职责链模式VS状态模式
今天来进行其他两个模式的对决,1号选手职责链模式,2号选手状态模式。开始对决:职责链模式VS状态模式。
首先来看看1号选手职责
链模式的简介,它的定义为:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这个对象连成一条链,并沿着这条链传递该请求,直到有一对象处理它为止。它的UML图如下:
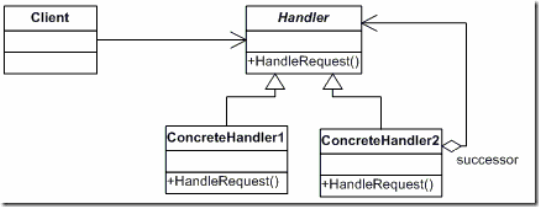
下面来看看1号选手职责链模式的好处:
当客户提交一个请求时,请求是沿链传递直至有一个ConcreteHander对象负责处理它。接收者和发送者都没有对方的明确信息,且链中的对象自己并不知道链的结构。结果是职责链可简化对象的相互连接,它们仅需保持一个指向其后继者的引用或指针,而不需要保持它所有的候选接受者。这也就大大降低了耦合度了。也就是说,我们可以随时地增加或修改处理一个请求的结构。增强了给对象指派职责的灵活性。不过在设计职责链时要当心,如果一个请求到了链的末端都得不到处理,或者因为没有正确配置而得不到处理,就很糟糕了。
同时由于职责链模式是把请求没链传递直到有一个ConcreteHander对象可以处理它,那么就可以消除程序中的大量的if...else...语句,以下是本人写的一个小例子:
#include
using namespace std;
class Handle
{
public:
void SetSuperior(Handle *p)
{
pHle = p;
}
virtual void HandleRequest(int key)=0;
virtual ~Handle(){}
protected:
Handle(){}
Handle *pHle;
};
class HandleA:public Handle //只能处理key<0的情况的能力
{
public:
virtual void HandleRequest(int key)
{
if(key < 0)
{
cout<<"the Request has Handle by HandleA key = "<
}
else
{
pHle->HandleRequest(key);
}
}
};
class HandleB:public Handle //只能处理key为0~2的情况
{
public:
virtual void HandleRequest(int key)
{
if(key >= 0&&key < 2)
{
cout<<"the Request has Handle by HandleB key = "<
}
else
{
pHle->HandleRequest(key);
}
}
};
class HandleC:public Handle //可以处理所有的请求
{
public:
virtual void HandleRequest(int key)
{
cout<<"the Request has Handle by HandleC key = "<
}
};
int main()
{
Handle *ha(new HandleA);
Handle *hb(new HandleB);
Handle *hc(new HandleC);
ha->SetSuperior(hb);
hb->SetSuperior(hc);
const int nmaxsize(5);
int nRequest[nmaxsize]={-1,-2,0,1,2};
for(int i = 0; i < nmaxsize; ++i)
{
ha->HandleRequest(nRequest[i]);
}
delete ha;
delete hb;
delete hc;
system("pause");
return 0;
}
由此可见,若不使用职责链模式,而把处理的代码写成一个类,则需要大量的if...else...来判断传入的参数的值(x<0,0<=x<2,x>=2),而且不易于维护,复用和扩展,一旦有新的请求就要修改类的代码,使类的结构变得复杂,也违反了开放-封闭原则。用职责链模式,则只需要为新的功能写成一个继承于Hande的子类并SetSuperor即可。
好了,看了1号选手介绍这么多,以下来看看2号选手
状态模式的介绍。
首先看看它的定义:当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变其类。以下是它的UML图:
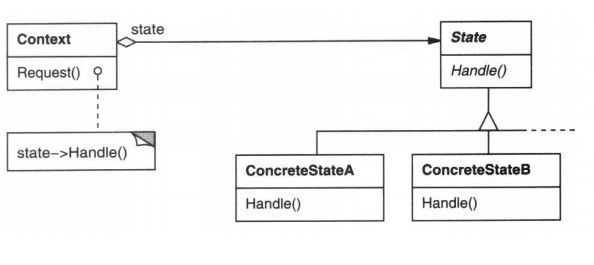
下面看看2号选手状态模式的好处和用处:
1、状态模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂的情况。把状态的判断逻辑转移到表示不同状态的一系列类当中,可以把复杂的判断逻辑简化。
2、状态模式将与特定状态相关的行为局部化,并且将不同状态的行为分割开来。即将特定的状态相关的行为都放入一个对象中,由于所有与状态相关的代码都存在于某个ConcreteState中,所以通过定义新的子类可以很容易地增加新的状态和转换。这样做的目的是为了消除庞大的条件分支语句。状态模式通过把各种状态转移逻辑分布到State的子类之间,来减少相互间的依赖。当一个对象的行为取决于它的状态,并且它必须在运行时根据状态改变它的行为时,就可以考虑使用状态模式。
