深圳市社会组织信息平台爬虫获取信息
爬取网站:深圳市社会组织信息平台 .
网址:http://sgj.mzj.sz.gov.cn:9008/xxcx/index.jhtml
需要爬取的字段如下:
columns = ['社会组织名称', '统一信用代码', '成立时间', '法定代表人', '登记管理机关', '住所地址', '业务范围', '是否慈善组织', '是否取得公益性捐赠税前扣除资格', '是否具有公开募捐资格',
'在承接政府职能转移和购买服务社会组织推荐目录中', '状态', '证书有效期', '注册资金', '业务主管单位', '慈善组织认定登记日期', '是否纳入异常名录',
'是否纳入严重失信名录', '评估等级', '授予时间', '截止时间', '编号'] #编号是后期另一个文件的前提条件
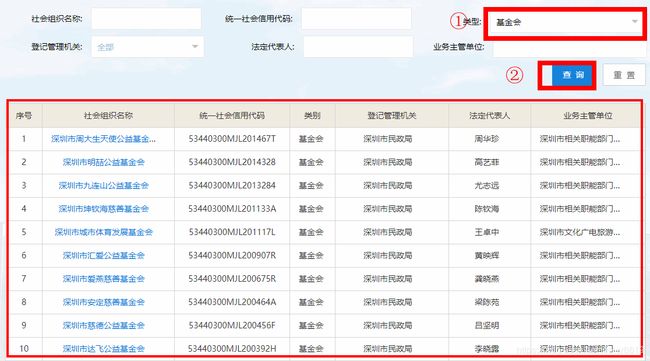
如图所示,先选择类型为基金会,其次点击查询,获得下图的表格数据,
然后点击XHR中的信息,从中获取表格中数据,json格式的比较容易爬取,
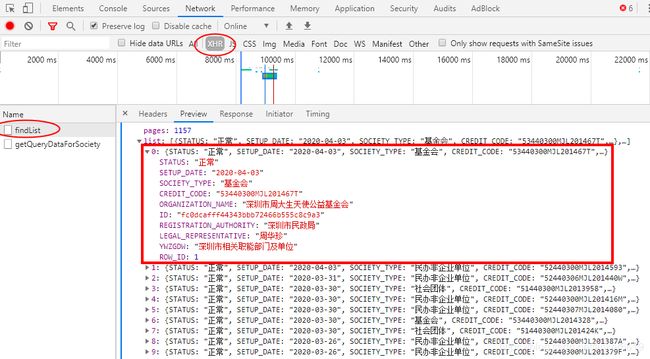
爬取如上信息
def bsae_info():
list_base_info = [] #保存数据
url_1 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/society/findList'
for m in range(1, 3):
data_1 = {'pageNum': m,
'SOCIETY_TYPE': '4'} #传递参数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'} #为避免麻烦,每个函数都加入
res_1 = requests.post(url_1, data=data_1, headers=headers)
res_1_json = res_1.json()
items_1 = res_1_json['data']['list']
for i in items_1: #获取数据
try:
ORGANIZATION_NAME = i['ORGANIZATION_NAME']
CREDIT_CODE = i['CREDIT_CODE']
SETUP_DATE = i['SETUP_DATE']
LEGAL_REPRESENTATIVE = i['LEGAL_REPRESENTATIVE']
REGISTRATION_AUTHORITY = i['REGISTRATION_AUTHORITY']
ID = i['ID']
except:
pass
list_base_info.append([ORGANIZATION_NAME, CREDIT_CODE, SETUP_DATE, LEGAL_REPRESENTATIVE, REGISTRATION_AUTHORITY, ID]) #列表加入数据
return list_base_info
点进去首页的基金会组织名称,得到该基金会的进一步详细数据。点击左侧信息框的内容,右侧会出现相应的json信息,得到相应的数据,使用列表格式保存数据。
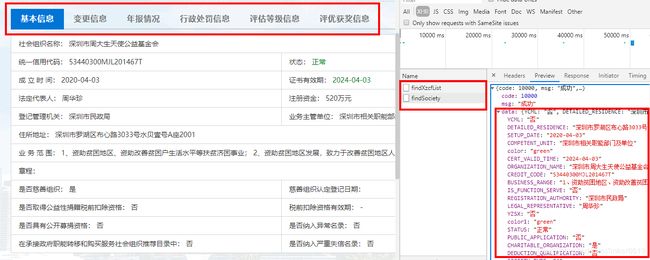
上述信息爬取
def info(ID):
list_info = []
for id_ in ID:
url_2 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/index/findSociety'
data_2 = {'societyId': id_}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_2 = requests.post(url_2, data=data_2, headers=headers)
res_2_json = res_2.json()
datas = res_2_json['data']
try:
DETAILED_RESIDENCE = datas['DETAILED_RESIDENCE']
BUSINESS_RANGE = datas['BUSINESS_RANGE']
CHARITABLE_ORGANIZATION = datas['CHARITABLE_ORGANIZATION']
DEDUCTION_QUALIFICATION = datas['DEDUCTION_QUALIFICATION']
PUBLIC_APPLICATION = datas['PUBLIC_APPLICATION']
IS_FUNCTION_SERVE = datas['IS_FUNCTION_SERVE']
STATUS = datas['STATUS']
CERT_VALID_TIME = datas['CERT_VALID_TIME']
REGISTERED_CAPITAL = datas['REGISTERED_CAPITAL']
COMPETENT_UNIT = datas['COMPETENT_UNIT']
SETUP_DATE = datas['SETUP_DATE']
YCML = datas['YCML']
YZSX = datas['YZSX']
except NameError: #部分内容存在问题,需要加错误信息处理
pass
except KeyError:
pass
