RabbitMQ VS Apache Kafka (二)—— Kafka简介
接上一章【RabbitMQ VS Apache Kafka (一)】,本章我们讨论Kafka。
Kafka
Kafka is a distributed, replicated commit log. Kafka本身没有队列的概念,作为一个消息中间件,乍听起来,这略显奇怪,这可能与我们长期以来的形成的一个固化思维有关——但凡消息系统,肯定离不开消息队列。让我们重新回头来看,如何理解distributed, replicated commit log:
- Distributed(分布式的):Kafka通常作为集群节点部署以实现分区容错和扩容
- Replicated(可复制的):Kafka之间消息通常跨服务节点进行复制
- Commit Log(提交日志):Kafka的消息通常以追加日志(又称主题Topic)的方式分区存储。在Kafka中,log(又称Topic)的概念是其核心特征。
要想正确理解Kafka,你必须首先要理解【日志,log】(主题,Topic)及其分区(Partition)。为了更好的理解其与队列的区别,我们看下面的图:
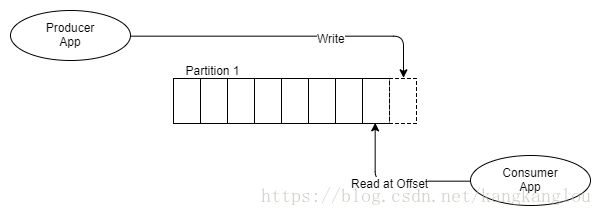
上图展示的是一个生产者,一个分区,一个消费者。
与RabbitMQ通过将消息放入到FIFO的消息队列,并通过这个队列来维护消息状态的处理模式不同,Kafka只是将消息追加到日志Log中,并不做清除操作,这也就是说,无论消息读取多少次(一次或者多次),消息都会存在,至于何时会被清除,则依赖于数据保留策略(通常是一个windows时间周期)。那么,消息者该如何去读取处理主题中的消息,通常来讲,每个消费者都会通过一个指针来记录指向其最后读取的消息位置,这个指针我们称之为偏移量。消费者依赖于客户端函数库来维护这个偏移量,基于不同的Kafka版本,这个变量可能会存于Zookeeper或者Kafka本身中,Zookeeper是一种分布式的共识技术,常用于像我们常见的Leader选举。Kafka通过Zookeeper来管理集群状态。
这种日志模型的神奇之处在于它很好的消除了消息传递状态的复杂性,并且更为重要的是,其允许消费者对消息进行回溯读取处理。一个简单的例子:假如有一个服务,其负责计算客户预定的发票数量,假设服务本身存在BUG,当天数据计算错误,那么如果你使用RabbitMQ,你需要怎么处理?重新发起预定服务,然后重新计算发票数量,而使用Kafka呢?你只需要将消费者的偏移量回溯一天即可。
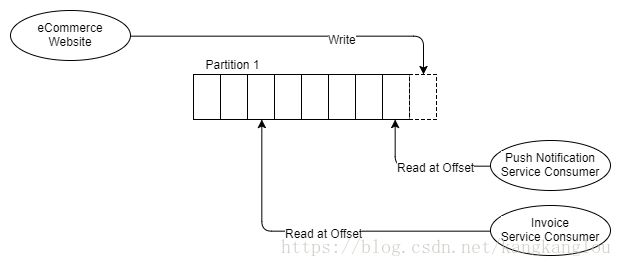
下图展示的是两个完全独立的消费者场景:
