使用python读取文件数据并转化为列表
使用python读取一些文件内容然后再用python帮助我们处理这些数据是节省时间提高效率一种方法。
比如我这里有有一段数据在文件processed.cleveland.data中:
63.0,1.0,1.0,145.0,233.0,1.0,2.0,150.0,0.0,2.3,3.0,0.0,6.0,0
67.0,1.0,4.0,160.0,286.0,0.0,2.0,108.0,1.0,1.5,2.0,3.0,3.0,2
67.0,1.0,4.0,120.0,229.0,0.0,2.0,129.0,1.0,2.6,2.0,2.0,7.0,1
37.0,1.0,3.0,130.0,250.0,0.0,0.0,187.0,0.0,3.5,3.0,0.0,3.0,0
41.0,0.0,2.0,130.0,204.0,0.0,2.0,172.0,0.0,1.4,1.0,0.0,3.0,0
56.0,1.0,2.0,120.0,236.0,0.0,0.0,178.0,0.0,0.8,1.0,0.0,3.0,0
…
废话不多说,直接展示一些代码。
#首先找到需要读取的文件目录,绝对路径或者相对路径均可
filename = r"processed.cleveland.data"
#先声明一下a
a=[]
try:
#打开文件
fp=open(filename,"r")
print('%s 文件打开成功' % filename)
for line in fp.readlines():
'''
当你读取文件数据时会经常遇见一种问题,
那就是每行数据末尾都会多个换行符‘\n’,
所以我们需要先把它们去掉
'''
line=line.replace('\n','')
#或者line=line.strip('\n')
#但是这种只能去掉两头的,可以根据情况选择使用哪一种
line=line.split(',')
#以逗号为分隔符把数据转化为列表
a.append(line)
fp.close()
print("文件内容为:")
print(a)
except IOError:
print("文件打开失败,%s文件不存在" % filename)
下面就是输出结果了
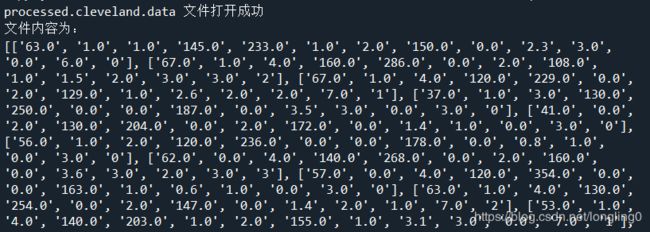
可以看到,数据已经转化为一段二层列表了,每一行以一个小列表,再存储到一个大列表中。接下来进行其他操作就可以直接对这个列表进行处理了