list_info.append([DETAILED_RESIDENCE, BUSINESS_RANGE, CHARITABLE_ORGANIZATION, DEDUCTION_QUALIFICATION, PUBLIC_APPLICATION, IS_FUNCTION_SERVE, STATUS, CERT_VALID_TIME, REGISTERED_CAPITAL, COMPETENT_UNIT, SETUP_DATE, YCML, YZSX])
return list_info
接下来爬取评估等级信息,由于不是每个基金会都含有此信息,因此需要找一个有此信息的基金会,如图所示,等级信息如右所示,
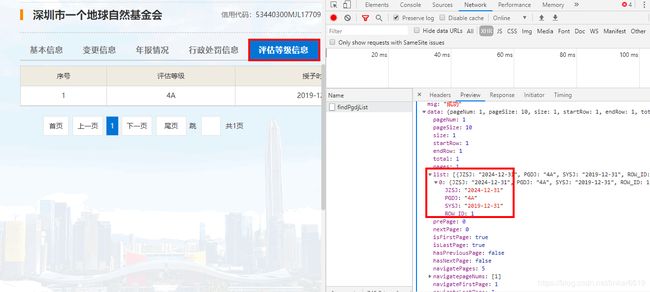
爬虫代码
def grade(ID):
list_grade = []
for id_ in ID:
url_3 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/index/findPgdjList'
data_2 = {'societyId': id_}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_3 = requests.post(url_3, data=data_2, headers=headers)
res_3_json = res_3.json()
data1s = res_3_json['data']['list']
if data1s == []: #考虑到不是每个基金会都有相关信息
PGDJ = ''
SYSJ = ''
JZSJ = ''
else:
for k in data1s:
try:
PGDJ = k['PGDJ']
SYSJ = k['SYSJ']
JZSJ = k['JZSJ']
except :
PGDJ = ''
SYSJ = ''
JZSJ = ''
list_grade.append([PGDJ, SYSJ, JZSJ])
return list_grade
下一步是要查询基金会的年检报告,需要回到主界面进行查询

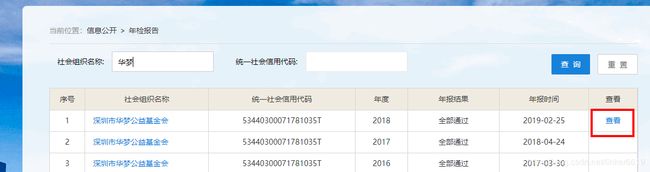
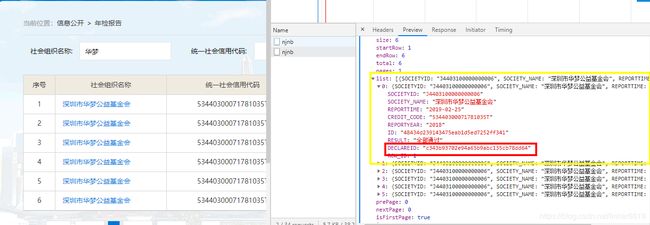
查看XHR信息,只在该信息下列表第一个存在DECLAREID信息,这个信息是后续报告使用的
爬虫文件
def number1(NAME):
number_ = []
for name in NAME:
url_4 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/info/njnb'
data_4 = {'ORGANIZATION_NAME': name} #这个比较重要
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_4 = requests.post(url_4, data=data_4, headers=headers)
res_4_json = res_4.json()
data_4 = res_4_json['data']['list']
if data_4 ==[]:
number = ' '
else:
try:
number = data_4[0]['DECLAREID']
except KeyError:
number = ''
number_.append(number)
return number_
点击页面的查看,可以得到相关的年报信息,网址:http://218.17.83.146:9009/SOCSP_O/publicnjnb/printAll?declareId=c343b93702e94a65b9abc135cb78dd64。可以看到后面的信息是之前爬取的编号。点进去后产生一个小框窗口,这个小窗口目前无法攻克,太麻烦了,
最后是main信息
if __name__ == '__main__':
ID = []
NAME = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
columns = ['社会组织名称', '统一信用代码', '成立时间', '法定代表人', '登记管理机关', '住所地址', '业务范围', '是否慈善组织', '是否取得公益性捐赠税前扣除资格', '是否具有公开募捐资格',
'在承接政府职能转移和购买服务社会组织推荐目录中', '状态', '证书有效期', '注册资金', '业务主管单位', '慈善组织认定登记日期', '是否纳入异常名录',
'是否纳入严重失信名录', '评估等级', '授予时间', '截止时间', '编号']
list_base_info = bsae_info()
for i in list_base_info:
ID.append(i[5])
NAME.append(i[0])
list_info = info(ID)
list_grade = grade(ID)
number_ = number1(NAME)
list_base_info = pd.DataFrame(list_base_info).iloc[:, 0:5]
list_info = pd.DataFrame(list_info)
list_grade = pd.DataFrame(list_grade)
number_ = pd.DataFrame(number_)
