用DCGAN训练自己的数据集
第一步:读入数据
import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt
import pdb
def get_files(file_dir):
img=[]
label=[]
for file in os.listdir(file_dir):
img.append(file_dir+file)
label.append(1)
temp=np.array([img,label]).T
#使用shuffle打乱顺序
np.random.shuffle(temp)
img_list=list(temp[:,0])
label_list=list(temp[:,1])
label_list=[int(i) for i in label_list]
return img_list,label_list第二步:将上述的list产生训练的批次
tensorflow为了充分利用CPU和GPU,减少CPU或者GPU等待数据的空闲时间,使用两个线程分别执行数据的读入和数据的计算。即用一个线程源源不断地从硬盘中读取图像数据到内存队列,另一个线程负责计算任务,所需的数据直接从内存队列中获取。tensorflow在内存队列之前还设置了文件名队列,文件名队列存放参与训练的文件名,要训练N个epoch,则文件名队列中就含有N个批次的所有文件名,如图所示。
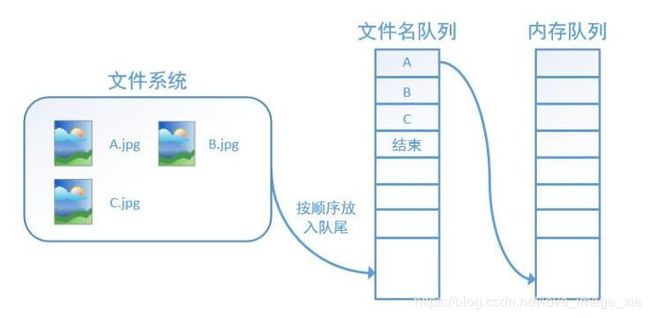
在N个epoch的文件名后是一个结束标志,当tensorflow捕捉到结束标志时会抛出一个OutofRange的异常,外部捕捉到这个异常后就结束程序。
input_queue=tf.train.slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None, capacity=32, shared_name=None,name=None)是一个tensor生成器,每次从一个tensor列表中抽取一个tensor放入文件名队列。需要调用tf.train.start_queue_runners启动执行文件名队列填充的线程,之和计算单元才会把数据读出来,否则文件名队列是空的,计算单元会一直处于等待状态
tensor_list: 输入,有多少图像该参数第一维就有多少;若tensor_list=[image,label],则input_queue[1]代表标签,input_quue[0]代表图像,需要通过tf.read_file(input_queue[0])输出图像
num_epochs: 迭代次数,设置为None代表可以无限次地遍历tensor列表,若设置为N,则只能遍历N次;
shuffle: 是否打乱样本的顺序;
seed: 生成随机数的种子,在shuffle为True时才有用;
capacity: 代表tensor列表容量
shared_name: 如果设置一个shared_name,可在不同的Session中可通过这个名字共享生成的tensor;
name: 设置操作的名字
tf.train.batch(tensors, batch_size, num_threads=1, capacity=32, ...)
tf.train.shuffle_batch(tensors, batch_size, num_threads=1, capacity=32, min_after_dequeue,...)
这两个函数用来生成批次数据
则生成批次数据code如下:
def get_batch(image,label,batch_size):
image_W=200
image_H=200
#将python中的list类型转换为tf能识别的格式
image=tf.cast(image,tf.string)
label=tf.cast(label,tf.int32)
#产生一个输入队列queue
epoch_num=50
input_queue=tf.train.slice_input_producer([image,label],num_epochs=epoch_num)
label=input_queue[1]
image_contents=tf.read_file(input_queue[0])
#将图像解码,不同类型的图像不能混在一起
#生成batch
image = tf.image.decode_bmp(image_contents, channels=1)
min_after_dequeue=10
image = tf.image.resize_image_with_crop_or_pad(image, image_W, image_H)
capacity=min_after_dequeue+3*batch_size
image_batch, label_batch = tf.train.shuffle_batch([image, label], batch_size=batch_size,num_threads=1024,capacity=capacity,min_after_dequeue=min_after_dequeue)
#重新排列标签,行数为[batch_size]
image_batch=tf.reshape(image_batch,[batch_size,image_W,image_H,1])
image_batch=tf.cast(image_batch,np.float32)
return image_batch,label_batch第一步和第二步的code放在一起,叫data_generator.py
第三步:建立判别器和生成器模型 model.py
import tensorflow as tf
import numpy as np
import datetime
import pdb
import matplotlib.pyplot as plt
# Define the generator network
def generator(z, batch_size, z_dim):
g_w1 = tf.get_variable('g_w1', [z_dim, 40000], dtype=tf.float32, initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b1 = tf.get_variable('g_b1', [40000], initializer=tf.truncated_normal_initializer(stddev=0.02))
g1 = tf.matmul(z, g_w1) + g_b1
g1 = tf.reshape(g1, [-1, 200, 200, 1])
g1 = tf.contrib.layers.batch_norm(g1, epsilon=1e-5, scope='g_b1')
g1 = tf.nn.relu(g1)
# Generate 50 features
g_w2 = tf.get_variable('g_w2', [3, 3, 1, z_dim/2], dtype=tf.float32, initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b2 = tf.get_variable('g_b2', [z_dim/2], initializer=tf.truncated_normal_initializer(stddev=0.02))
g2 = tf.nn.conv2d(g1, g_w2, strides=[1, 2, 2, 1], padding='SAME')
g2 = g2 + g_b2
g2 = tf.contrib.layers.batch_norm(g2, epsilon=1e-5, scope='g_b2')
