python 爬取网易新闻评论
前段时间在看处理数据相关的书籍,实践中需要一些网上评论的文本数据集,所以想到爬取网易新闻底下的评论。本来想着Python+beautifulsoup(解析)+requests(抓取),最后存储在txt文件中就OK,废话不多说,试试吧~
以这条新闻为例,可以看到,网易的新闻页面和评论页面是分开的,我们点进评论页面

我们看到一如既往的“支持加油”,还有评论页面的****url:http://comment.news.163.com/news2_bbs/CPISM0FT000189FH.html
打开编辑器,创建一个.py文件,导入相关模块,编码如下:
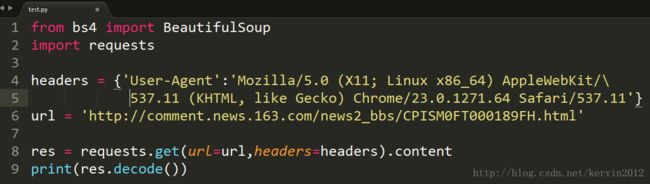
运行结果:

返回的html页面中,只有一些通用的html代码,而主要的评论部分根本没有,那么可以知道评论一定是动态获取的,我们f12打开开发者工具,依次Network->JS->(框起来的那个url)->Headers->往下拉就可以看见查询参数了

我们可以看到几个参数,其具体含义如下(别问怎么知道的,蒙的):
offset:0 (从哪一条评论开始获取)
limit:30(一次获取几条评论)
showLevelThreshold:72 (最多盖几层楼)
headLimit:1(未知)
tailLimit:2(未知)
callback:getData(回调函数)
ibc:newspc(未知)
_:1500365251256(未知)
我试了一下,除了offset和limit外,其他不要也没事,另外把callback必须去掉,这样返回的就是纯json数据格式了。
我们再来看看这个
=1500365251256”>http://comment.news.163.com/api/v1/products/a2869674571f77b5a0867c3d71db5856/threads/CPISM0FT000189FH/comments/newList?offset=0&limit=30&showLevelThreshold=72&headLimit=1&tailLimit=2&callback=getData&ibc=newspc&=1500365251256
CPISM0FT000189FH 这串码,就是一篇新闻的id,他可以告诉网易的服务器我找的是哪篇新闻的数据,可我们怎么知道一篇新闻的id呢,请回头看:

在评论页面的url中,html的文件名就是新闻的id码
好了,我们现在知道怎么获取到数据了,import json 用来把json数据解析成字典格式
编写代码如下:我们通过commentUrl获取文章的id,用createUrl生成获取评论的url,可以通过改变offset,limit(最好不超过40)两个参数来获取不同的评论数据

恩,又看到了一如既往的“加油”“支持”。。
好了,现在可以获取得到数据,下一步就是如何自动连续的获取大量的数据,那些就不是难点了,万丈高楼平地起,加油↖(^ω^)↗