机器学习(一)——单变量线性回归
关键词:线性回归、监督学习、模型、假设函数、代价函数、梯度递降、学习率、训练集
一.前言
前段时间在学习 Andrew Ng 的《机器学习课程》,个人认为这是一个非常适合新手学习机器学习的课程(即使你对线性代数,微积分、概率论等已经忘得差不多了)。这里对学习课程做一些笔记和经验总结,方便自己后面做回顾复习,也希望对新手学习机器学习有些帮助。
机器学习的第一个算法就是 线性回归算法 , 这也是 监督学习 (Supervised Learning) 中学习的第一个算法,非常适合作为新手学习机器学习的入门例子,从中可以了解监督学习过程完整的流程,建立机器学习的基本概念。
二.模型表示
线性回归中最常见的例子就是预测房屋价格:

监督学习
在房屋价格预测的例子中,提供了一个数据集或者训练集(Training Set), 对于每个数据或样本都给出了一个对应的“正确答案”(即每个房屋的Size都对应一个Price), 因此被称作监督学习,与无监督学习对应。回归问题
它也是一个回归问题,因为针对每个输入的房屋Size,我们都可以预测出一个房屋的Price,而房屋的Price是一个在实数范围内变化的值,即输出值为连续变化且不可枚举的值。(还有一种最常见的监督学习方式,叫做分类问题,即每个输出的预测值为离散或可枚举的输出值)单变量线性回归
线性回归的直观理解是输入自变量和输出因变量存在近似的线性关系,若只有一个自变量和因变量,且二者的关系可用一条直线近似表示,则这种回归可以称为单变量线性回归;若有两个或两个以上的自变量,且因变量和自变量之间是线性关系,则这种回归称为多变量线性回归。
2.1 变量定义
假使我们回归问题的训练集(Training Set)如下表所示:
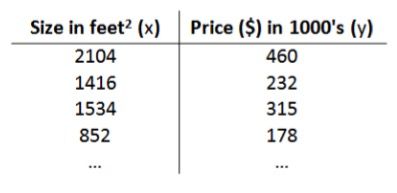
在机器学习中,我们通常用以下字母来标记各个变量:
- m 代表训练集中实例的数量(样本个数)
- x 代表特征/输入变量
- y 代表目标变量/输出变量
- (x,y) 代表训练集中的实例
- (x(i),y(i) ) 代表第 i 个观察实例
- h 代表学习算法的解决方案或函数也称为假设函数(hypothesis)
2.2 算法原理
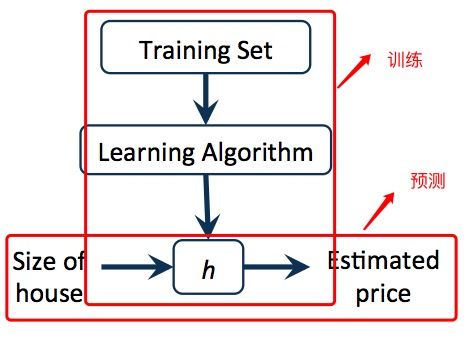
上图为一个监督学习算法的工作方式,竖向的流程是算法学习和训练的过程,即给出一个训练集,将它“喂”给学习算法,最终训练得到一个模型的输出;横向的流程为算法预测的过程,给出房屋的Size,经过上一步训练得到的模型,输出房屋Price的预测值。
2.3 模型定义
在单变量线性回归中,我们将模型定义为:![]()
其中![]() 也称作
也称作假设函数, ![]() 称为
称为模型参数, 在算法训练过程中,我们期望得到最优的 ![]() 的值使得模型最为匹配训练集的数据:
的值使得模型最为匹配训练集的数据:
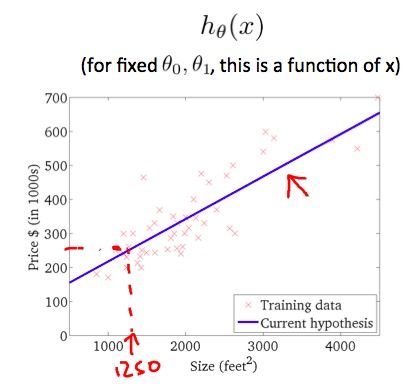
2.3.1 代价函数
在确定模型之后,我们需要做的是选择合适的参数 ![]() ,使得模型所预测的值与训练集中的实际值之间(下图中蓝色线所指)的差距(误差)最小。
