收缩SQL数据库日志文件
--压缩日志及数据库文件大小
/*--特别注意
请按步骤进行,未进行前面的步骤,请不要做后面的步骤
否则可能损坏你的数据库.
一般不建议做第4,6两步
第4步不安全,有可能损坏数据库或丢失数据
第6步如果日志达到上限,则以后的数据库处理会失败,在清理日志后才能恢复.
--*/
--下面的所有库名都指你要处理的数据库的库名
1.清空日志
DUMP TRANSACTION 库名 WITH NO_LOG
2.截断事务日志:
BACKUP LOG 库名 WITH NO_LOG
3.收缩数据库文件(如果不压缩,数据库的文件不会减小
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩文件
--选择日志文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
--选择数据文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
也可以用SQL语句来完成
--收缩数据库
DBCC SHRINKDATABASE(库名)
--收缩指定数据文件,1是文件号,可以通过这个语句查询到:select * from sysfiles
DBCC SHRINKFILE(1)
4.为了最大化的缩小日志文件(如果是sql 7.0,这步只能在查询分析器中进行)
a.分离数据库:
企业管理器--服务器--数据库--右键--分离数据库
b.在我的电脑中删除LOG文件
c.附加数据库:
企业管理器--服务器--数据库--右键--附加数据库
此法将生成新的LOG,大小只有500多K
或用代码:
下面的示例分离 pubs,然后将 pubs 中的一个文件附加到当前服务器。
a.分离
EXEC sp_detach_db @dbname = '库名'
b.删除日志文件
c.再附加
EXEC sp_attach_single_file_db @dbname = '库名',
@physname = 'c:/Program Files/Microsoft SQL Server/MSSQL/Data/库名.mdf'
5.为了以后能自动收缩,做如下设置:
企业管理器--服务器--右键数据库--属性--选项--选择"自动收缩"
--SQL语句设置方式:
EXEC sp_dboption '库名', 'autoshrink', 'TRUE'
6.如果想以后不让它日志增长得太大
企业管理器--服务器--右键数据库--属性--事务日志
--将文件增长限制为xM(x是你允许的最大数据文件大小)
--SQL语句的设置方式:
alter database 库名 modify file(name=逻辑文件名,maxsize=20)
2 楼wgy2008(北极光)
use master --注意,此存储过程要建在master数据库中
go
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[p_compdb]') and OBJECTPROPERTY(id, N'IsProcedure') = 1)
drop procedure [dbo].[p_compdb]
GO
/*--压缩数据库的通用存储过程
压缩日志及数据库文件大小
因为要对数据库进行分离处理
所以存储过程不能创建在被压缩的数据库中
/*--调用示例
exec p_compdb 'test'
--*/
create proc p_compdb
@dbname sysname, --要压缩的数据库名
@bkdatabase bit=1, --因为分离日志的步骤中,可能会损坏数据库,所以你可以选择是否自动数据库
@bkfname nvarchar(260)='' --备份的文件名,如果不指定,自动备份到默认备份目录,备份文件名为:数据库名+日期时间
as
if @bkdatabase=1 --确定是否备份数据库
begin
if isnull(@bkfname,'')=''
set @bkfname=@dbname+'_'+convert(varchar,getdate(),112)
+replace(convert(varchar,getdate(),108),':','')
select 提示信息='备份数据库到SQL 默认备份目录,备份文件名:'+@bkfname
exec('backup database ['+@dbname+'] to disk='''+@bkfname+'''')
end
--1.清空日志
exec('DUMP TRANSACTION ['+@dbname+'] WITH NO_LOG')
--2.截断事务日志:
exec('BACKUP LOG ['+@dbname+'] WITH NO_LOG')
--3.收缩数据库文件(如果不压缩,数据库的文件不会减小
exec('DBCC SHRINKDATABASE(['+@dbname+'])')
--4.设置自动收缩
--exec('EXEC sp_dboption '''+@dbname+''',''autoshrink'',''TRUE''')
/*--后面的步骤有一定危险,如果你无法确定它的危险性,请勿启用,而且会断开用户连接
--5.分离数据库
--进行分离处理
create table #t(fname nvarchar(260),type int)
exec('insert into #t select filename,type=status&0x40 from ['+@dbname+']..sysfiles')
exec('sp_detach_db '''+@dbname+'''')
--删除日志文件
declare @fname nvarchar(260),@s varchar(8000)
declare tb cursor local for select fname from #t where type=64
open tb
fetch next from tb into @fname
