使用Java爬取网易云音乐
使用java爬取网易云音乐
- 目的:抓取网易云音乐热门歌手及其歌曲、专辑等信息保存到数据库
- 技术点:
- 使用HttpClient和Jsoup进行模拟请求并对网页进行解析
- 使用springBoot+maven构建管理项目
- 使用mybatis作为数据访问
- 数据库设计
- song : id,name,comment_thread_id,mv_id,record_id,mp3Url
- singer: id,name,intro,picUrl
- record: id,name,picUrl,singer_id,tags,type,intro,company,comment_thread_id
- singer_song: singer_id,song_id,intro
这里考虑到一首歌曲可对应多个歌手,故建立一个中间表保存双方的id (多对多)
爬取网站的分析
1.歌曲页面的分析
目标网站:https://music.163.com/#/artist?id=6452
我们先以该网页进行分析,在对网页抓包中我们发现有个名为artist?id=2116的请求,在该请求返回的数据中我们发现就是该网页歌手对应的页面(即html)
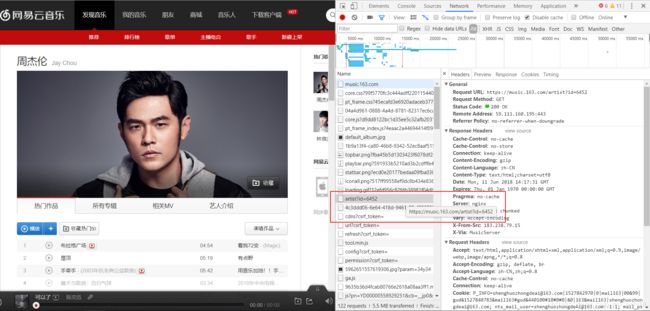
在该返回的html中,在标签中就存在该歌手的50首歌曲的json数据。对于所要做的系统来说,50首歌曲数据已经够了,为此我们拿到该数据即可。
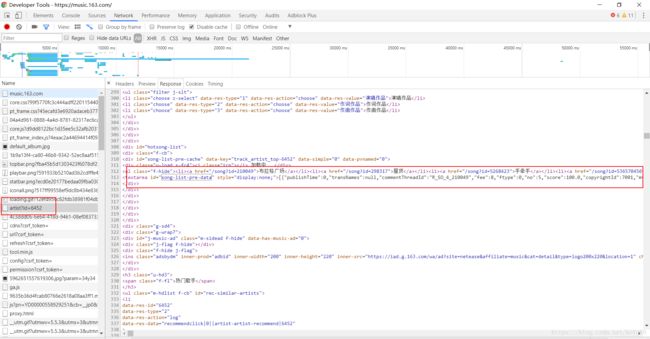
但是在其中我们并没有发现歌曲的url。当对歌曲进行点击后,抓包(url?csrf_token=)发现
浏览器向https://music.163.com/weapi/song/enhance/player/url?csrf_token= 发送了post请求,返回的就是带有当前歌曲url的json数据。
其中有两个参数
params:IvwCQv++yCDpnlC+Tog13k9WVWYgou3LauQ60jh9YPGSL1AkcUxma7r1Hs8yTaXBGYluJV7tl0xrTmtgl3qxQ6TZYNBIxfFvkaqqDxRKJvgsBOYV2SpD8mRfxrgbesqH
encSecKey:2b29c882a53743986c4f5aa279f1f2353a84a8d773071877252dbfc805c34b2065de3738945ea1bbdb29602b85d7ef4382d4d77c44c9eed6cb0c88ce7d3e37883b222b77381929a367b2fc062c3499ebfc7135c9d3a51b2fb8bb316f4c8006d2e30141b9be9de6bd017096fdeaf645e4450c88999febad081f9b6cc0e83fbaaa
这两个参数是加密过的。
找到https://s3.music.126.net/web/s/core.js?acad6e83fe6f991104f40576c001942a
在里面搜索encSecKey,找到加密函数,经过了两次加密。。
加密技术不太好搞,可以换种别的方法。
在对音乐生成外链的抓包中,意外地发现个url:http://music.163.com/song/media/outer/url?id=25730757
该url可直接拿到歌曲的url,这样我们只需要记住“http://music.163.com/song/media/outer/url?id=” 链接,最后加上歌曲id就可以拿到歌曲mp3的url了。
歌曲url:”https://music.163.com/artist?id=“+singerId;
歌曲mp3Url:“http://music.163.com/song/media/outer/url?id=” +songId;
2.歌手页面的分析
目标网站:https://music.163.com/#/artist/desc?id=2116
