信用评分卡模型在Python中实践(下)
信用评分卡模型在Python中实践(上)上一篇已经完成数据集的准备和指标筛选,本篇继续介绍模型构建和评分卡的创建。
五、模型训练
信用评分卡的模型一般采用逻辑回归模型,属于二分类模型,Python 中的sklearn.linear_model导入LogisticRegression即可。
#入模定量和定性指标
model_data = data[np.append(quant_model_vars,qual_model_vars)]
#
model_data_WOE = pd.DataFrame()
model_data_WOE['duration']=duration_WoE
model_data_WOE['amount']=amount_WoE
model_data_WOE['age']=age_WoE
model_data_WOE['installment_rate']=installment_rate_WoE
model_data_WOE['status']=status_WoE
model_data_WOE['credit_history']=credit_history_WoE
model_data_WOE['savings']=savings_WoE
model_data_WOE['property']=property_WoE
model_data_WOE['employment_duration']=employment_duration_WoE
model_data_WOE['purpose']=purpose_WoE
#model_data_WOE['credit_risk']=credit_risk
#逻辑回归
model = LogisticRegression()
model.fit(model_data_WOE,credit_risk)
coefficients = model.coef_.ravel()
intercept = model.intercept_[0]
注:Python中的模型不够R中模型友好,想看模型的变量、系数、检验之类的都比较麻烦,要一个变量一个变量去找,然后输出打印,反之R的模型结果就友好很多了,一个summary函数就把全部概况显示出来了。
###########自定义ks函数#############
def predict_df(model,data,label,feature=None):
if feature:
df_feature=data.loc[:,feature]
else:
all_feature = list(data.columns.values)
all_feature.remove(label)
df_feature=data.loc[:,all_feature]
df_prob=model.predict(df_feature)
df_pred=pd.Series(df_prob).map(lambda x:1 if x>0.5 else 0)
df=pd.DataFrame()
df['predict']=df_pred
df['label']=data.loc[:,label].values
df['score']=df_prob
return df
def ks(data,model,label):
data_df = predict_df(model,data,label)
KS_data = data_df.sort_values(by='score',ascending=True)
KS_data['Bad'] = KS_data['label'].cumsum() / KS_data['label'].sum()
KS_data['Count'] = np.arange(1 , len(KS_data['label']) + 1)
KS_data['Good'] = (KS_data['Count'] - KS_data['label'].cumsum() ) / (len(KS_data['label']) - KS_data['label'].sum())
KS_data.index=KS_data['Count']
ks = KS_data.iloc[::int(len(KS_data)/100),:]
ks.index = np.arange(len(ks))
return ks
def ks_plot(ks_df):
plt.figure(figsize=(6, 5))
plt.subplot(111)
plt.plot(ks_df['Bad'], lw=3.5, color='r', label='Bad') # train_ks['Bad']
plt.plot(ks_df['Good'], lw=3.5, color='g',
label='Good') # train_ks['Good']
plt.legend(loc=4)
plt.grid(True)
plt.axis('tight')
plt.title('The KS Curve of data')
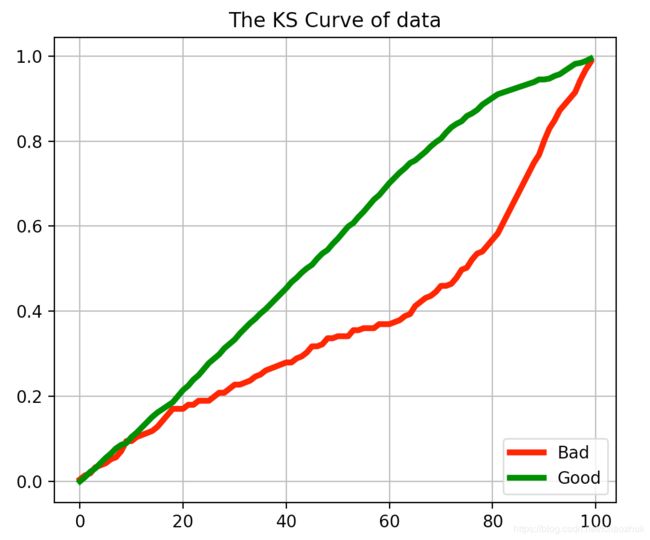
plt.show()KS(Kolmogorov-Smirnov):KS用于模型风险区分能力进行评估,
指标衡量的是好坏样本累计分部之间的差值。 好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强,通常来讲,KS>0.2即表示模型有较好的预测准确性。经过计算,模型的KS值为0.35,模型效果较好,如下:

六、评分卡
引用文献的评分卡计算方法:
一般评分卡公式:Score=A - B * log(Odds)
通常情况下,需要设定两个假设:
(1)给某个特定的比率设定特定的预期分值;
(2)确定比率翻番的分数(PDO)
根据以上的分析,我们首先假设比率为x的特定点的分值为P。则比率为2x的点的分值应该为P+PDO。代入式中,可以得到如下两个等式:
P = A - B * log(x)
P - PDO = A - B * log(2x)
本文中通过指定特定比率(好坏比)(1/20)的特定分值(50)和比率翻番的分数(10),来计算评分卡的系数alpha和beta
def alpha_beta(basepoints,baseodds,pdo):
beta = pdo/math.log(2)
alpha = basepoints + beta * math.log(baseodds)
return alpha,beta
评分卡公式:Score=6.78 - 14.43 * log(Odds)
而 ,代入WOE转换后的变量并进行变化,可得到最终的评分卡公式:
![]()
式中ωijωij 为第i行第j个变量的WOE,为已知变量;βiβi为逻辑回归方程中的系数,为已知变量;δijδij为二元变量,表示变量i是否取第j个值。

根据以上表格可计算出指标各分段的分值
#计算基础分值
basepoint = round(alpha - beta * intercept)
#变量_score
duration_score = np.round(model_data_WOE['duration']*coefficients[0]*beta)
amount_score = np.round(model_data_WOE['amount']*coefficients[1]*beta)
age_score = np.round(model_data_WOE['age']*coefficients[2]*beta)
installment_rate_score = np.round(model_data_WOE['installment_rate']*coefficients[2]*beta)
status_score = np.round(model_data_WOE['status']*coefficients[4]*beta)
credit_history_score = np.round(model_data_WOE['credit_history']*coefficients[5]*beta)
savings_score = np.round(model_data_WOE['savings']*coefficients[6]*beta)
property_score = np.round(model_data_WOE['property']*coefficients[7]*beta)
employment_duration_score = np.round(model_data_WOE['employment_duration']*coefficients[8]*beta)
purpose_score = np.round(model_data_WOE['purpose']*coefficients[9]*beta)
#变量的分值
duration_scoreCard = pd.DataFrame(duration_Cutpoint,duration_score).drop_duplicates()
amount_scoreCard = pd.DataFrame(amount_Cutpoint,amount_score).drop_duplicates()
age_scoreCard = pd.DataFrame(age_Cutpoint,age_score).drop_duplicates()
installment_rate_scoreCard = pd.DataFrame(installment_rate_Cutpoint,installment_rate_score).drop_duplicates()
status_scoreCard = pd.DataFrame(np.array(discrete_data['status']),status_score).drop_duplicates()
credit_history_scoreCard = pd.DataFrame(np.array(discrete_data['credit_history']),credit_history_score).drop_duplicates()
savings_scoreCard = pd.DataFrame(np.array(discrete_data['savings']),savings_score).drop_duplicates()
property_scoreCard = pd.DataFrame(np.array(discrete_data['property']),property_score).drop_duplicates()
employment_duration_scoreCard = pd.DataFrame(np.array(discrete_data['employment_duration']),employment_duration_score).drop_duplicates()
purpose_scoreCard = pd.DataFrame(np.array(discrete_data['purpose']),purpose_score).drop_duplicates()


至此,信用评分卡的