while @@fetch_status=0
begin
set @s='del "'+rtrim(@fname)+'"'
exec master..xp_cmdshell @s,no_output
fetch next from tb into @fname
end
close tb
deallocate tb
--附加数据库
set @s=''
declare tb cursor local for select fname from #t where type=0
open tb
fetch next from tb into @fname
while @@fetch_status=0
begin
set @s=@s+','''+rtrim(@fname)+''''
fetch next from tb into @fname
end
close tb
deallocate tb
exec('sp_attach_single_file_db '''+@dbname+''''+@s)
--*/
go
--还不行,就关闭用户打开的进程处理,在查询分析器中执行下面的语句
use master
go
if exists (select * from dbo.sysobjects where id = object_id(N '[dbo].[p_killspid] ') and OBJECTPROPERTY(id, N 'IsProcedure ') = 1)
drop procedure [dbo].[p_killspid]
GO
create proc p_killspid
@dbname varchar(200) --要关闭进程的数据库名
as
declare @sql nvarchar(500)
declare @spid nvarchar(20)
declare #tb cursor for
select spid=cast(spid as varchar(20)) from master..sysprocesses where dbid=db_id(@dbname)
open #tb
fetch next from #tb into @spid
while @@fetch_status=0
begin
exec( 'kill '+@spid)
fetch next from #tb into @spid
end
close #tb
deallocate #tb
go
--用法
exec p_killspid 'statmemberdata '
go
DBCC SHRINKDATABASE (statmemberdata)
go
drop proc p_killspid
1.打开企业管理器,找到要压缩的数据库,右键并点“属性”
2.选择“选项”然后把故障还原模式改为“简单”点“确定”
//看看其他选项就知道,为什么要这么做了吧^^
//也可以先不执行这步,然后执行第3步,就可以对比了
3.选中要压缩的数据库,右键并选“所有任务”点“收缩数据库”然后点“确定”
//这个时候看看数据库日志文件是不是还原成最初大小了?还没完
4.重复第1步,在选项里把故障还原模式改回为“完全”点“确定”
//这个步骤不要忘了,否则,遇到问题就麻烦了,呵呵。
解决SQL Server占用内存过多的问题
SQL Server最大的开销一般是用于数据缓存,如果内存足够,它会把用过的数据和觉得你会用到的数据统统扔到内存中,直到内存不足的时候,才把命中率低的数据给清掉……
经常看见有人问,MSSQL占用了太多的内存,而且还不断的增长;或者说已经设置了使用内存,可是它没有用到那么多,这是怎么一回事儿呢?
首先,我们来看看MSSQL是怎样使用内存的。
最大的开销一般是用于数据缓存,如果内存足够,它会把用过的数据和觉得你会用到的数据统统扔到内存中,直到内存不足的时候,才把命中率低的数据给清掉。所以一般我们在看statistics io的时候,看到的physics read都是0。
其次就是查询的开销,一般地说,hash join是会带来比较大的内存开销的,而merge join和nested loop的开销比较小,还有排序和中间表、游标也是会有比较大的开销的。
所以用于关联和排序的列上一般需要有索引。
再其次就是对执行计划、系统数据的存储,这些都是比较小的。
我们先来看数据缓存对性能的影响,如果系统中没有其它应用程序来争夺内存,数据缓存一般是越多越好,甚至有些时候我们会强行把一些数据pin在高速缓存中。但是如果有其它应用程序,虽然在需要的时候MSSQL会释放内存,但是线程切换、IO等待这些工作也是需要时间的,所以就会造成性能的降低。这样我们就必须设置MSSQL的最大内存使用。可以在SQL Server 属性(内存选项卡)中找到配置最大使用内存的地方,或者也可以使用sp_configure来完成。如果没有其它应用程序,那么就不要限制MSSQL对内存的使用。
然后来看查询的开销,这个开销显然是越低越好,因为我们不能从中得到好处,相反,使用了越多的内存多半意味着查询速度的降低。所以我们一般要避免中间表和游标的使用,在经常作关联和排序的列上建立索引。
|
微软的Empty.exe可以用来释放某些应用程序在占用大量内存时不能及时释放的那部分资源,与那些第三方软件内存管理软件不同的是,Empty.exe不会强迫系统全部释放资源,而是仅仅释放必要的资源,这样就不会加重硬盘的负担了。