以下是本人写的一个示例程序,与前面1号选手职责链模式的例子实现一样的功能。
#include
using namespace std;
class Context;
class State
{
public:
virtual void Handle(Context *pCnt, int flag)=0;
virtual ~State(){}
protected:
State(){}
};
class Context
{
public:
Context(State *p):pS(p){}
~Context(){}
void Request(int flag)
{
pS->Handle(this, flag);
}
void Set(State *p)
{
delete pS;
pS = p;
}
private:
State *pS;
};
class ConStateC:public State
{
public:
virtual void Handle(Context *pCnt, int flag)
{
cout<<"ConStateC flag = "<
}
};
class ConStateB:public State
{
public:
virtual void Handle(Context *pCnt, int flag)
{
if(flag >= 0&&flag < 2)
cout<<"ConStateB flag = "<
else
{
pCnt->Set(new ConStateC);
pCnt->Request(flag);
}
}
};
class ConStateA:public State
{
public:
virtual void Handle(Context *pCnt, int flag)
{
if(flag < 0)
cout<<"ConStateA flag = "<
else
{
pCnt->Set(new ConStateB);
pCnt->Request(flag);
}
}
};
int main()
{
ConStateA *pA(new ConStateA);
Context Cnt(pA); //用一个初始状态初始化Cnt
const int nmaxsize(5);
int nRequest[nmaxsize]={-1,-2,0,1,2};
for(int i = 0; i < nmaxsize; ++i)
{
Cnt.Request(nRequest[i]);
}
delete pA;
system("pause");
return 0;
}
若不使用状态模式,而把处理的代码写成一个类,则需要大量的if...else...来判断传入的参数的值(x<0,0<=x<2,x>=2),而且不易于维护,复用和扩展,一旦有新的请求就要修改类的代码,使类的结构变得复杂,也违反了开放-封闭原则。用状态模式,则只需要为新的功能写成一个继承于State的子类并在类内设好它的下一级即可即可。
总结:
由以上的解说和例子来看,这两个模式确实是非常相似,实力相当。那么它们有什么区别呢?
职责链模式:当客户提交一个请求时,请求是沿链传递直至有一个ConcreteHander对象负责处理它。接收者和发送者都没有对方的明确信息,且链中的对象自己并不知道链的结构,在运行时自动确定。结果是职责链可简化对象的相互连接,它们仅需保持一个指向其后继者的引用或指针,而不需要保持它所有的候选接受者。这也就大大降低了耦合度了。也就是说,我们可以随时地增加或修改处理一个请求的结构。增强了给对象指派职责的灵活性。
状态模式:状态模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂的情况。把状态的判断逻辑转移到表示不同状态的一系列类当中,可以把复杂的判断逻辑简化。状态模式将与特定状态相关的行为局部化,并且将不同状态的行为分割开来。即将特定的状态相关的行为都放入一个对象中,由于所有与状态相关的代码都存在于某个ConcreteState中,所以通过定义新的子类可以很容易地增加新的状态和转换。这样做的目的是为了消除庞大的条件分支语句。状态模式通过把各种状态转移逻辑分布到State的子类之间,来减少相互间的依赖。
个人认为,职责链模式与状态模式的最大的不同是设置自己的下一级的问题上,状态模式是在类的设计阶段就定好的,不能在客户端改变,而职责链的下一级是在客户端自己来确定的。这样各有什么优缺点呢?
在类的设计阶段设定(状态模式)的好处是不用客户来确定下一状态,也就减少了客户设置错误的问题,客户也不用知道状态的具体结构,同时存在灵活性差,耦合度高的问题,从上面的例子可以看到,因为作用域的问题,ConStateC一定要写在ConStateB之前,ConStateB一定要写在ConStateA之前,顺序不能乱。而在客户端设定(职责链模式)要求客户对各个类的职责要有所了解,并能正确设置好职责链,并加大设置出错的风险。但是它也比较灵活,也不存在刚才在状态模式中说的耦合和作用域问题。