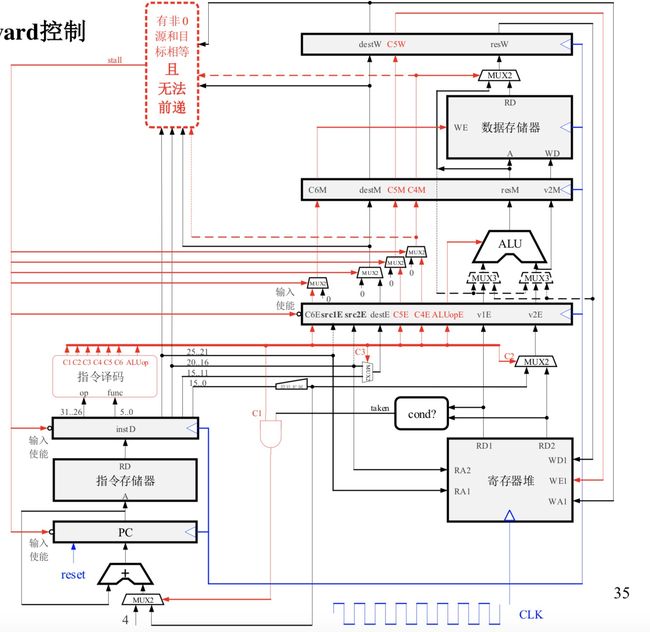
C1:就是情况(5)中我们说到的PC需要+4还是+offset的控制信号
C2:就是情况(1)中我们说到的进行ALU运算的第二个源操作数到底是rt还是imm的控制信号
C3:就是情况(4)中我们说到的要把最后的结果到底要保存到rd还是rt寄存器中的控制信号
C4:就是情况(3)中我们说到的要到底要存放ALU的结果还是从数据存储器中得到的结果的控制信号
C5: 就是情况(6)中的寄存器写使能端WE1
C6:就是情况(6)中数据存储器的写使能端WE
ALUOP:就是情况(2)中我们要进行哪种ALU运算
TIPS: 另外在图中,我们还看到有个小部件是符号扩展从imm连到了offset,这是因为imm数的长度不够32位,无法和PC进行直接运算,需要把数扩展成32位才能进行运算。还有一个br_taken部件是为了支持有条件跳转,比如指令BEQ R2,R3,offset,功能是如果R2==R3,PC=PC+offset,所以会有一个判断两寄存器值是否满足跳转条件。
到目前为止,我们几乎已经完成了主要的数据通路和控制通路啦!离实现一个CPU又进了一步!但是,这个CPU还是不能工作。。为什么呢?因为这个CPU还缺少了时钟部分,时钟就是CPU的驱动,相当于人的心脏,有了心脏的跳动,人才能正常活动,CPU也一样。
小知识:我们知道影响一台计算机快慢有很多因素,但归根到底,我们可以把运行速度分成三部分,程序运行所需要的指令数,每条指令所需要的时钟周期数(CPI),每个时钟周期的长度,三部分乘在一起就是一个程序的运行时间。所需要的指令数可以通过算法优化,编译器优化来减少;每条指令所需要的时钟周期和指令系统的设计,以及体系结构的设计有关;时钟周期的长度简单来说就是我们平常买电脑时所说的CPU主频(2GHZ,3GHZ这种)。所以在这里,我们需要给我们的CPU加上心跳!