,使得模型所预测的值与训练集中的实际值之间(下图中蓝色线所指)的差距(误差)最小。
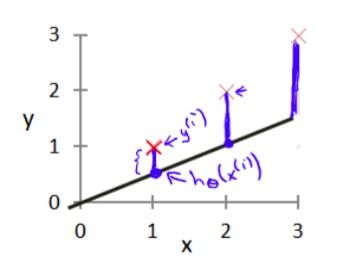
对于每个样本,都有一个损失值(loss), 在线性回归中损失函数(Loss Function),也叫误差函数(Error Function)定义为:
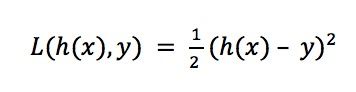
一般我们用预测值h(x)和实际值y的平方差或者它们平方差的一半来定义损失函数, 用来衡量预测输出值和实际值有多接近。
而将所有样本的损失值作求和,我们便得到一个代价函数(Cost Function):
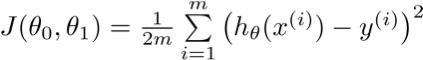
我们的优化目标就是选择出合适的模型参数 ![]() ,使得
,使得代价函数取得最小值。
注意:在不同的模型中,损失函数和代价函数可能都是不同的,如分类问题的损失函数就与线性回归的损失函数和代价函数都不同,在后续的文章中将介绍其他代价函数。
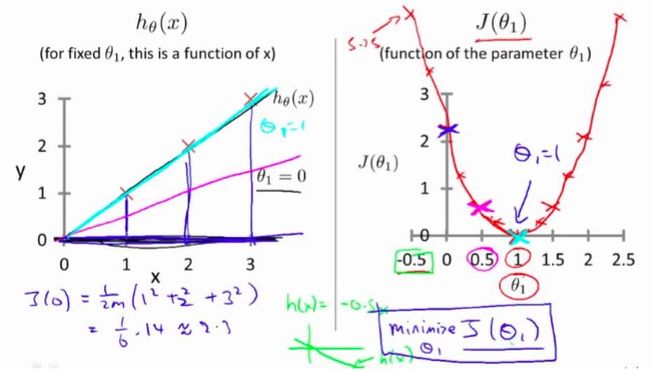
2.3.2 代价函数的直观理解
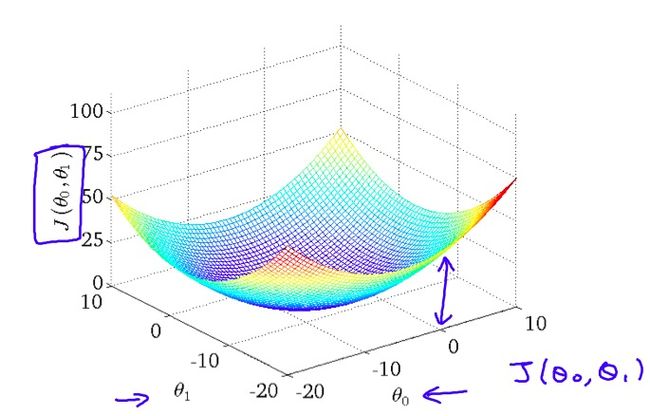
将
 函数画在一张三维的图上,可以看到它是一个
函数画在一张三维的图上,可以看到它是一个凸面:
若将
函数中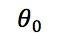 固定为0,则图形有三维的变为二维的
固定为0,则图形有三维的变为二维的抛物线:
三. 算法训练
在2.3.2小节中,我们通过画图可以大致地观察到代价函数J(θ0,θ1)在何处取到最小值,当然这种作图的方法给人一种直观的理解,但不能让计算机可以自动地求解出代价函数J(θ0,θ1)的最小值。因此需要一种有效的算法可以求解代价函数J(θ0,θ1)的最小值。
其中在计算机中,梯度下降算法是一个用来求函数最小值常用的算法, 下面我们将使用梯度下降算法来求出代价函数 J(θ0,θ1) 的最小值。
3.1 梯度下降算法(Gradient Descent)
梯度下降背后的思想是: 开始时我们随机选择一个参数的组合(θ0,θ1,...,θn),计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到 一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定 我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合, 可能会找到不同的局部最小值。
3.1.1 直观理解
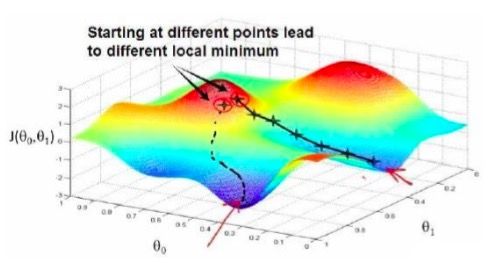
想象你正站在山上的一点,想要以最快的速度下山,你会怎么做?在梯度下降算法的思想中,我们要做的是站在那个点观察周围360°的方向,选出当前最佳(最陡,即可以理解为梯度的方向)的方向向前一小步,然后继续重复观察选出最佳的方向往下走,以此类推,直到逼近一个局部的最低点的位置。
3.1.2 算法过程