df3 = pd.concat([list_base_info, list_info, list_grade, number_], axis=1, ignore_index=True)
df = pd.DataFrame(df3.values, columns=columns)
df.to_csv('01.csv', index=False, encoding='gbk')
整合一下完整信息,两个版本。
版本一(函数形式)
# -*- coding:utf-8 -*-
import requests
import pandas as pd
def bsae_info():
list_base_info = []
url_1 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/society/findList'
for m in range(1, 3):
data_1 = {'pageNum': m,
'SOCIETY_TYPE': '4'}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_1 = requests.post(url_1, data=data_1, headers=headers)
res_1_json = res_1.json()
items_1 = res_1_json['data']['list']
for i in items_1:
try:
ORGANIZATION_NAME = i['ORGANIZATION_NAME']
CREDIT_CODE = i['CREDIT_CODE']
SETUP_DATE = i['SETUP_DATE']
LEGAL_REPRESENTATIVE = i['LEGAL_REPRESENTATIVE']
REGISTRATION_AUTHORITY = i['REGISTRATION_AUTHORITY']
ID = i['ID']
except:
pass
list_base_info.append([ORGANIZATION_NAME, CREDIT_CODE, SETUP_DATE, LEGAL_REPRESENTATIVE, REGISTRATION_AUTHORITY, ID])
return list_base_info
def info(ID):
list_info = []
for id_ in ID:
url_2 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/index/findSociety'
data_2 = {'societyId': id_}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_2 = requests.post(url_2, data=data_2, headers=headers)
res_2_json = res_2.json()
datas = res_2_json['data']
try:
DETAILED_RESIDENCE = datas['DETAILED_RESIDENCE']
BUSINESS_RANGE = datas['BUSINESS_RANGE']
CHARITABLE_ORGANIZATION = datas['CHARITABLE_ORGANIZATION']
DEDUCTION_QUALIFICATION = datas['DEDUCTION_QUALIFICATION']
PUBLIC_APPLICATION = datas['PUBLIC_APPLICATION']
IS_FUNCTION_SERVE = datas['IS_FUNCTION_SERVE']
STATUS = datas['STATUS']
CERT_VALID_TIME = datas['CERT_VALID_TIME']
REGISTERED_CAPITAL = datas['REGISTERED_CAPITAL']
COMPETENT_UNIT = datas['COMPETENT_UNIT']
SETUP_DATE = datas['SETUP_DATE']
YCML = datas['YCML']
YZSX = datas['YZSX']
except NameError:
pass
except KeyError:
pass
list_info.append([DETAILED_RESIDENCE, BUSINESS_RANGE, CHARITABLE_ORGANIZATION, DEDUCTION_QUALIFICATION, PUBLIC_APPLICATION, IS_FUNCTION_SERVE, STATUS, CERT_VALID_TIME, REGISTERED_CAPITAL, COMPETENT_UNIT, SETUP_DATE, YCML, YZSX])
return list_info
def grade(ID):
list_grade = []
for id_ in ID:
url_3 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/index/findPgdjList'
data_2 = {'societyId': id_}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_3 = requests.post(url_3, data=data_2, headers=headers)