给CPU加上时钟
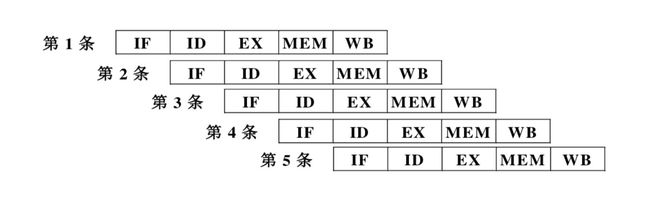
简单的来说,我们可以把一条指令的执行分成三步,1、计算PC的值 2、根据PC的值从指令存储器中取出指令放到指令寄存器IR中 3、根据指令的内容,控制指令的执行,把结果写到寄存器堆或数据存储器中。指令执行的三个阶段,如图所示。
这三个步骤,我们可以用三个时钟信号来控制,第一个时钟计算PC的值,完成取指后(把指令从指令存储器中取出),第二个时钟把取出的指令送到IR中去,等指令执行完以后,第三个时钟周期把指令的运算结果送到通用寄存器或数据存储器中。这三个时钟信号,我们可以用一个统一的时钟CLK进行分频,分出三个时钟信号给这三个步骤使用。
改进一、三步化两步
现在这个CPU能够一拍一拍、一条一条的执行指令了,但是这个CPU不够高效,因为其实前一条指令的执行和当前指令计算PC的值并不会冲突,所以我们可以把第N条指令的执行和第N+1条指令的计算PC重叠起来。效果上看,我们可以把计算PC的值当做指令执行阶段的一部分,那么一条指令执行就可以当做只有取指和执行两个阶段了。效果如图所示。
那么此时,我们可以把统一的时钟CLK分频,分出两个时钟信号来控制这两个步骤。

改进二、两步化一步
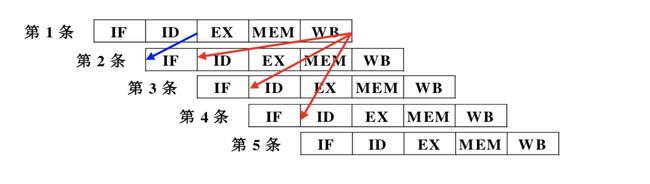
这时候,我们就会有一个新的想法,既然计算PC和执行已经重叠了,那有没有办法把取指和执行也重叠了呢?答案是肯定的,当第N条指令执行完,已经把结果写回寄存器或内存,第N+1条指令可以使用第N条指令的结果。这种方式在大多数情况下是成立的,但有一种特殊情况我们需要考虑,那就是转移指令,如果第N条指令是转移指令的话,在第N+1条指令在取指的时候,需要知道第N条指令转移是否成功?往哪里跳转?而这个结果是需要等待第N条指令执行完才能知道的,此时第N条指令的执行和第N+1条指令的取指不能重叠。
那有没有办法把这种情况解决呢?答案是肯定的,有人提出了延迟槽技术。延迟槽技术简单的说就是不管跳转指令是否转移成功,紧跟着的那条指令都必须执行。这样的好处就是转移指令的执行和下一条指令的取指可以重叠了!
经过这样的改进以后,我们可以把第N条指令的执行和第N+1条指令的取指重叠,效果如图所示。

那么此时,我们只需要一个时钟信号就能控制整个CPU的所有部分啦!加上时钟信号以后,CPU如图所示。
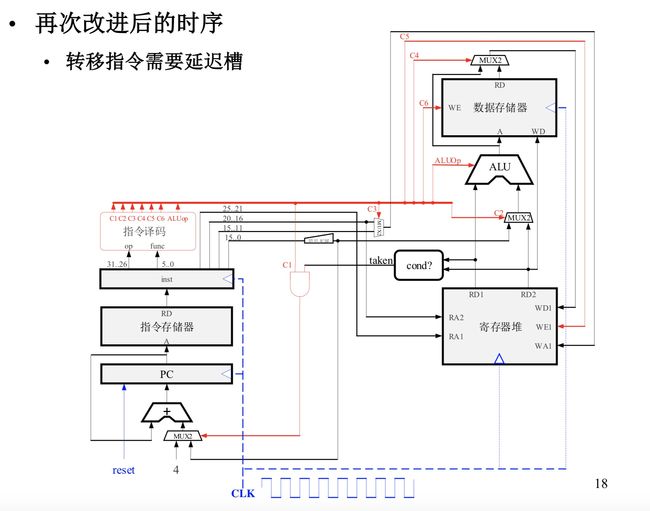
稍微解释一下CLK的连线,当时钟信号一来,第N+2条指令收到信号(信号传送到寄存器堆和内存)就开始执行阶段的任务(把结果写回寄存器堆或内存),第N+1条指令收到信号(信号传送到IR)就开始取指阶段的任务(CPU解析IR中的指令),第N条指令收到信号(信号传送到PC)开始计算PC阶段的任务。
其实,上述的重叠思想就是流水线设计思想,经过我们一步步的合并,现在这个CPU就能够正常的工作啦!但是,这种流水线的设计有一个问题,就是执行在执行阶段需要干的事情太多了!指令进入IR以后,要进行译码(生成各种控制信号C1,C2...),然后读寄存器的值,把值送到ALU,有时候还需要访存,最后还要把结果写回寄存器,上一步时钟信号把指令送到IR,要等很久的时间,才能发出下一个时钟信号把结果写回寄存器。。。
标准五级流水
既然,执行阶段要干的事情太多了,我们不如把执行阶段划分成若干个部分,这样就不用等太长时间了。按照上一节所说的任务,我们把执行阶段分成译码ID,执行EX,访存MEM,写回WB4个阶段。译码阶段就是分析这条指令要干什么事情,用到哪些寄存器,生成各种控制信号。执行阶段就是进行ALU运算。如果是一个访存操作,就根据算出来的地址访问数据存储器。最后,把结果写回到寄存器堆。这样的设计就是传统的RISC(
Reduced Instruction Set Computer) CPU设计中的标准五级流水线。