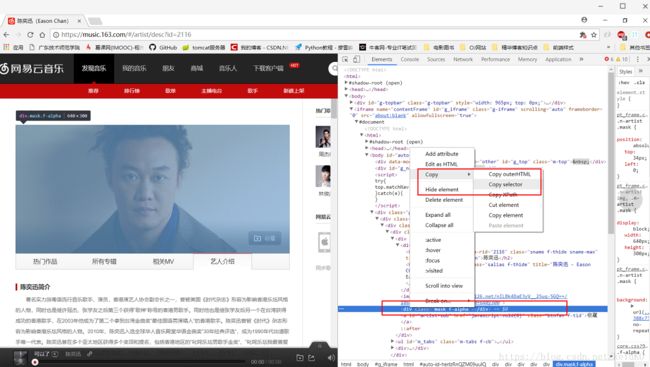
以所需要的图片数据为例,F12打开开发者工具,找到图片所在标签,右键复制元素的selector,得到#auto-id-herlzRnQZM09uulQ > div.g-bd4.f-cb > div.g-mn4 > div > div > div.n-artist.f-cb > img。其它所需数据也是通过此方法拿到对应的selector,之后用Jsoup解析即可得到对应的元素。
歌手url:”https://music.163.com/artist/desc?id=“+singerId;
3.专辑页面的分析
目标网站:https://music.163.com/#/artist/album?id=2116
我们发现,专辑页面进行了分页,在进行下一页过程的抓包中,发现专辑分页的规律是以limit和offset两个参数决定的。在对几个热门歌手分析中可以发现歌手的专辑数是没有超过两位数的,所以我们可以简单地假设一个歌手的专辑数不会超过100。因为要尽可能不跳转页面发请求,所以得到一个
url: https://music.163.com/artist/album?id=“+singerId+”&limit=100&offset=0
我们以这个url去请求页面,以歌手为例的拿取元素位置即可得到专辑所需要的信息。
代码逻辑分析
贴几个核心代码:
爬虫基类:
package com.netMusic.spider;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import com.netMusic.entity.Record;
import com.netMusic.entity.Singer;
import com.netMusic.entity.custom2.SongMsg;
import com.netMusic.utils.CharacterUtils;
import com.netMusic.utils.HttpClientUtil;
import org.apache.http.Header;
import org.apache.http.message.BasicHeader;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.lang.reflect.Type;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* 歌曲爬取类
*/
public class NetMusicGrab {
private final static Logger logger = LoggerFactory.getLogger(NetMusicGrab.class);
public static List getSongList(String url,String charest) {
Document document = getDocument(url, charest);
if(document!=null){
Elements elements = document.select("#song-list-pre-data");
System.out.println("json数据如下");
String resJson = elements.text();
// logger.info(resJson);
Gson gson = new Gson();
Type listType = new TypeToken>() {}.getType();
if(resJson!=null && !resJson.contains("html"));
List msgList = gson.fromJson(resJson, listType);
return msgList;
}
return null;
}
public static Singer getSinger(String url,String charest){