下面我们看下,Kafka下竞争消费的场景,还是上面的图,假设随着消息量的增加,我们需要将发票计算服务扩容到三个实例,对于RabbitMQ来说,我们仅仅需要额外增加两个发票计算服务即可,但对于Kafka来说,Kafka是不支持在单个分区上的竞争消费场景的,Kafka的并发机制是分区本身,如果我们需要三个不同的发票服务,那么我们需要至少三个分区。
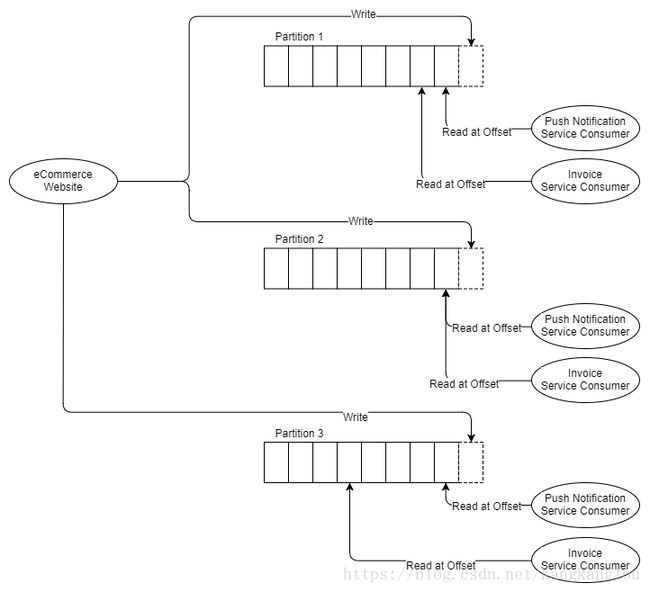
所以说,如果你需要增加扩容消费者,那么你也同样需要至少同样数量的分区才可以满足场景。下面我们深入讨论下分区
分区与消费者组
每一个分区都是一个单独的数据文件,用以保证消息顺序,注意:要记住这一点,消息顺序只在单个分区中得到保证。实际运用中,你可能需要在消息顺序和性能需求之间做一个平衡,原因正是我们之前所提到的,Kafka的并发单元是分区。
至于消息如何路由到分区?轮询或者哈希的方式(哈希值 % 分区数)。使用哈希算法的优点是,我们可以通过一定的哈希策略确保同样实体(比如预定服务)的消息被路由到同一分区。
消费者组就类似于RabbitMQ中的竞争消费者。组中的每一个消费者都是一个消费实例,负责处理同一主题下的消息子集。RabbitMQ中的竞争消费者是读取处理同一消息队列中的消息,而消费者组中的消费者则是读取处理不同分区中同一主题中的消息。因此,上图中的示例中,发票服务消费者属于同一消费者组。
在这一点上,RabbitMQ通过队列的方式保证了消息的有序性,更显灵活,并且可轻松灵活的调整竞争消费者数量。而对于Kafka,你则需要很好的划分你的Logs以满足实际的业务应用。
说到消息顺序和并发,Kafka还具备一个功能优势(RabbitMQ后续增加了类似功能)。RabbitMQ通过消息队列的形式维护了消息的全局有序性,却无法保证并发场景下消息处理的有序性。Kafka不保证消息的全局有序,但却保证分区层级的消息顺序。所以,如果仅仅需要保证特定系列消息的有序性,Kafka提供了消息的顺序传递和顺序处理。假设这样的业务场景,用一系列消息来表示一个客户端预定信息的最新状态,那么很自然的你需要顺序处理这些消息。因此,我们可以按预定ID来进行分区,对于某个特定的预定记录,其所有的状态消息都会发送到同一个分区中,在这个分区中,Kafka就可以保证消息的顺序处理。所以,我们可以通过创建多个分区来提高并发,同时保证消息的顺序处理(RabbitMQ也通过一致性哈希交换提供了类似的功能)。注意,这里也会有一个小问题,假设原有999个分区,如果你增加了一个分区到1000个,那么对于原有ID为1000的预定消息,原来可能是路由到分区1,增加分区之后,可能会被路由到分区1000,这种情况下,就可能导致消息处理非有序性问题的发生,关于这一点,我们后续章节讨论。
消息推送与被动拉取
