对与卷积来说,
** 其前向(以及下面的反向)过程比较简单,实现上也是非常直接,不需要什么技巧。
** 但需要注意AlexeyAB DarkNet在原始的代码上改动比较多,具体注释如下。
*/
void forward_maxpool_layer(const maxpool_layer l, network_state state)
{
//如果l.maxpool_depth参数生效,执行下面的前向传播过程
if (l.maxpool_depth)
{
int b, i, j, k, g;
// 遍历batch中每一张输入图片,计算得到与每一张输入图片具有l.maxpool_depth个通道的输出图
for (b = 0; b < l.batch; ++b) {
//openmp优化
//外层循环遍历特征图的长
#pragma omp parallel for
for (i = 0; i < l.h; ++i) {
//中层循环遍历特征图的宽
for (j = 0; j < l.w; ++j) {
//内层循环遍历特征图的输出通道
for (g = 0; g < l.out_c; ++g)
{
//out_index为输出图中的索引
int out_index = j + l.w*(i + l.h*(g + l.out_c*b));
float max = -FLT_MAX;
int max_i = -1;
//如上所述,每隔l.out_c个通道执行一次最大池化操作
for (k = g; k < l.c; k += l.out_c)
{
int in_index = j + l.w*(i + l.h*(k + l.c*b));
float val = state.input[in_index];
//记录最大池化的索引
max_i = (val > max) ? in_index : max_i;
max = (val > max) ? val : max;
}
l.output[out_index] = max;
if (l.indexes) l.indexes[out_index] = max_i;
}
}
}
}
return;
}
if (!state.train && l.stride_x == l.stride_y) {
//前向推理并且x和y方向的步幅相同的情况下,使用avx指令集优化Pool层的前向传播
forward_maxpool_layer_avx(state.input, l.output, l.indexes, l.size, l.w, l.h, l.out_w, l.out_h, l.c, l.pad, l.stride, l.batch);
}
else
{
int b, i, j, k, m, n;
// 初始偏移设定为四周补0长度的负值
int w_offset = -l.pad / 2;
int h_offset = -l.pad / 2;
// 获取当前层的输出尺寸
int h = l.out_h;
int w = l.out_w;
// 获取当前层输入图像的通道数,为什么是输入通道数?不应该为输出通道数吗?
// 实际二者没有区别,对于最大池化层来说,输入有多少通道,输出就有多少通道!
// 注意上面如果maxpool_depth有值,那么输出通道数就和输入通道数不一样了。
int c = l.c;
// 遍历batch中每一张输入图片,计算得到与每一张输入图片具有相同通道的输出图
for (b = 0; b < l.batch; ++b) {
// 对于每张输入图片,将得到通道数一样的输出图,以输出图为基准,按输出图通道,行,列依次遍历
// (这对应图像在l.output的存储方式,每张图片按行铺排成一大行,然后图片与图片之间再并成一行)。
// 以输出图为基准进行遍历,最终循环的总次数刚好覆盖池化核在输入图片不同位置进行池化操作。
for (k = 0; k < c; ++k) {
for (i = 0; i < h; ++i) {
for (j = 0; j < w; ++j) {
// out_index为输出图中的索引:out_index = b * c * w * h + k * w * h + h * w + w,展开写可能更为清晰些
int out_index = j + w*(i + h*(k + c*b));
float max = -FLT_MAX;
int max_i = -1;
// 下面两个循环回到了输入图片,计算得到的cur_h以及cur_w都是在当前层所有输入元素的索引,内外循环的目的是
// 找寻输入图像中,以(h_offset + i*l.stride, w_offset + j*l.stride)为左上起点,尺寸为l.size池化区域中的
//最大元素值max及其在所有输入元素中的索引max_i
for (n = 0; n < l.size; ++n) {
for (m = 0; m < l.size; ++m) {
//cur_h, cur_w是在所有输入图像的第k通道的cur_h行与cur_w列,index是在所有输入图像元素中的总索引
int cur_h = h_offset + i*l.stride_y + n;
int cur_w = w_offset + j*l.stride_x + m;
int index = cur_w + l.w*(cur_h + l.h*(k + b*l.c));
// 边界检查:正常情况下,是不会越界的,但是如果有补0操作,就会越界了,这里的处理方式是直接让这些元素值为-FLT_MAX
int valid = (cur_h >= 0 && cur_h < l.h &&
cur_w >= 0 && cur_w < l.w);
// 记录这个池化区域中最大的元素及其在所有输入元素中的总索引
float val = (valid != 0) ? state.input[index] : -FLT_MAX;
max_i = (val > max) ? index : max_i;
max = (val > max) ? val : max;
}
}
// 由此得到最大池化层每一个输出元素值及其在所有输入元素中的总索引。
// 为什么需要记录每个输出元素值对应在输入元素中的总索引呢?因为在下面的反向过程中需要用到,在计算当前最大池化层上一层网络的敏感度时,