res_3_json = res_3.json()
data1s = res_3_json['data']['list']
if data1s == []:
PGDJ = ''
SYSJ = ''
JZSJ = ''
else:
for k in data1s:
try:
PGDJ = k['PGDJ']
SYSJ = k['SYSJ']
JZSJ = k['JZSJ']
except :
PGDJ = ''
SYSJ = ''
JZSJ = ''
list_grade.append([PGDJ, SYSJ, JZSJ])
return list_grade
def number1(NAME):
number_ = []
for name in NAME:
url_4 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/info/njnb'
data_4 = {'ORGANIZATION_NAME': name}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_4 = requests.post(url_4, data=data_4, headers=headers)
res_4_json = res_4.json()
data_4 = res_4_json['data']['list']
if data_4 ==[]:
number = ' '
else:
try:
number = data_4[0]['DECLAREID']
except KeyError:
number = ''
number_.append(number)
return number_
if __name__ == '__main__':
ID = []
NAME = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
columns = ['社会组织名称', '统一信用代码', '成立时间', '法定代表人', '登记管理机关', '住所地址', '业务范围', '是否慈善组织', '是否取得公益性捐赠税前扣除资格', '是否具有公开募捐资格',
'在承接政府职能转移和购买服务社会组织推荐目录中', '状态', '证书有效期', '注册资金', '业务主管单位', '慈善组织认定登记日期', '是否纳入异常名录',
'是否纳入严重失信名录', '评估等级', '授予时间', '截止时间', '编号']
list_base_info = bsae_info()
for i in list_base_info:
ID.append(i[5])
NAME.append(i[0])
list_info = info(ID)
list_grade = grade(ID)
number_ = number1(NAME)
list_base_info = pd.DataFrame(list_base_info).iloc[:, 0:5]
list_info = pd.DataFrame(list_info)
list_grade = pd.DataFrame(list_grade)
number_ = pd.DataFrame(number_)
df3 = pd.concat([list_base_info, list_info, list_grade, number_], axis=1, ignore_index=True)
df = pd.DataFrame(df3.values, columns=columns)
df.to_csv('01.csv', index=False, encoding='gbk')
版本二
# -*- coding:utf-8 -*-
import requests
import pandas as pd
columns = ['社会组织名称', '统一信用代码', '成立时间', '法定代表人', '登记管理机关', '住所地址', '业务范围', '是否慈善组织', '是否取得公益性捐赠税前扣除资格', '是否具有公开募捐资格', '在承接政府职能转移和购买服务社会组织推荐目录中', '状态', '证书有效期', '注册资金', '业务主管单位', '慈善组织认定登记日期', '是否纳入异常名录', '是否纳入严重失信名录', '评估等级', '授予时间', '截止时间', '编号']
df = pd.DataFrame(columns=columns)
url_1 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/society/findList'
for m in range(1, 43):
data_1 = {'pageNum': m,
'SOCIETY_TYPE': '4'}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_1 = requests.post(url_1, data=data_1, headers=headers)
res_1_json = res_1.json()
items_1 = res_1_json['data']['list']
for i in items_1:
try:
name = i['ORGANIZATION_NAME']
CREDIT_CODE = i['CREDIT_CODE']
SETUP_DATE = i['SETUP_DATE']