Document document = getDocument(url,charest);
if(document!=null){
Elements singerName = document.select("#artist-name");
System.out.println("歌手名字:"+singerName.text());
Elements singerAlias = document.select("#artist-alias");
String name="";
if(singerAlias!=null && !"".equals(singerAlias.text())){
System.out.println("歌手别名:"+singerAlias.text());
name = singerName.text()+"/"+singerAlias.text();
}else{
name = singerName.text();
}
Elements desc = document.select("body > div.g-bd4.f-cb > div.g-mn4 > div > div > div:nth-child(3) > div > p:nth-child(2)");
Elements image = document.select("body > div.g-bd4.f-cb > div.g-mn4 > div > div > div.n-artist.f-cb > img");
String intro = desc.text();
String picUrl = image.attr("src");
Singer singer = new Singer();
singer.setName(name);
if(intro.length()>=255 || "".equals(intro)){
intro = "暂无介绍";
}
singer.setIntro(intro);
singer.setPicUrl(picUrl);
return singer;
}
return null;
}
public static List getRecordList(String url,String charest){
List recordList = new ArrayList<>();
String publishTime = null;
String company = null;
Document document = getDocument(url,charest);
if(document!=null){
Elements elements = document.select("#m-song-module");
for(Element element :elements){
//专辑链接
Elements urlElement = element.select("#m-song-module > li:nth-child(1) > div > a.msk");
String albumUrl = urlElement.select(".msk").attr("href");
if(!albumUrl.contains("https://")){
albumUrl = "https://music.163.com"+albumUrl;
}
Elements elementsAlbumId = element.select("#m-song-module > li:nth-child(1) > div > a.icon-play.f-alpha");
String albumId = elementsAlbumId.attr("data-res-id");
try {
Document albumDec = Jsoup.connect(albumUrl).
userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