// 需要该索引明确当前层的每个元素究竟是取上一层输出(也即上前层输入)的哪一个元素的值,具体见下面backward_maxpool_layer()函数的注释。
l.output[out_index] = max;
if (l.indexes) l.indexes[out_index] = max_i;
}
}
}
}
}
if (l.antialiasing) {
network_state s = { 0 };
s.train = state.train;
s.workspace = state.workspace;
s.net = state.net;
s.input = l.output;
forward_convolutional_layer(*(l.input_layer), s);
//simple_copy_ongpu(l.outputs*l.batch, l.output, l.input_antialiasing);
memcpy(l.output, l.input_layer->output, l.input_layer->outputs * l.input_layer->batch * sizeof(float));
}
}
最大池化层的反向传播
池化层的反向传播由backward_maxpool_layer实现,反向传播实际上比前向传播更加简单,你可以停下来想想为什么,再看我下面的详细解释。
/*
** 最大池化层反向传播函数
** l: 当前最大池化层
** state: 整个网络
** 说明:这个函数看上去很简单,比起backward_convolutional_layer()少了很多,这都是有原因的。实际上,在darknet中,不管是什么层,
** 其反向传播函数都会先后做两件事:1)计算当前层的敏感度图l.delta、权重更新值以及偏置更新值;2)计算上一层的敏感度图net.delta(部分计算,
** 要完成计算得等到真正到了这一层再说)。而这里,显然没有第一步,只有第二步,而且很简单,这是为什么呢?首先回答为什么没有第一步。注意当前层l是最大池化层,
** 最大池化层没有训练参数,说的再直白一点就是没有激活函数,或者认为激活函数就是f(x)=x,所以激活函数对于加权输入的导数其实就是1,
** 正如在backward_convolutional_layer()注释的那样,每一层的反向传播函数的第一步是将之前(就是下一层计算得到的,注意过程是反向的)
** 未计算完得到的l.delta乘以激活函数对加权输入的导数,以最终得到当前层的敏感度图,而对于最大池化层来说,每一个输出对于加权输入的导数值都是1,
** 同时并没有权重及偏置这些需要训练的参数,自然不再需要第一步;对于第二步为什么会如此简单。请看代码注释。
*/
void backward_maxpool_layer(const maxpool_layer l, network_state state)
{
int i;
//获取当前最大池化层l的输出尺寸h,w
int h = l.out_h;
int w = l.out_w;
//获取当前层输入/输出通道数
int c = l.out_c;
// 计算上一层的敏感度图(未计算完全,还差一个环节,这个环节等真正反向到了那层再执行,但是其实已经完全计算了,因为池化层无参数)
// 循环总次数为当前层输出总元素个数(包含所有输入图片的输出,即维度为l.out_h * l.out_w * l.c * l.batch,注意此处l.c==l.out_c)
// 对于上一层输出中的很多元素的导数值为0,而对最大值元素,其导数值为1;再乘以当前层的敏感度图,导数值为0的还是为0,导数值为1则就等于当前层的敏感度值。
// 以输出图总元素个数进行遍历,刚好可以找出上一层输出中所有真正起作用(在某个池化区域中充当了最大元素值)也即敏感度值不为0的元素,而那些没有起作用的元素,
// 可以不用理会,保持其初始值0就可以了。
#pragma omp parallel for //openmp优化
for(i = 0; i < h*w*c*l.batch; ++i){
int index = l.indexes[i];
// 遍历的基准是以当前层的输出元素为基准的,l.indexes记录了当前层每一个输出元素与上一层哪一个输出元素有真正联系(也即上一层对应池化核区域中最大值元素的索引),
// 所以index是上一层中所有输出元素的索引,且该元素在当前层某个池化域中充当了最大值元素,这个元素的敏感度值将直接传承当前层对应元素的敏感度值。
// 而net.delta中,剩下没有被index按索引访问到的元素,就是那些没有真正起到作用的元素,这些元素的敏感度值为0(net.delta已经在前向时将所有元素值初始化为0)
// 至于为什么要用+=运算符,原因有两个,和卷积类似:一是池化核由于跨度较小,导致有重叠区域;二是batch中有多张图片,需要将所有图片的影响加起来。
state.delta[index] += l.delta[i];
}
}
平均池化层的前向传播和反向传播
刚才已经讲到了,最大池化以及平均池化整理是非常类似的,只是把最大的算术操作换成平均,然后平均池化层的反向传播就完成了,具体的代码可以去github项目中查看。
后记
又水了一期,这就是池化层的核心内容了。
同期文章
- 【翻译】手把手教你用AlexeyAB版Darknet
- 【AlexeyAB DarkNet框架解析】一,框架总览
- 【AlexeyAB DarkNet框架解析】二,数据结构解析
- 【AlexeyAB DarkNet框架解析】三,加载数据进行训练
- 【AlexeyAB DarkNet框架解析】四,网络的前向传播和反向传播介绍以及layer的详细解析
- 【AlexeyAB DarkNet框架解析】五,卷积层的前向传播解析
- 【AlexeyAB DarkNet框架解析】六,卷积层的反向传播解析
- 【AlexeyAB DarkNet框架解析】七,YOLOV1损失函数代码详解(detection_layer.c)
- 【AlexeyAB DarkNet框架解析】八,YOLOV2损失函数代码详解(region_layer.c)
- 【AlexeyAB DarkNet框架解析】九,YOLOV3损失函数代码详解(yolo_layer.c)
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