在标准五级流水线中,同时用五条指令在执行,每条执行所处的流水线阶段不一样,当然控制信号也不一样。所以需要在每个阶段设置中间寄存器来保存不同流水线阶段的数据。这个数据包括源寄存器的值,目标寄存器标号,以及各种控制信号。
在译码阶段,读出源寄存器的值以后,当时钟信号来以后需要将v1,v2(源寄存器值), ALUop(运算类型), c4(选择写回结果),c5(寄存器写使能),c6(数据存储器写使能),dest(目标寄存器地址)等数据保存到中间寄存器。其他阶段不在一一赘述。
现在,我们可以设计出标准的五级流水的CPU啦!效果如图所示。

指令相关和流水线冲突
指令相关
前面设计的五级流水使得CPU的主频大幅度提高,但是这样的CPU执行可能会导致错误的运行结果。为什么呢?举个例子,比如第N条指令把结果写到R1寄存器,第N+1条指令要用到R1的值进行运算。在五级流水中,第N条指令要在第五级才把结果写回到寄存器,而第N+1条指令要在第二级译码阶段就要把寄存器的值读出来。此时,第N条指令还没把R1写回,第N+1条指令就去读R1的值(旧值),这样就造成了运算结果的错误,这就是指令相关导致了执行结果错误。
指令相关分为三种:数据相关,控制相关以及结构相关。控制相关是指一条指令是否执行取决于转移指令的执行结果,在目前的设计中,我们利用延迟槽技术使控制相关得以解决。结构相关是指两条指令用了同一个功能部件,在目前的设计中,我们不用去考虑结构相关。最头疼的是数据相关了,数据相关是指两条指令访问了同一寄存器或内存单元,数据相关使得我们的执行结果出错,我们需要重新设计通路来解决这个问题。
先来看数据相关有哪些类型:1、RAW写后读相关,就是前面指令写一个寄存器后面指令读该寄存器值 2、WAR读后写相关,后面指令写一个寄存器前面指令读该寄存器的值3、WAW写后写相关,两条指令写同一个寄存器。在本CPU的五级流水中,不会引起后面两种相关:WAR前面指令读旧值,后面指令写旧值;WAW前面指令写旧值,后面指令写旧值。只会引起RAW相关,我们来举个数据相关的例子。
图中红线表示RAW相关,第一条指令要把结果写回寄存器,第2、3、4条指令要在ID开始阶段读该寄存器的值,按照目前的五级流水,第2、3、4指令会先于第1条指令读出结果,导致了结果错误。
流水线阻塞
对于上面说的情况,我们可以让第2条指令在译码阶段等待3拍,然后再去读寄存器的值,同样的,后面的3、4、5条指令也相应等待(由于流水线是有序的,所以第五条指令虽然没有数据相关,但是仍要等待)。我们称这种等待要流水线阻塞(STALL)。
那么,怎么找到RAW数据相关呢?其实很简单,在ID译码阶段,我们可以将处于该阶段的指令的rs,rt分别和处于EX,MEM,WB阶段的目标寄存器号dest进行相等比较,如果有一个相等,且该寄存器不是0号寄存器(默认0号寄存器的值恒等于0),这条指令不能前进。
那么,怎么才流水线阻塞呢?我们需要对PC和IR的输入使能进行控制,如果判断结果为1(相等且非0号寄存器),那么就让PC和IR保持当前的值不变(使能端输入0)。同时,让EX阶段的流水线输入指令无效信号,用流水线空泡填充(把0保存到中间寄存器),效果如图所示。
利用前递技术提高效率
前面,我们用阻塞技术来保证了流水线按规定的次序执行,但阻塞必然会引起流水线效率的降低,但其实我们可以通过硬件的方式来提高效率。
我们来回顾上一节的阻塞技术:由于存在数据相关,后面指令需要等待前面指令把值写回以后才能继续执行。那么,有没有可能前面指令结果算完以后不要写回,直接传给后面指令呢?比如,A从图书馆借了本书,B这时候也要借这本书,阻塞技术是说你等A把书还回图书馆后,B在去图书馆借。但我们现在希望A不要把书还给图书馆,直接把书给B不就行了吗?这种技术在流水线中就叫前递技术。
那么前递技术在硬件上要怎么实现呢?