.get();
Elements main = albumDec.select("body > div.g-bd4.f-cb.p-share > div.g-mn4 > div > div > div.m-info.f-cb > div.cnt > div > div.topblk");
Elements elementsName = main.select("div > div > h2");
String albumName = elementsName.text();
Elements elementsPublishTime = main.select("p:nth-child(3)");
if(elementsPublishTime!=null && !"".equals(elementsPublishTime.text()) ){
publishTime = elementsPublishTime.text().substring(5);
}
Elements elementsCompany = main.select("p:nth-child(4)");
if(elementsCompany!=null && !"".equals(elementsCompany.text()) ){
company = elementsCompany.text().substring(5);
}
//如果包含中文,则说明该字段为company
if(CharacterUtils.isContainChinese(publishTime)){
company = publishTime;
publishTime = null;
}
Elements elementsCommentId = albumDec.select("#cnt_comment_count");
String commentId = elementsCommentId.text();
if(CharacterUtils.isContainChinese(commentId)){
commentId = null;
}
Elements elementsImg = albumDec.select("body > div.g-bd4.f-cb.p-share > div.g-mn4 > div > div > div.m-info.f-cb > div.cover.u-cover.u-cover-alb > img");
String picUrl = elementsImg.attr("data-src");
Elements elementsIntro = albumDec.select("#album-desc-dot");
String intro = elementsIntro.text();
if(intro.length()>=255 || intro.length()<=1){
intro = "暂无介绍";
}
Record record = new Record();
record.setId(Integer.valueOf(albumId));
record.setIntro(intro);
record.setPicUrl(picUrl);
record.setName(albumName);
record.setCompany(company);
record.setCommentThreadId(commentId);
if(publishTime!=null){
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date date = sdf.parse(publishTime);
record.setPublishTime(date);
}else{
record.setPublishTime(null);
}
recordList.add(record);
} catch (IOException e) {
e.printStackTrace();
}catch (Exception e){