RabbitMQ采用的是消息推送模型,并通过配置消费者预取阈值避免消费者超负荷运行。推送模型可以做到非常低的消息延迟并且非常适用于队列架构的消息系统。而Kafka使用的则是另一种消息拉取的模式,消费者会从给定的消息偏移两种批量拉取消息,为避免空取操作,Kafka支持长轮询操作。
对于分区架构的Kafka来说,信息拉取的模式是有意义的,Kafka确保在单个分区中无竞争消费的情况下消息的有序性,因此我们可以通过批处理实现消息的高效消息路由与处理。对于RabbitMQ来说,如果想要实现高效的并发消息处理,只能一次一条尽可能的提高消息发送的速度。对于Kafka来说,分区是并发和消息有序性的基本单元,因此,对于Kafka来说,可以很轻松的实现在保证消息有序性的前提下,高效地实现消息并发处理。
发布订阅
Kafka支持基本的发布订阅模式,生产者将消息追加到分区末尾,消费者通过在分区中的不同偏移量来实现定位。

为了更好的便于用户理解多分区和消费者组的场景,我们采用下面的这种方式来表示。
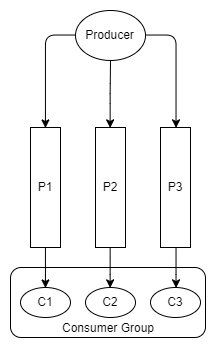
一个消费者可以从多个分区中读取消息。
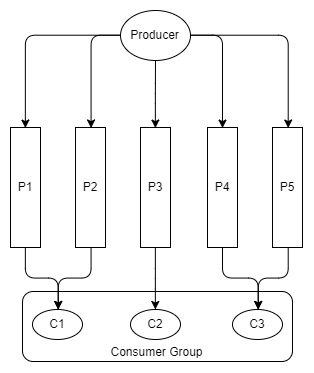
同样,当消费者多于分区数目时,多出来的消费者就会处于闲置状态。
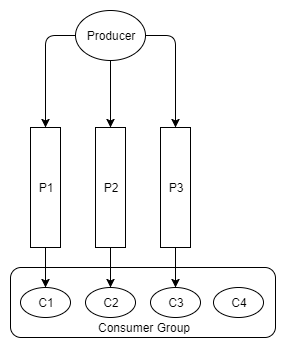
当我们往消费者组中增加或者删除消费者时,消费者组可能会变得不平衡,这时,我们就需要重新调整以尽可能的实现消费者之间的平衡,即再平衡操作。
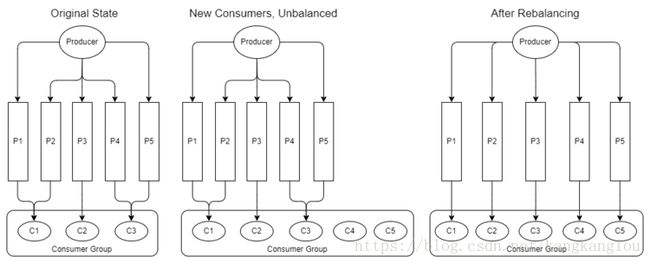
注意,再平衡操作会被自动触发,当:
- 新的消费者加入
- 已有的消费者离开(服务关闭或者停止)
- 新增分区
再平衡操作会导致一定的消息延迟,这是因为消费者会暂停消息批处理,然后重新分配到其他分区上。我们之前有谈到,Kafka可以实现将同一个实体的所有消息路由到同一个分区上,由同一个消费者进行处理,我们称之为数据局部性。当再平衡发生时,任何由消费者维护在内存中的状态都会失效,除非消费者还是被分配到同一分区,因此,为了克服再平衡时消息状态失效的问题,消费者需要通过外部持久化操作来维护这些消息状态。
日志压缩
总所周知,标准的数据保留策略是基于时间和空间两要素。除此之外,我们这里介绍第三种策略-日志压缩,所谓的日志压缩就是基于消息键值始终保留最新的消息,其余的则被删除。考虑一个业务场景,假设用一个消息来表示用户预定的状态信息,当每一次预定动作的改变都会产生一个新的消息来表示预定的最新状态,因此一个主题下可能会包含多个消息列表,当我们执行日志压缩动作之后,只会保留最近的状态消息,其余的则被全部删除。
原文链接
https://jack-vanlightly.com/blog/2017/12/4/rabbitmq-vs-kafka-part-1-messaging-topologies