设置ALU输入的3选1选择器
我们可以再原来的ALU每一个输入端增加了一个三选一选择器,三个输入分别是原来的ALU输入和下一级流水线的输出(EX的ALU运算结果)以及再下一级流水线的输出(MEM的结果),这样如果后面指令要用到前面指令的运算或者访存结果,就可以直接通过选择器直接选择前面指令的结果(中间寄存器保存着前面指令的数据),就不用等到结果写回寄存器再从寄存器中读值了。
设置选择器控制信号
那这个选择器的控制信号应该怎么设置呢?为了进行前递,我们需要比对处于EX级指令的源寄存器号和处于MEM或WB级指令的目标寄存器号是否相等,如果相等且不是0号寄存器,则说明处于EX流水线指令和前面的指令存在数据相关,那么直接读取前面指令的结果用于ALU的输入。值得注意的是,在原来的设计中,指令的源寄存器号是不用存在中间寄存器中的,使用前递技术后,需要把源寄存器号SRC1和SRC2传递到EX流水级中。
举个例子(以ALU左输入为例),当SRC1和DESTM(MEM级)、DESTW(WB级)都不相等时,选择中间通路,即正常ALU输入。当SRC1等于DESTW时,选择右边通路。当SRC1等于DESTM且在MEM级上是LOAD操作时,由于目标寄存器值还没有形成(上上条指令还没有执行MEM),所以流水线需要等一拍,后面的流水线暂停,往前面的流水线送空操作。
具体设计如图所示:
通过前递技术,COU流水线的效率又提高了很多。到目前为止,我们把CPU越做越复杂,但是效率越做越高。离完成我们的CPU越来越近了!
流水线的例外处理
到目前为止,我们几乎已经要完成了CPU的设计,回顾一下,我们已经完成了数据通路,控制通路,流水线等逻辑,看起来所以指令都在规规矩矩的执行。但我们忽略了一个大问题,例外!!(Exception,也叫异常)。举个简单的小例子,CPU在工作时,我们敲了一下键盘,CPU此时需要去响应敲键盘这个事件,而敲键盘就是我们说的例外。例外的发生是随机的,不可预测的,CPU不知道什么时候发生例外。比如这时候CPU在计算C=A+B时,突然来了例外,PC需要跳转到另外一个值去处理这个例外,当例外处理完以后,回来还需要继续算C=A+B,还得算对,就好像没发生过例外一样,所以需要保存现场。
发生例外时,硬件要保证发生例外的指令前面的所有指令都执行完了,后面的指令一条都没动。在流水线中多条指令同时发生例外的情况下,要保证有序的处理。
在五级流水线中,为了实现精确例外,我们可以在指令的执行过程中,把发生的例外先记录下来,到流水线的写回阶段再进行处理,这样就保证了前面的指令都执行完,后面的指令都没有修改机器的状态。
因为不知道例外什么时候到来,理论上什么时候处理都可以。所以我们可以再译码阶段对外部中断进行统一采样,然后随译码阶段的指令前进到写回时统一处理。
那么硬件上我们如何设计例外处理呢?1、首先我们需要保存例外信号(EX)以及发生例外时的指令PC,既然要到写回阶段才处理例外的话,我们需要在每一阶段的中间寄存器都保存这两个信号(增加EX项和PC项),用来记录发生的例外以及例外发生时指令的PC。2、在写回阶段处理例外时,我们需要保存发生例外的PC值。所以我们可以设置一个专门的寄存器EPC来保存该值,然后把PC置为处理该例外的程序的入口地址。3、在PC输入端,我们需要增加一个2选1选择器,一个是正常的PC值,另一个是例外处理程序的入口地址,由例外信号EX控制。
具体设计如图:
这个例外处理通路并不是一个完整的通路,它没有保存例外发生的原因,也没有例外返回时把EPC寄存器的值返还给PC的通路等。但操作系统只要知道发生例外的PC,就可以模拟指令执行知道发生例外的原因,还可以通过专用的指令修改PC的值等等做法来解决上述问题。
总结
一步一步,从无到右,从简单到复杂,现在,我们的CPU总算是设计好啦!回顾一下这个简单CPU设计的心路历程:首先我们从MIPS里选取了10几条指令构成了一个简单的指令系统,根据这个指令系统我们搭建了一条数据通路,在数据通路的基础上实现了控制逻辑,然后给CPU加上了时钟信号,在这个过程中,我们不断的将指令执行步骤重叠。之后为了提高效率,在此基础上,我们又将执行阶段细分,得到标准的五级流水,提高了主频。在五级流水中,由于数据相关的问题,使得程序执行可能出错,为了保证正确性,我们采用阻塞技术,阻塞引起相关的指令。之后为了提高流水线效率,我们又采用了前递技术,使得前面执行的结果直接传送给后面的指令。最后,我们实现了精确例外,让例外到流水线写回阶段统一处理。这个过程我们简化了很多步骤,真正的CPU远比这个复杂的多。但是我们的小型CPU,麻雀虽小五脏俱全。其实,每一步好好琢磨起来,整个过程并不是特别难!