e.printStackTrace();
}
}
}
return recordList;
}
private static Document getDocument(String url, String charest) {
List headerList = new ArrayList<>();
headerList.add(new BasicHeader("Host", "music.163.com"));
headerList.add(new BasicHeader("Referer", "https://music.163.com/"));
headerList.add(new BasicHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"));
String result = HttpClientUtil.doGet(url, headerList, charest);
if(result!=null && !result.contains("n-for404")){
return Jsoup.parse(result);
}
return null;
}
public static void main(String[] args) throws ParseException {
// 测试获取歌手信息
// List listId = BaseUtil.getRandomNumber(1000,10000,
// }
//测试专辑信息100);
//// for(Integer id:listId){
//// Singer singer = getSinger("https://music.163.com/artist/desc?id="+id,"utf-8");
//// System.out.println(singer);
// getRecordList("https://music.163.com/artist/album?id=3684&limit=100&offset=0","utf-8");
//测试字符串转时间
// SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// Date date = sdf.parse("2017-12-12");
// System.out.println(date);
}
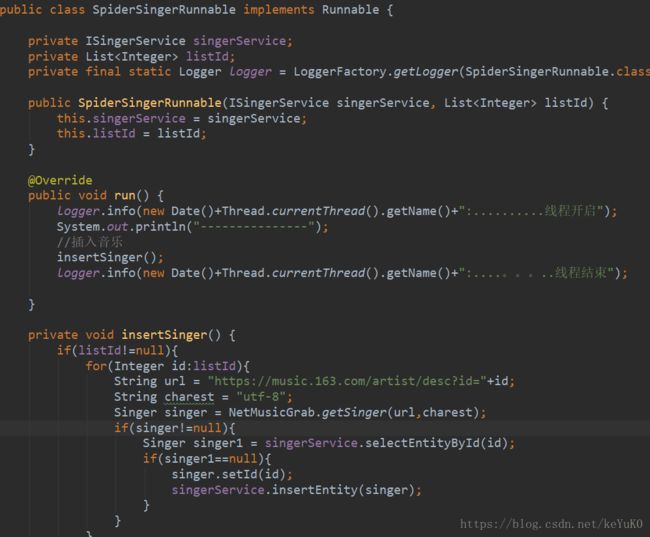
} 因为考虑到速度问题,采用简单的多线程开启方式,这里设置了三个子线程,分别爬取专辑,歌曲,歌手。同时,为使项目启动时即开始爬,添加了监听类,用来启动线程。
SpiderSingerRunnable类:
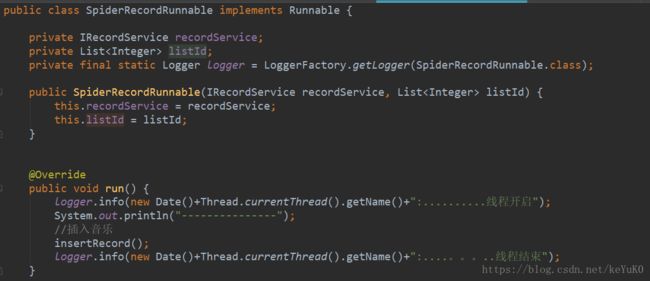
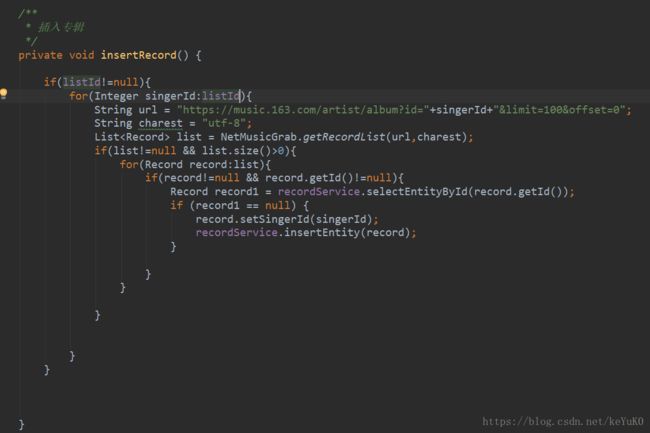
SpiderRecordRunnable类:
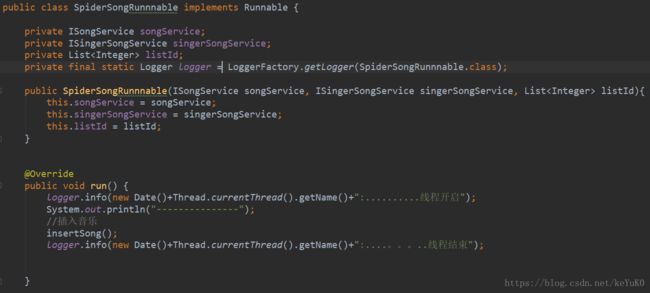
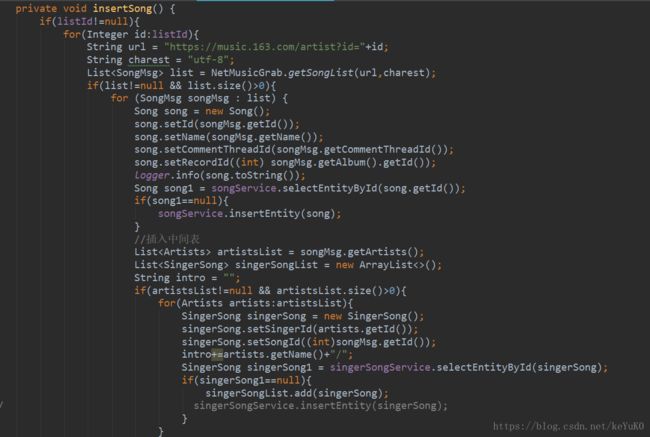
SpiderSongRunnnable类:
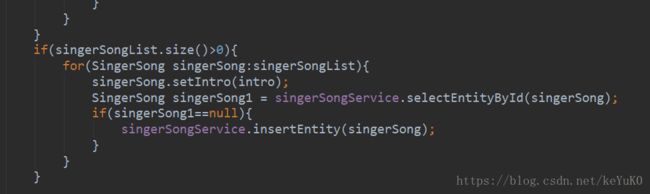
SaveDataListener类:
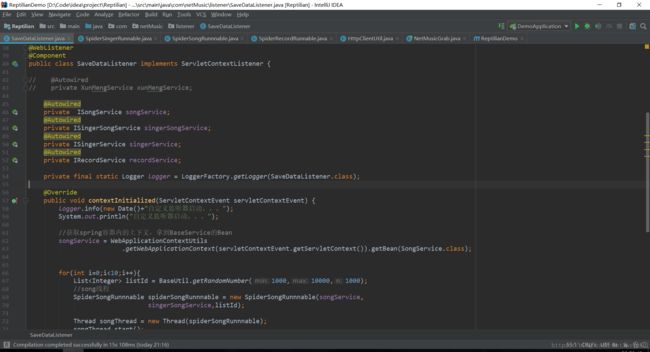
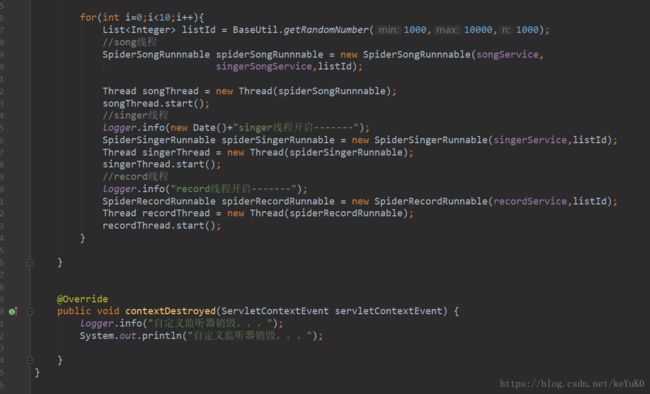
具体的代码可以在我的github找到,剩余的逻辑和一些自己封装的工具包就不贴了也相对简单。
学习总结
经过测试,20分钟左右爬取了大约14万的歌曲数据,期间有几次被封ip了,直接404,为解决这个问题得用上ip连接池不断地更换ip地址发出请求,不过目前来讲已经够了,之后有时间再去学学。还有个问题是,虽然采用了多线程,但我发现并没有将多线程用得很好,希望有时间去学下Redis缓存队列再对代码进行更新吧。