梯度下降算法的过程十分简单,即不断地更新 ![]() 参数,使得代价函数
参数,使得代价函数J(θ0,θ1)收敛到一个值。
下面说几个注意点:
- α 学习率(learning rate)
α 学习率 决定了沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,它会影响算法收敛速度的快慢,因此选择合适的学习率很重要,在第四节中会详细阐述如何选择合适的学习率。
梯度(Gradient)
等式右边的偏导数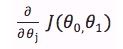 即为该点
即为该点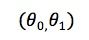 处的梯度值,后面会介绍如何计算该点处的偏导数。
处的梯度值,后面会介绍如何计算该点处的偏导数。同步更新(Simultaneous update)
梯度下降算法中,在更新θ0,θ1时需要同步更新两者,同步更新是一种更加自然的实现方法,在向量化(Vectorization)实现中更加容易,人们常说的梯度下降指的也是同步更新。
3.1.3 算法实现
前面我们已经得到了梯度下降算法的流程和线性回归的模型,如下:

那么如何求![]() 的值呢?
的值呢?
公式推导过程:

代入后得到最后的公式:
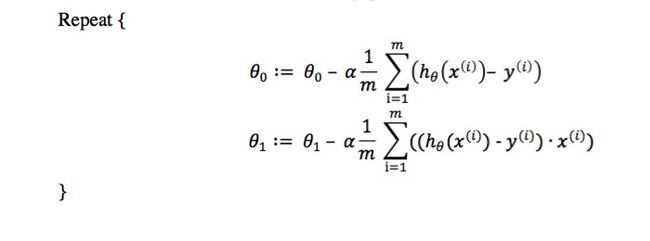
注意: 在多变量线性回归和分类问题中,梯度递降算法的公式都与上述公式极为相似。
四. 优化与总结
4.1 如何选择合适的学习率α
首先我们来看下α太小或太大会出现什么情况:
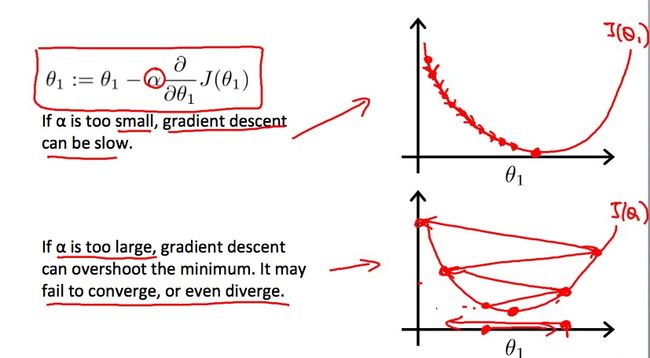
我们将θ0固定为0,则J(θ1)的图像为二次抛物线。
可以看到当α太小时,每次更新θ1的变化都十分小,即迭代速度十分缓慢;当α太大时,那么梯度下降算法可能会越过最低点,甚至无法收敛,每次迭代都会移动一大步,越来越远离最低点。
最佳实践:
在开始时我们不确定最合适的α值是多少,一般我们会选取等比的一系列α值做尝试,如0.001,0.003,0.01,0.03,0.1,0.3,1,… 每次尝试间隔大约是3倍左右。
最终比较不同学习率下,算法的收敛速度,选取合适的学习率。
4.2 如何选取迭代次数
我们可以将每次迭代后J(θ)的值记录下来,并画出迭代次数与代价函数J(θ)的图,当一次迭代后J(θ)的减小量小于ε值时,终止迭代。

五. 后言
- 在本文描述的梯度递降算法为
批量梯度递降算法(Batch Gradient Descent),此外还有微型批量递降算法(Mini-Batch Gradient Descent)与随机梯度递降算法(Stochastic Gradient Descent), 后两者在处理大数据的样本时用的比较多。 - 在下一节中,我们将继续学习多变量线性回归问题,并学习如何用向量化来实现算法。