LEGAL_REPRESENTATIVE = i['LEGAL_REPRESENTATIVE']
REGISTRATION_AUTHORITY = i['REGISTRATION_AUTHORITY']
ID = i['ID']
except:
pass
url_2 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/index/findSociety'
data_2 = {'societyId': ID}
res_2 = requests.post(url_2, data=data_2, headers=headers)
res_2_json = res_2.json()
datas = res_2_json['data']
try:
DETAILED_RESIDENCE = datas['DETAILED_RESIDENCE']
BUSINESS_RANGE = datas['BUSINESS_RANGE']
CHARITABLE_ORGANIZATION = datas['CHARITABLE_ORGANIZATION']
DEDUCTION_QUALIFICATION = datas['DEDUCTION_QUALIFICATION']
PUBLIC_APPLICATION = datas['PUBLIC_APPLICATION']
IS_FUNCTION_SERVE = datas['IS_FUNCTION_SERVE']
STATUS = datas['STATUS']
CERT_VALID_TIME = datas['CERT_VALID_TIME']
REGISTERED_CAPITAL = datas['REGISTERED_CAPITAL']
COMPETENT_UNIT = datas['COMPETENT_UNIT']
SETUP_DATE = datas['SETUP_DATE']
YCML = datas['YCML']
YZSX = datas['YZSX']
except NameError:
pass
except KeyError:
pass
url_3 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/index/findPgdjList'
res_3 = requests.post(url_3, data=data_2, headers=headers)
res_3_json = res_3.json()
data1s = res_3_json['data']['list']
if data1s == []:
PGDJ = ''
SYSJ = ''
JZSJ = ''
else:
for k in data1s:
try:
PGDJ = k['PGDJ']
SYSJ = k['SYSJ']
JZSJ = k['JZSJ']
except :
PGDJ = ''
SYSJ = ''
JZSJ = ''
url_4 = 'http://218.17.83.146:9008/SOCSP_PS_SP/api/info/njnb'
data_4 = {'ORGANIZATION_NAME': name}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
res_4 = requests.post(url_4, data=data_4, headers=headers)
res_4_json = res_4.json()
data_4 = res_4_json['data']['list']
if data_4 ==[]:
number = ' '
else:
try:
number = data_4[0]['DECLAREID']
except KeyError:
number = ''
B = {'社会组织名称': name, '统一信用代码': CREDIT_CODE, '成立时间': SETUP_DATE, '法定代表人': LEGAL_REPRESENTATIVE,
'登记管理机关': REGISTRATION_AUTHORITY, '住所地址': DETAILED_RESIDENCE, '业务范围': BUSINESS_RANGE,
'是否慈善组织': CHARITABLE_ORGANIZATION, '是否取得公益性捐赠税前扣除资格': DEDUCTION_QUALIFICATION,
'是否具有公开募捐资格': PUBLIC_APPLICATION, '在承接政府职能转移和购买服务社会组织推荐目录中': IS_FUNCTION_SERVE, '状态': STATUS,
'证书有效期': CERT_VALID_TIME, '注册资金': REGISTERED_CAPITAL, '业务主管单位': COMPETENT_UNIT, '慈善组织认定登记日期': SETUP_DATE,
'是否纳入异常名录': YCML, '是否纳入严重失信名录': YZSX, '评估等级': PGDJ, '授予时间': SYSJ,
'截止时间': JZSJ, '编号': number}
df = df.append([B], ignore_index=True)
df.to_csv('01.csv', index=False, encoding='gbk')
网站基本不存在反爬措施,只是数据较多,需要厘清先后关系,需要注意错误信息,因为某些信息不存在,需要设置为空。整体来说还是比较简单的