@Echo ====================内存开始释放==================== @Rem 释放.Net空闲内存 @Rem 释放QQ空闲内存 @Rem 释放SQL管理的空闲内存 @Rem 释放SQl的空闲内存 @Rem 释放查询分析器的空闲内存 @Rem 释放MyIE的空闲内存 @Rem 释放共享神盾的空闲内存 @Rem 释放酷狗的空闲内存 @Rem 释放腾讯TT的空闲内存 @Rem 释放网络电视播放PPStream的空闲内存 @Rem 释放系统常见的空闲内存 @Rem 看之前有没有把===内存释放.exe===这个程序放在System32文件夹下,如果有的话,就可以直接把这个===内存释放.exe===写出来。 可以把上面的内存开始释放开始到内存释放结束这段代码复制下来,把它放在记事本中,然后把记事本的后缀改作批处理的后缀bat格式。(批处理名称任意,只要符合文件名称即可)或者可以根据自己系统中的进程列表的所有进程名都放在内存开始释放至内存释放结束中间。(有的人会说如QQ这个进程,我已经把它放在这个批处理中,但还没开QQ,会不会有什么问题呢?答案是不会的,它批处理执行的速度是很快的,它也只是提示找不到这个进程名,就像在命令窗口中乱输几个字,只是提示输错等之类的。批处理在执行的话,有提示错误信息也是闪一下就跳过,不会对系统产生影响。) 即然这个批处理已经建好了,肯定不能让我们手动每隔一段时间去运行它。那样的话,就不够智能化了。这样就需要系统自带的任务计划: 


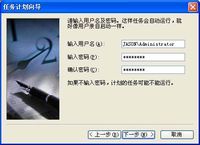
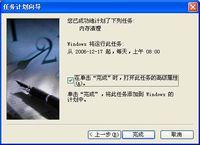
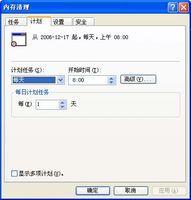
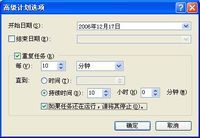
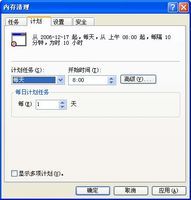
|
压缩数据库
dbcc shrinkdatabase(dbname)
压缩日志
SET NOCOUNT ON
DECLARE @LogicalFileName sysname,
@MaxMinutes INT,
@NewSize INT
USE Marias -- 要操作的数据库名
SELECT @LogicalFileName = 'Marias_log', -- 日志文件名
@MaxMinutes = 10, -- Limit on time allowed to wrap log.
@NewSize = 100 -- 你想设定的日志文件的大小(M)
-- Setup / initialize
DECLARE @OriginalSize int
SELECT @OriginalSize = size
FROM sysfiles
WHERE name = @LogicalFileName
SELECT 'Original Size of ' + db_name() + ' LOG is ' +
CONVERT(VARCHAR(30),@OriginalSize) + ' 8K pages or ' +
CONVERT(VARCHAR(30),(@OriginalSize*8/1024)) + 'MB'
FROM sysfiles
WHERE name = @LogicalFileName
CREATE TABLE DummyTrans
(DummyColumn char (8000) not null)
DECLARE @Counter INT,
@StartTime DATETIME,
@TruncLog VARCHAR(255)
SELECT @StartTime = GETDATE(),
@TruncLog = 'BACKUP LOG ' + db_name() + ' WITH TRUNCATE_ONLY'
DBCC SHRINKFILE (@LogicalFileName, @NewSize)
EXEC (@TruncLog)
-- Wrap the log if necessary.
WHILE @MaxMinutes > DATEDIFF (mi, @StartTime, GETDATE()) -- time has not expired
AND @OriginalSize = (SELECT size FROM sysfiles WHERE name = @LogicalFileName)
AND (@OriginalSize * 8 /1024) > @NewSize
BEGIN -- Outer loop.
SELECT @Counter = 0
WHILE ((@Counter < @OriginalSize / 16) AND (@Counter < 50000))
BEGIN -- update
INSERT DummyTrans valueS ('Fill Log')
DELETE DummyTrans
SELECT @Counter = @Counter + 1
END
EXEC (@TruncLog)
END
SELECT 'Final Size of ' + db_name() + ' LOG is ' +
CONVERT(VARCHAR(30),size) + ' 8K pages or ' +
CONVERT(VARCHAR(30),(size*8/1024)) + 'MB'
FROM sysfiles
WHERE name = @LogicalFileName
DROP TABLE DummyTrans
SET NOCOUNT OFF
在2000下亦如此, 有时是不可能一次性压缩到的, 要多做几次,一般每次都会压缩一部分,最后可以把日志文件压缩到1M
//2.建立个job每天导出日志(job里的sql语句如何写)
exec 存儲過程名
具體如下:
企业管理器中,管理——》SQL SERVER代理——》作业——》鼠标右键新建作业——》常规页中输入名称——》步骤页中新建步骤、输入名称、加入更新一条纪录的SQL语句——》调度页中新建调度、输入名称,选择反复出现,更改时间——》OK
use master --注意,此存储过程要建在master数据库中
go
if exists (select * from dbo.sysobjects where id = object_id(N '[dbo].[p_compdb] ') and OBJECTPROPERTY(id, N 'IsProcedure ') = 1)
drop procedure [dbo].[p_compdb]
GO