g2 = tf.nn.relu(g2)
g2 = tf.image.resize_images(g2, [200, 200])
# Generate 25 features
g_w3 = tf.get_variable('g_w3', [3, 3, z_dim/2, z_dim/4], dtype=tf.float32, initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b3 = tf.get_variable('g_b3', [z_dim/4], initializer=tf.truncated_normal_initializer(stddev=0.02))
g3 = tf.nn.conv2d(g2, g_w3, strides=[1, 2, 2, 1], padding='SAME')
g3 = g3 + g_b3
g3 = tf.contrib.layers.batch_norm(g3, epsilon=1e-5, scope='g_b3')
g3 = tf.nn.relu(g3)
g3 = tf.image.resize_images(g3, [200, 200])
# Final convolution with one output channel
g_w4 = tf.get_variable('g_w4', [1, 1, z_dim/4, 1], dtype=tf.float32, initializer=tf.truncated_normal_initializer(stddev=0.02))
g_b4 = tf.get_variable('g_b4', [1], initializer=tf.truncated_normal_initializer(stddev=0.02))
g4 = tf.nn.conv2d(g3, g_w4, strides=[1, 2, 2, 1], padding='SAME')
g4 = g4 + g_b4
g4 = tf.sigmoid(g4)
# Dimensions of g4: batch_size x 28 x 28 x 1
return g4
# Define the discriminator network
def discriminator(images, reuse_variables=None):
with tf.variable_scope(tf.get_variable_scope(), reuse=reuse_variables) as scope:
# First convolutional and pool layers
# This finds 32 different 5 x 5 pixel features
d_w1 = tf.get_variable('d_w1', [5, 5, 1, 32], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b1 = tf.get_variable('d_b1', [32], initializer=tf.constant_initializer(0))
d1 = tf.nn.conv2d(input=images, filter=d_w1, strides=[1, 1, 1, 1], padding='SAME')
d1 = d1 + d_b1
d1 = tf.nn.relu(d1)
d1 = tf.nn.avg_pool(d1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# Second convolutional and pool layers
# This finds 64 different 5 x 5 pixel features
d_w2 = tf.get_variable('d_w2', [5, 5, 32, 64], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b2 = tf.get_variable('d_b2', [64], initializer=tf.constant_initializer(0))
d2 = tf.nn.conv2d(input=d1, filter=d_w2, strides=[1, 1, 1, 1], padding='SAME')
d2 = d2 + d_b2
d2 = tf.nn.relu(d2)
d2 = tf.nn.avg_pool(d2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
#pdb.set_trace()
# First fully connected layer
d_w3 = tf.get_variable('d_w3', [10 * 10 * 64, 1024], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b3 = tf.get_variable('d_b3', [1024], initializer=tf.constant_initializer(0))
d3 = tf.reshape(d2, [-1, 10 * 10 * 64])
d3 = tf.matmul(d3, d_w3)
d3 = d3 + d_b3
d3 = tf.nn.relu(d3)
# Second fully connected layer
d_w4 = tf.get_variable('d_w4', [1024, 1], initializer=tf.truncated_normal_initializer(stddev=0.02))
d_b4 = tf.get_variable('d_b4', [1], initializer=tf.constant_initializer(0))
d4 = tf.matmul(d3, d_w4) + d_b4
# d4 contains unscaled values
return d4
第四步:训练 train.py
import tensorflow as tf
import numpy as np
import model
import data_generate
import datetime
import matplotlib.pyplot as plt
import pdb
file_dir='E:\\Users\\Administrator\\PycharmProjects\\GAN\\patch_data\\'
batch_size=20
image_W=200
image_H=200
z_dimensions=100
image_list, label_list = data_generate.get_files(file_dir)
image_batch, _ = data_generate.get_batch(image_list, label_list, batch_size)
z_placeholder = tf.placeholder(tf.float32, [None, z_dimensions], name='z_placeholder')
#x_placeholder = tf.placeholder(tf.float32, shape=[None, 28, 28, 1], name='x_placeholder')
x_placeholder=image_batch
Gz = model.generator(z_placeholder, batch_size, z_dimensions)
Dx = model.discriminator(x_placeholder)
