Flume 概述及安装部署
1.概述
- Flume 定义
Flume 是Cloudera 提供的一个高可用,高可靠的,分布式的海量日志采集,聚合和传输的系统,Flume 基于流式构架,灵活简单。
- 为什么选用Flume
 它是一个基于流式的数据的非常简单的(就写一个配置文件就可以)、灵活的架构,它也是一个健壮的、容错的。它用一个简单的扩展数据模型用于在线实时应用分析。它的简单表现为:写个source、channel、sink,之后一条命令就能操作成功了。
它是一个基于流式的数据的非常简单的(就写一个配置文件就可以)、灵活的架构,它也是一个健壮的、容错的。它用一个简单的扩展数据模型用于在线实时应用分析。它的简单表现为:写个source、channel、sink,之后一条命令就能操作成功了。
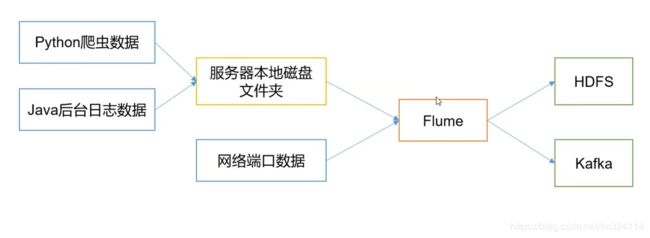
Flume 最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS中。
Flume、kafka实时进行数据收集,spark、storm实时去处理,impala实时去查询。
- Flume 构架
-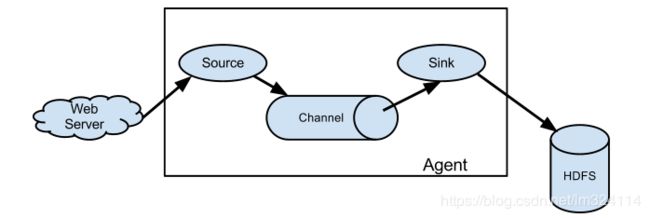
Agent:
由source、channel、sink组成,它是一个Jvm进程,它以事件的形式将数据从源头送至目的。
Source:
用于采集数据,Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel,它可以处理各种类型、各种格式的日志数据,包括avro,thrift,exec,jsms,netcat,http等
Channel:
连接 source 和 sink的数据传输通道
Sink:
从Channel收集数据,将数据写到目标源,可以是下一个Source也可以是HDFS或者HBase等
Event:
传输单元,以Event的形式将数据从源头送至目的地,Event 由Header 和Body 两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。
2.安装
到Flume官网上http://flume.apache.org/download.html下载软件安装包,如图: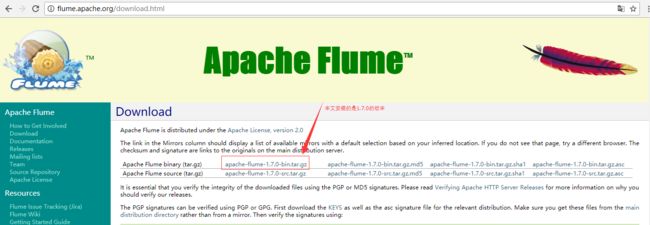
可以在Windows下下载完成,通过xftp上传至hadoop根目录下,也可以在图片上箭头指向的版本,点击“右键”,复制链接地址,在hadoop下通过wget安装
下载、解压
$ wget http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
$ tar -xzf apache-flume-1.7.0-bin.tar.gz
$ mv apache-flume-1.7.0-bin flume入到flume的conf下,创建一个flume.conf 文件
$ cd /home/hadoop/flume/conf/
$ vi flume.conf输入以下内容
# 指定Agent的组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 指定Flume source(要监听的路径)
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/log
# 指定Flume sink
a1.sinks.k1.type = logger
# 指定Flume channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 绑定source和sink到channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume agent
$ cd flume
$ bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console| 参数 | 作用 | 举例 |
|---|---|---|
| –conf 或 -c | 指定配置文件夹,包含flume-env.sh和log4j的配置文件 | –conf conf |
| –conf-file 或 -f | 配置文件地址 | –conf-file conf/flume.conf |
| –name 或 -n | agent名称 | –name a1 |
| -z | zookeeper连接字符串 | -z zkhost:2181,zkhost1:2181 |
| -p | zookeeper中的存储路径前缀 | -p /flume |
简单的操作
写入日志内容
在/home/hadoop/log 下创建一个flume.log 日志文件,写入hello flume 作为测试内容
$ cd /home/hadoop/log
$ vi flume.log接着就可以在前一个终端看到刚刚采集的内容了,如下:
2017-09-18 22:18:28,937 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 20 21 21 hello flume !! }
如图:![]()
至此flume已经能够正常运行。