/*--压缩数据库的通用存储过程
压缩日志及数据库文件大小
因为要对数据库进行分离处理
所以存储过程不能创建在被压缩的数据库中
/*--调用示例
exec p_compdb 'test '
--*/
create proc p_compdb
@dbname sysname, --要压缩的数据库名
@bkdatabase bit=1, --因为分离日志的步骤中,可能会损坏数据库,所以你可以选择是否自动数据库
@bkfname nvarchar(260)= ' ' --备份的文件名,如果不指定,自动备份到默认备份目录,备份文件名为:数据库名+日期时间
as
if @bkdatabase=1 --确定是否备份数据库
begin
if isnull(@bkfname, ' ')= ' '
set @bkfname=@dbname+ '_ '+convert(varchar,getdate(),112)
+replace(convert(varchar,getdate(),108), ': ', ' ')
select 提示信息= '备份数据库到SQL 默认备份目录,备份文件名: '+@bkfname
exec( 'backup database [ '+@dbname+ '] to disk= ' ' '+@bkfname+ ' ' ' ')
end
--1.清空日志
exec( 'DUMP TRANSACTION [ '+@dbname+ '] WITH NO_LOG ')
--2.截断事务日志:
exec( 'BACKUP LOG [ '+@dbname+ '] WITH NO_LOG ')
--3.收缩数据库文件(如果不压缩,数据库的文件不会减小
exec( 'DBCC SHRINKDATABASE([ '+@dbname+ ']) ')
--4.设置自动收缩
--exec( 'EXEC sp_dboption ' ' '+@dbname+ ' ' ', ' 'autoshrink ' ', ' 'TRUE ' ' ')
/*--后面的步骤有一定危险,如果你无法确定它的危险性,请勿启用,而且会断开用户连接
--5.分离数据库
--进行分离处理
create table #t(fname nvarchar(260),type int)
exec( 'insert into #t select filename,type=status&0x40 from [ '+@dbname+ ']..sysfiles ')
exec( 'sp_detach_db ' ' '+@dbname+ ' ' ' ')
--删除日志文件
declare @fname nvarchar(260),@s varchar(8000)
declare tb cursor local for select fname from #t where type=64
open tb
fetch next from tb into @fname
while @@fetch_status=0
begin
set @s= 'del " '+rtrim(@fname)+ ' " '
exec master..xp_cmdshell @s,no_output
fetch next from tb into @fname
end
close tb
deallocate tb
--附加数据库
set @s= ' '
declare tb cursor local for select fname from #t where type=0
open tb
fetch next from tb into @fname
while @@fetch_status=0
begin
set @s=@s+ ', ' ' '+rtrim(@fname)+ ' ' ' '
fetch next from tb into @fname
end
close tb
deallocate tb
exec( 'sp_attach_single_file_db ' ' '+@dbname+ ' ' ' '+@s)
--*/
go
当使用 ALTER DATABASE AUTO_SHRINK 选项(或 sp_dboption 系统存储过程)将数据库设置为自动收缩,且数据库中有足够的可用空间时,则会发生收缩。但是,如果不能配置要删除的可用空间的百分比,则将删除尽可能多的可用空间。若要配置将删除的可用空间量,例如只删除数据库中当前可用空间的 50%,请使用SQL Server 企业管理器内的 "属性 "对话框进行数据库收缩。
不能将整个数据库收缩到比其原始大小还要小。因此,如果数据库创建时的大小为 10 MB,后来增长到 100 MB,则该数据库最小能够收缩到 10 MB(假定已经删除该数据库中所有数据)。
但是,使用 DBCC SHRINKFILE 语句,可以将单个数据库文件收缩到比其初始创建大小还要小。必须分别收缩每个文件,而不要试图收缩整个数据库。
事务日志文件可在固定的边界内收缩。虚拟日志的大小决定可能减小的大小。因此,不能将日志文件收缩到比虚拟日志文件还小。另外,日志文件可以按与虚拟日志文件的大小相等的增量收缩。例如,一个初始大小为 1 GB 的较大事务日志文件可以包括五个虚拟日志文件(每个文件大小为 200 MB)。收缩事务日志文件将删除未使用的虚拟日志文件,但会留下至少一个虚拟日志文件。因为此示例中的每个虚拟日志文件都是 200 MB,所以事务日志最小只能收缩到 200 MB,且每次只能以 200 MB的大小收缩。若要让事务日志文件收缩得更小,可以创建一个更小的事务日志,并允许它自动增长,而不要创建一个较大的事务日志文件。
在 SQL Server 2000 中,DBCC SHRINKDATABASE 或 DBCC SHRINKFILE 操作试图立即将事务日志文件收缩到所要求的大小(以四舍五入的值为准)。在收缩文件之前应截断日志文件,以减小逻辑日志的大小并将其标记为不包含逻辑日志任何部分的不活动的虚拟日志。有关更多信息,请参见收缩事务日志。
多处转载, 这里就不附上网址