Dg = model.discriminator(Gz, reuse_variables=True)
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dx, labels=tf.ones_like(Dx)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dg, labels=tf.zeros_like(Dg)))
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dg, labels=tf.ones_like(Dg)))
# Define variable lists
tvars = tf.trainable_variables() #获取网络全部可训练参数
d_vars = [var for var in tvars if 'd_' in var.name] #判别器的参数
g_vars = [var for var in tvars if 'g_' in var.name] #生成器的参数
d_trainer_fake = tf.train.AdamOptimizer(0.0003).minimize(d_loss_fake, var_list=d_vars)
d_trainer_real = tf.train.AdamOptimizer(0.0003).minimize(d_loss_real, var_list=d_vars)
g_trainer = tf.train.AdamOptimizer(0.0001).minimize(g_loss, var_list=g_vars)
tf.get_variable_scope().reuse_variables()
sess = tf.Session()
iterations=10000
with tf.Session() as sess:
#变量初始化放入session中
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
i=0
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(sess,coord)
try:
while not coord.should_stop() and i0 and i % 9999 == 0:
# Every 100 iterations, show a generated image
print("Iteration:", i, "at", datetime.datetime.now())
z_batch = np.random.normal(0, 1, size=[1, z_dimensions])
generated_images = model.generator(z_placeholder, 1, z_dimensions)
images = sess.run(generated_images, {z_placeholder: z_batch})
#pdb.set_trace()
plt.imshow(images[0].reshape([100, 100]), cmap='Greys')
plt.show()
# Show discriminator's estimate
'''
im = images[0].reshape([1, 100, 100, 1])
result = discriminator(x_placeholder)
estimate = sess.run(result, {x_placeholder: im})
print("Estimate:", estimate)
'''
i = i + 1
except tf.errors.OutOfRangeError:
print('done')
finally:
coord.request_stop()
print('...............')
coord.join(threads)
第五步:调试错误分析
1、#tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value input_producer/input_producer/limit_epochs/epochs
#[[Node: input_producer/input_producer/limit_epochs/CountUpTo = CountUpTo[T=DT_INT64, _class=["loc:@input_producer/input_producer/limit_epochs/epochs"], limit=50, _device="/job:localhost/replica:0/task:0/device:CPU:0"](input_producer/input_producer/limit_epochs/epochs)]]
解决方法:将初始化全局变量和局部变量放在session内
2、 #TypeError: The value of a feed cannot be a tf.Tensor object. Acceptable feed values include Python scalars, strings, lists, numpy ndarrays, or TensorHandles.For reference,
#the tensor object was Tensor("Cast_2:0", shape=(20, 200, 200, 1), dtype=float32) which was passed to the feed with key Tensor("x_placeholder:0", shape=(?, 28, 28, 1), dtype=float32).
#将image_batch改为image_batch.reshape([batch_size, image_H,image_W , 1])
解决方法:
刚开始是这样写的:
_, __, dLossReal, dLossFake = sess.run([d_trainer_real, d_trainer_fake, d_loss_real, d_loss_fake],
{x_placeholder:image_batch,z_placeholder: z_batch})
问题的意思是给x_placeholder喂的tensor不对,因为在data_generator.py中 添加 image_batch=tf.reshape(image_batch,[batch_size,image_W,image_H,1]),使image_batch确定形状,我之前给x_placeholder输入的tensor类型和image_W,image_H不一致导致错误
3、Traceback (most recent call last):
File "E:\Users\Administrator\PycharmProjects\GAN\train.py", line 59, in
{x_placeholder: image_batch[0].reshape([batch_size, image_H,image_W , 1]), z_placeholder: z_batch})
AttributeError: 'Tensor' object has no attribute 'reshape'
解决方法:要在data_generator.py中添加 image = tf.image.resize_image_with_crop_or_pad(image, image_W, image_H),将图像reshape一下,在此处就可以直接用x_placeholder:image_batch